

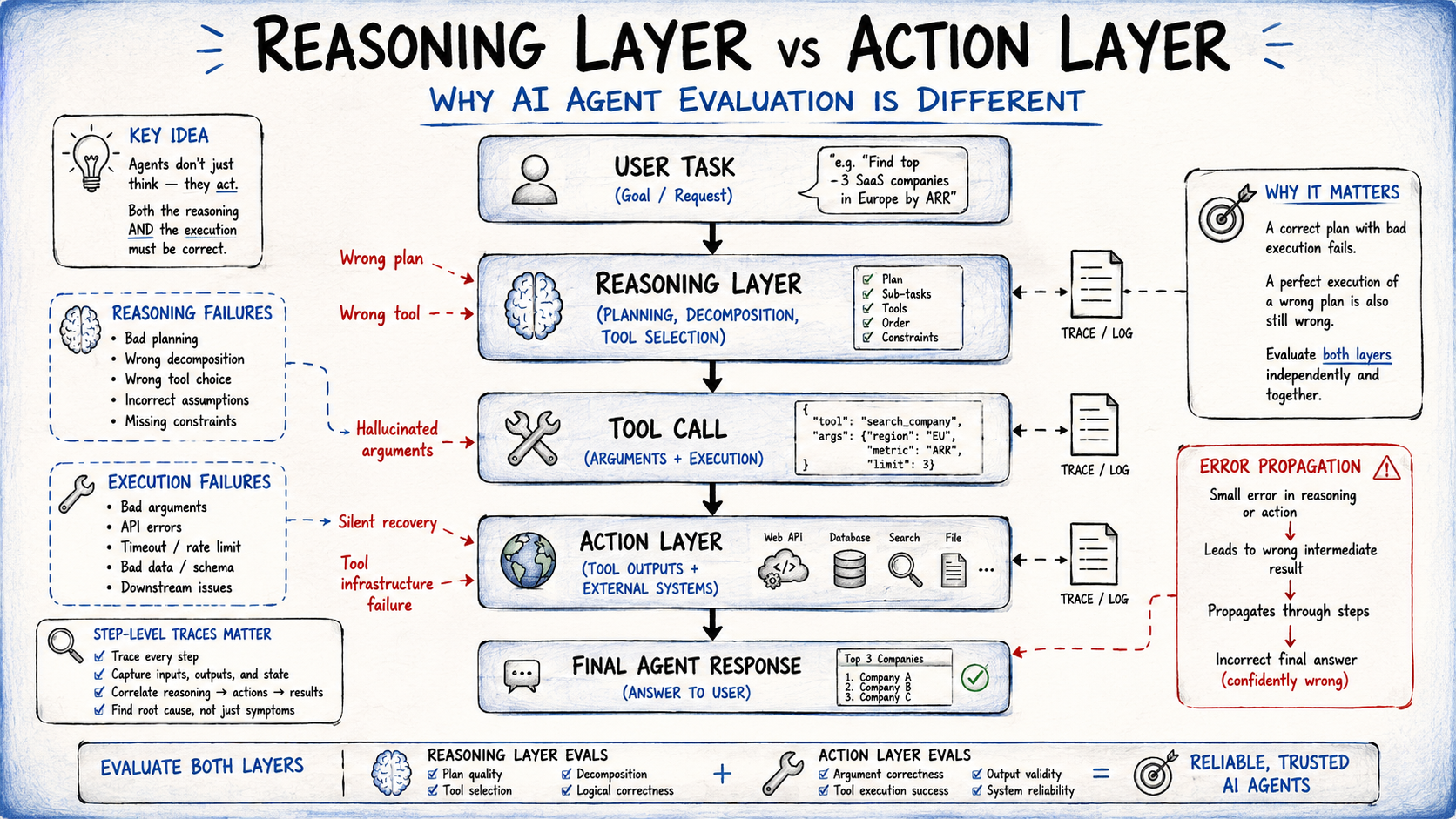
The burgeoning field of artificial intelligence agents necessitates a fundamental re-evaluation of how these complex systems are assessed. Many teams currently developing AI agents continue to employ evaluation methodologies traditionally applied to large language models (LLMs), focusing primarily on final outputs. This approach, however, frequently overlooks critical failure points embedded within an agent’s intricate execution process, leading to a skewed perception of reliability and performance. A comprehensive evaluation strategy must scrutinize the agent’s complete operational lifecycle, from initial reasoning and decision-making to tool utilization and adaptive action sequencing, rather than merely inspecting the end result.
