

OpenAI has quietly launched GPT Image 2, its latest advancement in AI-driven image generation. The release, characterized by its understated approach, eschews elaborate keynotes and marketing fanfare, instead presenting a model page primarily showcasing a gallery of its capabilities. This strategic unveiling has already made a significant impact, as evidenced by its commanding lead on the Image Arena leaderboard, surpassing all other models by an unprecedented 242 points. This substantial margin signifies a potential paradigm shift in the competitive landscape of AI image synthesis.
The timing of GPT Image 2’s introduction is particularly noteworthy. It arrives shortly after Google’s Nano Banana 2 had claimed the top spot in AI image generation. In a previous comparison, Nano Banana 2 was evaluated against ByteDance’s Seedream 5 Lite across seven distinct categories. While Seedream held its own in terms of pricing and spatial fidelity, Nano Banana 2 excelled in speed and text rendering. OpenAI’s entry with GPT Image 2 now reconfigures this competitive dynamic, aiming to set a new benchmark for the entire field.

GPT Image 2, identified by the model identifier gpt-image-2 and operating on the GPT-5.4 backbone, represents a significant architectural evolution for OpenAI. It is the company’s first image model to incorporate native reasoning capabilities directly into its core design. This means that prior to generating any visual output, GPT Image 2 engages in a process of research, planning, and logical deduction regarding the intended image structure. This integrated reasoning layer is expected to enhance the coherence, accuracy, and contextual relevance of generated images.
Coinciding with the debut of GPT Image 2, OpenAI has announced the discontinuation of its predecessor models, DALL-E 3 and GPT Image 1.5. Both services are scheduled to cease operations on May 12th. This move signifies not an incremental update, but a complete replacement, underscoring the transformative nature of the new model.
To assess the capabilities of GPT Image 2 and its impact on the current AI image generation hierarchy, a comprehensive evaluation was conducted, employing the same seven-category framework used in the previous comparison between Nano Banana 2 and Seedream. This methodology aims to objectively determine whether Google’s reigning champion can maintain its overall lead against OpenAI’s new contender.

The Enhanced Capabilities of GPT Image 2
The most striking advancement offered by GPT Image 2 is its mastery of text rendering. OpenAI claims an approximate 99% character-level accuracy across a wide spectrum of scripts, including Latin, CJK (Chinese, Japanese, Korean), Hindi, and Bengali. This level of precision represents a substantial leap forward from previous AI image generation models, where text rendering has historically been a significant limitation, often resulting in garbled signage, nonsensical fonts, and illegible characters. GPT Image 2 appears to have largely resolved this persistent challenge.
Beyond text, the model supports image generation at resolutions up to 4K. It can produce up to eight coherent images from a single prompt, crucially maintaining consistent characters and objects across the entire batch. This batch consistency is a novel feature that holds significant promise for professional workflows, particularly for industries such as children’s book publishing and advertising agencies managing multi-format campaigns, providing them with a tool that addresses a previously unmet need.
OpenAI has implemented a tiered access model for GPT Image 2. The core advancements are available to all ChatGPT users, including those on the free tier, through an "Instant Mode." For users requiring the more sophisticated reasoning and web-searching capabilities, a "Thinking Mode" is reserved for subscribers of ChatGPT Plus, Pro, and Business plans. The official API is slated for release to developers in early May, promising further integration and application possibilities.

Until the API’s widespread availability, direct access to GPT Image 2 is primarily facilitated through ChatGPT or third-party proxies, with an estimated cost of $0.01 to $0.03 per image. For developers utilizing the API, pricing is structured on a token basis, with input tokens costing $8 per million and output image tokens at $30 per million. This pricing structure is marginally more cost-effective than Nano Banana 2’s $60 per million output tokens at comparable resolution tiers.
Comparative Analysis: GPT Image 2 vs. Nano Banana 2
To rigorously evaluate the performance of GPT Image 2, a head-to-head comparison was conducted against Google’s Nano Banana 2, using a standardized set of seven categories.
Realism: The Rooftop Architect Test
A prompt was designed to generate a cinematic portrait of a 32-year-old female architect at sunset. Specific constraints included coat color, glasses type, a roll of blueprints held in the right hand, golden hour lighting, a 50mm depth-of-field simulation, film grain, and a 4:5 vertical aspect ratio. Each element was an independent constraint designed to test the models’ ability to adhere to complex instructions.

GPT Image 2 produced an impressive result, showing marked improvement over its predecessors. However, the subject’s gaze retained a characteristic AI "mood" that can sometimes be discernible. The city skyline bokeh effectively simulated a 50mm f/1.8 lens, and the trench coat fabric exhibited tactile weight. The skin displayed natural freckled texture with realistic subsurface scattering, a significant improvement over the often smooth, synthetic finish seen in beauty-trained diffusion models. Critically, the blueprints were held in the right hand as specified.
In contrast, Nano Banana 2 generated a competent portrait that, upon closer inspection, appeared more composite. The sunset lighting was slightly oversaturated for a true golden hour, and while the skin texture was natural for the resolution, the subject’s stare felt more genuine and less artificial than GPT Image 2’s. The image lacked film grain, and the subject held multiple different blueprints instead of a single roll. This output was remarkably similar to previous tests, suggesting a potential limitation in Nano Banana 2’s creative flexibility when faced with diverse constraints.
Winner: Nano Banana 2

Art and Painting: The Renaissance Astronomer
This category tested the models’ ability to render complex artistic styles and lighting scenarios. The prompt requested a Rembrandt-esque painting featuring three competing light sources: warm candlelight, cold moonlight, and a green bioluminescent jar. The scene was to be set in a cluttered stone observatory, with specific desk objects, a cat with one white paw, and a visible oil brushstroke texture.
GPT Image 2 accurately captured the interplay of light, with each source casting its distinct color temperature across surfaces. The velvet robe showed realistic fraying at the cuffs, the skull was effectively used as a bookend, the tome displayed what appeared to be handwritten text, and the black cat with a single white paw was silhouetted against a comet-filled sky. The overall impression was that of an authentic oil painting, rather than a digital rendering.
However, GPT Image 2 exhibited a recurring flaw, particularly when presented with numerous parameters: over-sharpening and the generation of artifacts that significantly degrade image quality. This issue has been described as potentially analogous to the "piss filter" problem noted in earlier GPT Image generations, suggesting a specific artifact that emerges under complex prompt conditions.

Nano Banana 2 produced a visually beautiful image, but one that veered into a different genre. It resembled high-end fantasy card illustration more than a classical oil painting. The depth of the painting was shallow, the text on the tome was legible but lacked script-like character, and the cat possessed two white paws instead of the specified one. While the scene was overexposed, the representation of the light sources was accurate.
Winner: GPT Image 2
Illustration: The Anime Spirit Medium
This category focused on the nuanced rendering of specific artistic styles, particularly anime. The prompt requested an anime key visual in the style of Ufotable (known for "Demon Slayer" and "Fate/Zero"), with specific technical requirements: cel shading with varied ink outline weight, a body transitioning into energy, subsurface skin glow, a nine-tailed kitsune, legible ofuda talisman calligraphy in kanji, and a Makoto Shinkai-inspired twilight background in violet, amber, and rose.

Nano Banana 2 delivered an output widely considered the strongest of the entire seven-category evaluation. The cel shading exhibited correct ink weight variation, the fox’s tails were luminous and clearly depicted, the ofuda kanji was recognizable, and the twilight gradient was precise. The composition effectively resembled a theatrical poster.
GPT Image 2, in comparison, produced an anime pastiche. It featured clean outlines, a correct energy dissolution effect, and pleasant cherry blossom bokeh. However, the characteristic Ufotable subsurface skin glow was absent, and the nine-tailed kitsune was depicted as a single physical tail companion with other tails rendered differently. The over-sharpening and artifact issue was again apparent, diminishing the overall visual appeal of the image.
Winner: Nano Banana 2

Lettering and Style Understanding: The Signature Design Test
This test evaluated the models’ ability to understand and replicate a specific lettering style based on provided references. The prompt asked for an abstract yet legible cursive signature for "José Lanz," emulating an ornate, controlled complexity from a professional lettering service.
GPT Image 2 produced a clean, fluid cursive signature with correct loop ascenders. The output was rendered on textured paper with an embossed letterpress effect. The signature was legible as "José Lanz" and stylized appropriately. The critique here is that it played it safe, lacking the energetic entanglement seen in the reference material. Nevertheless, it was a usable deliverable that accurately emulated the reference aesthetic.
Nano Banana 2 attempted to match the ornate complexity but resulted in illegible scrawl. The reference material’s appeal lay in its controlled chaos, where wild loops resolved into readable letterforms. Nano Banana 2’s output was chaotic without legibility. Furthermore, it reproduced the service’s watermark, which poses an intellectual property concern in a professional context.

Winner: GPT Image 2, by a significant margin
Spatial Awareness: The Steampunk Aerial
This category presented a demanding compositional prompt requiring multiple objects at specific locations. The request was for a vast steampunk clock tower city viewed from a three-quarter aerial perspective, with five distinct depth planes, an atmospheric haze gradient, and six specific readable text elements distributed across the scene. This included four clock faces, each displaying different times in Roman numerals.
Nano Banana 2 marginally outperformed in this category. Its aerial geometry was more convincing, with the three-quarter view genuinely reading as such, rather than a tilted front view. The five depth planes were distinctly separated, the atmospheric haze increased correctly with distance, and the wet cobblestone newspaper texture was excellent. While the elements were properly represented and the text was readable, not all specified lines of text appeared in the scene.

GPT Image 2 successfully rendered all six text elements and correctly depicted the four clock faces with different times. However, the depth planes partially collapsed in the mid-ground. Similar to other complex prompts, the large number of parameters appeared to degrade image quality, triggering the over-sharpening effect, reminiscent of using a LoRA in Stable Diffusion with excessive presence.
Winner: Nano Banana 2
Lettering Density: The Kellerman’s Hardware Scene
This was the most challenging text-recall test, requiring the rendering of a gritty urban intersection at 2 a.m. where every surface was to carry readable copy. This included a ghost sign, graffiti in chrome bubble letters, vinyl storefront lettering, a concert poster with a barcode, a torn reveal underneath, embossed metal awning letters, cardboard handwriting, stenciled curb text, and a sticker-bombed payphone with specific copy including "ANSWERS TO MOCHI."