The Evolution of AI Evaluation: From LLMs to Autonomous Agents
The rapid advancement of AI, particularly with the proliferation of sophisticated LLMs, has ushered in an era where AI systems are no longer merely generating text but are actively performing multi-step tasks, interacting with external tools, and adapting to dynamic environments. These advanced entities, known as AI agents, represent a significant leap in complexity. While traditional LLM evaluation often involved assessing the quality, coherence, and factual accuracy of generated text, agents introduce new layers of potential failure. For instance, an agent might select an inappropriate tool, generate malformed arguments for a chosen tool, or mishandle tool failures, all while its final output might appear superficially correct or merely incomplete. Relying solely on the final response makes diagnosing these underlying issues exceptionally challenging, if not impossible.
This paradigm shift necessitates a robust agent evaluation framework that delves into the "how" rather than just the "what." It requires examining the full execution process, including how an agent interprets a task, formulates a plan, interacts with external APIs or databases, and adjusts its strategy in real-time. This granular analysis provides a far more accurate depiction of an agent’s reliability, efficiency, and overall operational integrity, enabling development teams to proactively identify and rectify critical flaws before deployment to production environments. The principles underpinning this systematic approach are increasingly recognized as foundational for measuring and enhancing agent performance across diverse applications.
Understanding the Multi-Layered Nature of Agent Failures
A common instinct when an AI agent falters is to attribute the failure to a poorly constructed prompt, suggesting that clearer instructions are the primary solution. While prompt engineering is undeniably crucial, empirical evidence from leading AI labs indicates that a significant proportion of agent failures stems from inadequate measurement and evaluation design rather than solely prompting deficiencies. AI agents operate across distinct, yet interconnected, layers, each susceptible to independent failure modes. An agent might exhibit impeccable reasoning about the correct course of action, only to subsequently call the right tool with incorrectly formatted arguments, or vice versa. Treating agent evaluation as a singular, end-to-end accuracy check inherently blinds developers to these critical, layer-specific breakdowns.
Effective agent evaluation, therefore, must operate at two distinct but complementary scopes:
- End-to-end task completion: This assesses whether the agent successfully achieved the overarching goal.
- Step-level execution: This meticulously examines each individual action, decision, and interaction within the agent’s operational sequence.
A reported 80% task completion rate, while seemingly positive, provides no insight into the nature of the 20% failure. Was it due to flawed planning, erroneous tool selection, incorrect argument generation, or external tool infrastructure failures? This diagnostic capability is exclusively enabled by step-level traces – detailed logs that capture every tool call, its specific arguments, the outcome of that call, and the subsequent model decision. Without such tracing mechanisms, debugging production failures transforms into a speculative, resource-intensive guessing game. Industry analyses suggest that adopting comprehensive tracing can reduce debugging time by up to 40% in complex agent systems.

Defining Success: The Foundation of Meaningful Evaluation
The efficacy of any evaluation system is directly proportional to the clarity and precision of its defined success criteria. A well-constructed evaluation task should be so unambiguous that two independent domain experts, given the same parameters, would invariably arrive at an identical pass/fail verdict. This demands meticulous preparation and foresight.
The initial step involves establishing unambiguous task specifications, which must be paired with reference solutions. These reference solutions, representing known-correct outputs that satisfy all grading conditions, serve a dual purpose: they confirm the solvability of the task and validate the correct configuration of the grading logic itself. Before any grading runs commence, the following elements are critical for establishing robust evaluations:
- Input parameters: Clearly defined data or conditions provided to the agent.
- Expected outputs: The desired final outcome or state, specified precisely.
- Grading logic: The explicit rules and criteria by which the agent’s performance will be assessed.
While the pursuit of a perfect, exhaustive dataset might seem appealing, it often leads to delays. Experts in AI evaluation advocate starting with a well-specified set of tasks derived directly from real-world usage failures. This pragmatic approach allows teams to build and refine their evaluation infrastructure iteratively, rather than waiting for an elusive ideal.
Dual-Layer Grading: Code-Based Checks for Action, Model-Based Judges for Reasoning
To accurately assess agent performance, a hybrid approach combining deterministic code-based checks with nuanced model-based judgments is essential.
Grading the Agent Action Layer with Code-Based Checks
Deterministic graders, which are pieces of code designed to check specific, objective conditions without relying on model-in-the-loop judgment, represent the fastest, most cost-effective, and reproducible component of any agent evaluation stack. For the action layer, these should always be the initial point of assessment. These checks verify:
- Correct API calls: Ensuring the agent invoked the right external services.
- Valid argument formatting: Confirming that arguments passed to tools adhere to expected schemas and data types.
- Accurate database updates: Verifying that any modifications to data stores are correct.
- Expected file system interactions: Checking for proper file creation, reading, or deletion.
These code-based checks are typically fast, objective, and straightforward to debug. However, they can be brittle. For example, a grader specifically checking for "confirmation_code": "CONF-789" would fail to recognize an otherwise correct response that formats the same data as "confirmationCode": "CONF-789". This highlights their need for precision and careful design.
Grading Agent Reasoning and Output Quality with Model-Based Judges
Certain dimensions of agent evaluation resist purely deterministic checking. These include subjective qualities like output quality, tone, faithfulness to retrieved context, or appropriate empathy in conversational scenarios. For such aspects, a language model utilized as a judge—often termed "LLM-as-a-Judge"—is the appropriate tool. This approach offers flexibility and the capability to handle open-ended outputs but introduces inherent non-determinism and potential calibration drift that code-based graders do not possess. To maintain the reliability of model-based graders, several best practices are critical:
- Structured Rubrics: Vague instructions like "Evaluate whether the response is helpful" generate noisy, inconsistent results. Instead, a structured rubric explicitly detailing criteria—e.g., "The response must directly address the user’s question, ground all claims in retrieved context, and avoid out-of-scope suggestions"—produces a clear, actionable signal. Each dimension should be graded with a separate, isolated judgment.
- Regular Calibration: The accuracy of LLM-as-Judge systems must be routinely benchmarked against a sample of outputs graded by human domain experts. Divergences typically indicate an issue with the rubric itself, requiring refinement. Providing the grader with an explicit "Cannot determine" option prevents forced judgments in genuinely ambiguous cases, improving overall signal quality.
- Partial Credit for Multi-Component Tasks: In complex workflows, a binary pass/fail metric can obscure valuable information. For instance, a customer support agent that correctly identifies a problem and verifies the customer but fails to process a refund is still significantly more effective than one that fails at the initial step. Implementing partial credit mechanisms reveals precisely where the agent is breaking down, allowing for targeted improvements.
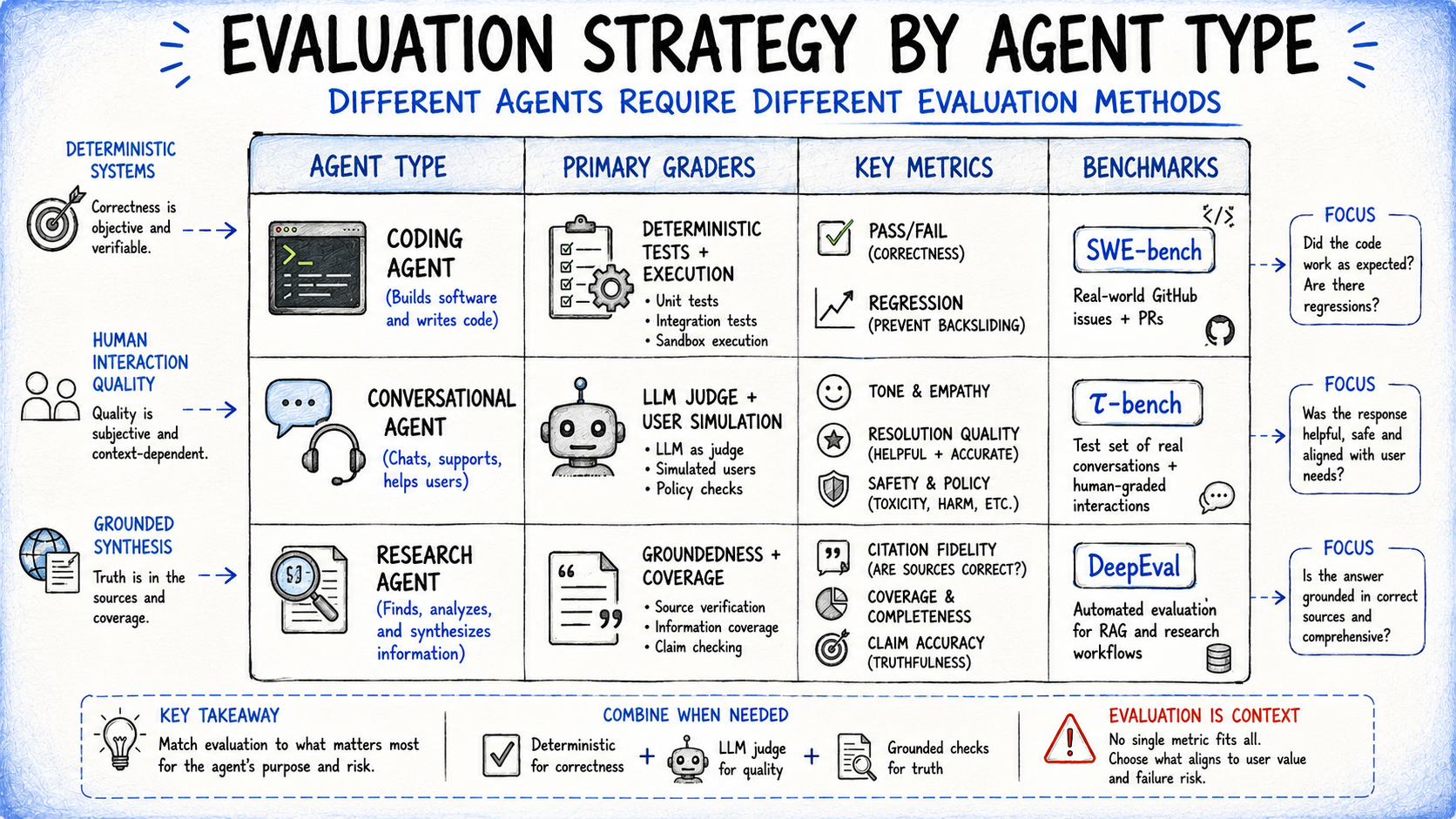
Tailoring Evaluation Strategies to Agent Types
While core grading strategies are broadly applicable, the specific type of AI agent dictates which graders carry the most weight and which failure modes demand prioritized attention.
- Coding Agents: These agents are designed to write, test, and debug code. Software development is largely deterministic: does the code execute correctly, do the tests pass, and does a fix resolve an issue without introducing regressions? Benchmarks such as SWE-bench Verified and Terminal-Bench exemplify this pass/fail approach, often complemented by rubric-based quality checks for aspects like security, readability, and robust edge case handling.
- Conversational Agents: These agents engage with users across various workflows, including customer support, sales, and coaching. Here, the quality of the interaction itself is a primary evaluation dimension. It’s not merely whether a ticket was resolved, but also if the tone was appropriate, the explanation clear, and the overall user experience positive. This often necessitates a second language model simulating a user, with graders assessing both task completion and interaction quality over multiple turns, as demonstrated by frameworks like 𝛌-bench.
- Research Agents: Tasked with gathering and synthesizing information from multiple sources, research agents require distinct evaluation metrics. Groundedness checks verify that all claims are directly supported by the retrieved sources. Coverage checks define the essential components or information that a good answer must include. Source quality checks confirm that the agent consulted authoritative and credible material.
Accounting for Non-Determinism in Agent Performance
A critical challenge in evaluating AI agents is their inherent non-deterministic behavior. The same task, inputs, and agent configuration can yield different tool selections, reasoning paths, and ultimate outcomes across multiple runs. This variability, stemming from stochastic model outputs, tool latency fluctuations, partial system failures, and adaptive decision-making, means that single-trial evaluations can be profoundly misleading, obscuring the true reliability profile.
Consequently, evaluating an agent effectively requires reasoning over distributions of outcomes rather than relying on a single execution trace. To address this variability, metrics such as pass@k and pass^k are commonly employed:
- pass@k: This metric measures the probability that at least one out of k attempts will succeed. For example, if an agent is run three times (
k=3) and succeeds in at least one of those runs, it contributes to the pass@k score. - pass^k: This metric measures the probability that all k attempts will succeed. If an agent is run three times (
k=3), it must succeed in every single one of those runs to contribute to the pass^k score.
Consider an agent with a 75% single-trial success rate. Its pass@1 would be 75%. However, its pass^3 (succeeding on all three attempts) would be approximately 42% (0.75 0.75 0.75). This stark difference vividly illustrates how quickly perceived reliability can degrade when consistent success is required across repeated interactions. The choice between these metrics is ultimately a strategic product decision. If only one successful outcome among several attempts is sufficient (e.g., generating a code snippet where multiple valid solutions exist), pass@k is useful. If every interaction must succeed consistently and reliably (e.g., a critical transaction processing agent), pass^k provides a more meaningful measure of real-world performance.
Strategic Evaluation Suites: Capability vs. Regression
Effective AI agent development relies on a two-pronged evaluation strategy: capability evaluations and regression evaluations, each serving a distinct purpose.
Capability Evaluations are forward-looking, designed to answer the question: "What new tasks or functionalities can this agent now perform that it couldn’t before?" These evaluations typically begin with relatively low pass rates, focusing on tasks that push the boundaries of the system’s current abilities. As an agent evolves and improves, its performance on capability evals will rise. However, once a capability evaluation reaches consistently high scores (e.g., above 90%), it often ceases to measure new capabilities and instead begins to confirm reliability on already solved problems.
Regression Evaluations, conversely, serve as a critical safeguard. Their purpose is to determine: "Can the agent still perform everything it previously could?" These tests are expected to achieve near 100% pass rates and act as an early warning system against performance regressions introduced by new code deployments or model updates. Any significant drop in a regression suite’s score signals a critical issue that must be investigated and resolved before release.
Over time, tasks from capability evaluations naturally transition into the regression suite as the agent masters them. However, a crucial consideration is "suite saturation." Once an evaluation suite becomes fully saturated (i.e., the agent consistently achieves near-perfect scores), it loses sensitivity to real improvements, making it difficult to discern meaningful progress from mere noise. To counteract this, new and more challenging capability evaluations must be continuously introduced before the existing suite reaches full saturation. This proactive approach ensures that evaluation remains a driving force for innovation and improvement.
Extending Evaluation into Production Monitoring
While development-phase evaluations are vital for capturing expected failures, the true test of an AI agent occurs in production. Real users introduce unforeseen inputs, edge cases, and contextual nuances that are rarely fully replicated in synthetic test suites. Therefore, robust production monitoring is not merely an option but a necessary extension of the entire evaluation lifecycle.
A truly complete evaluation system integrates several complementary signals to provide a holistic view of agent performance in practice:
- Automated Evals: These are run on every commit, serving as a first line of defense against known failure modes and scaling to cover a broad range of scenarios before users are impacted. However, they can create a false sense of security if real-world usage patterns diverge significantly from the test distribution.
- Production Monitoring: This involves tracking key operational metrics such as latency, error rates, tool failures, and token usage in real-time. It effectively surfaces issues that synthetic tests might miss, though typically only after they have occurred. Advanced anomaly detection can provide early warnings.
- User Feedback: Direct user input, though often sparse and self-selected, is invaluable. It highlights instances where an agent might appear correct by internal metrics but fundamentally fails to meet the user’s intent or expectation. This qualitative data is highly informative for identifying critical usability or alignment gaps.
- Manual Transcript Review: Human review of agent-user interaction transcripts provides deep qualitative insight into the agent’s reasoning process, tool utilization, and decision paths. It is crucial for validating whether automated graders are accurately measuring the desired behaviors and for uncovering emergent patterns of failure or success.
The infrastructure that underpins all these monitoring and evaluation layers is comprehensive step-level tracing, capturing the agent’s reasoning, tool calls, arguments, results, and decisions at every point in its execution loop. Industry-standard platforms such as LangSmith, Arize Phoenix, Braintrust, and Langfuse provide robust tracing and evaluation frameworks, while tools like Harbor and DeepEval handle the harness layer, facilitating the orchestration and execution of these complex evaluation pipelines.
Conclusion: A New Era for AI Agent Reliability
The rigorous evaluation of AI agents represents a critical paradigm shift in artificial intelligence development. Moving beyond superficial output analysis to a deep examination of the full execution process is no longer optional but imperative for building reliable, efficient, and trustworthy AI systems. By distinguishing agent evaluation as a unique problem, defining success with meticulous clarity, employing a hybrid of code-based and model-based graders, tailoring strategies to specific agent types, accounting for non-determinism, utilizing both capability and regression suites, and extending evaluation into real-time production monitoring, developers can establish a robust framework for continuous improvement. This holistic approach, underpinned by detailed step-level tracing, is essential for unlocking the full potential of AI agents and ensuring their safe, effective, and ethical deployment across an increasingly complex technological landscape. The future of AI hinges on our ability to meticulously measure and understand its every operational nuance.