GPT Image 2 delivered near-perfect element recall. Every specified text element was present and readable. The ghost sign’s drop-shadow fade and peel texture were exceptional. The sodium vapor color cast was accurate, depicting the specific green-amber hue of actual sodium vapor streetlights, rather than a generic amber. Wet asphalt reflections were also convincing.
Nano Banana 2 also performed strongly but lost some specificity. The "STILL HERE" graffiti used outline bubble letters instead of chrome fill. The torn poster reveal was partial, and the sodium vapor cast was more generic. Several elements from the prompt did not survive the rendering process. Despite these shortcomings, the visual output was more pleasing than GPT Image 2’s due to the absence of its over-sharpening flaw.
Winner: GPT Image 2, due to superior prompt adherence

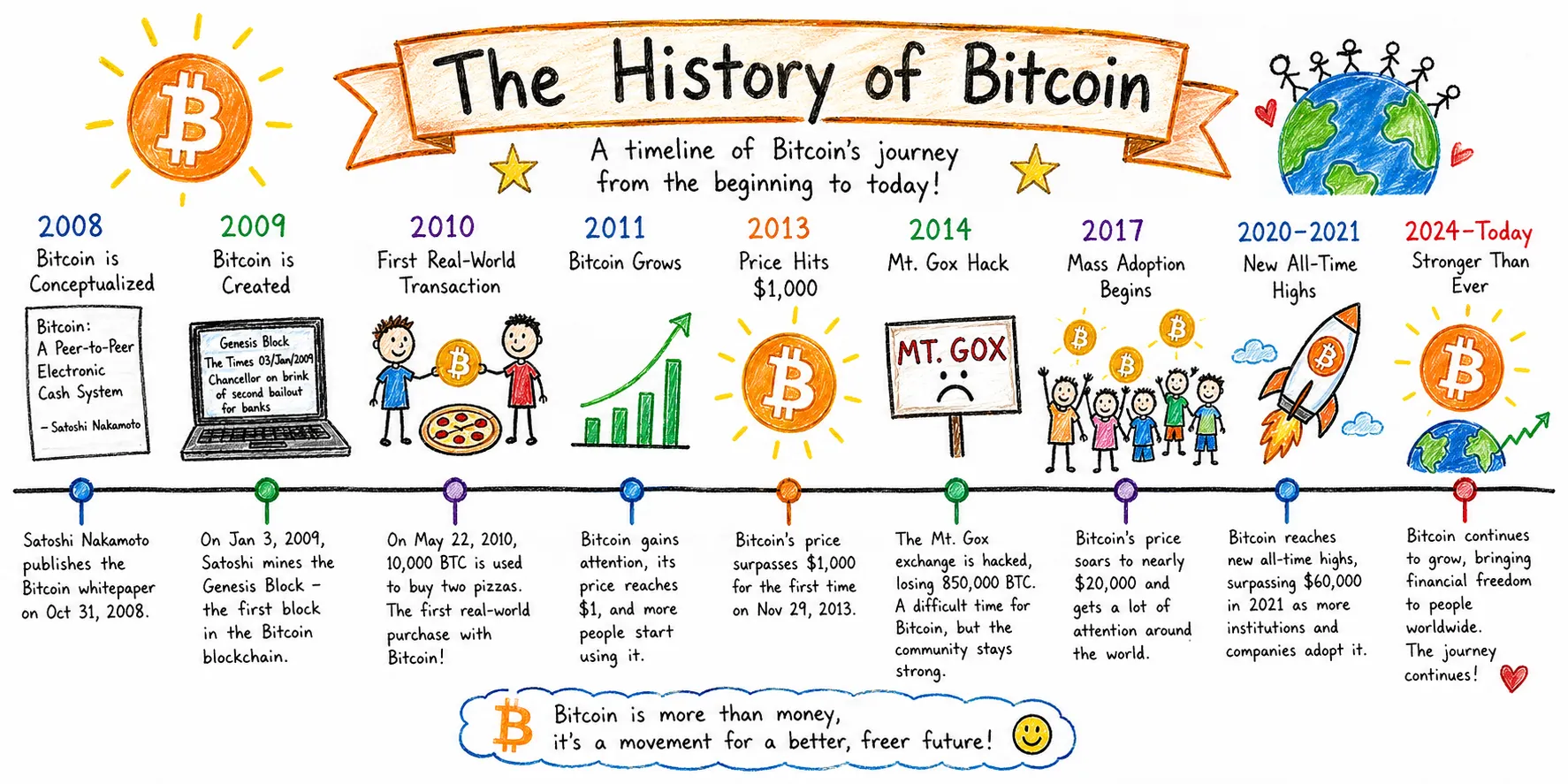
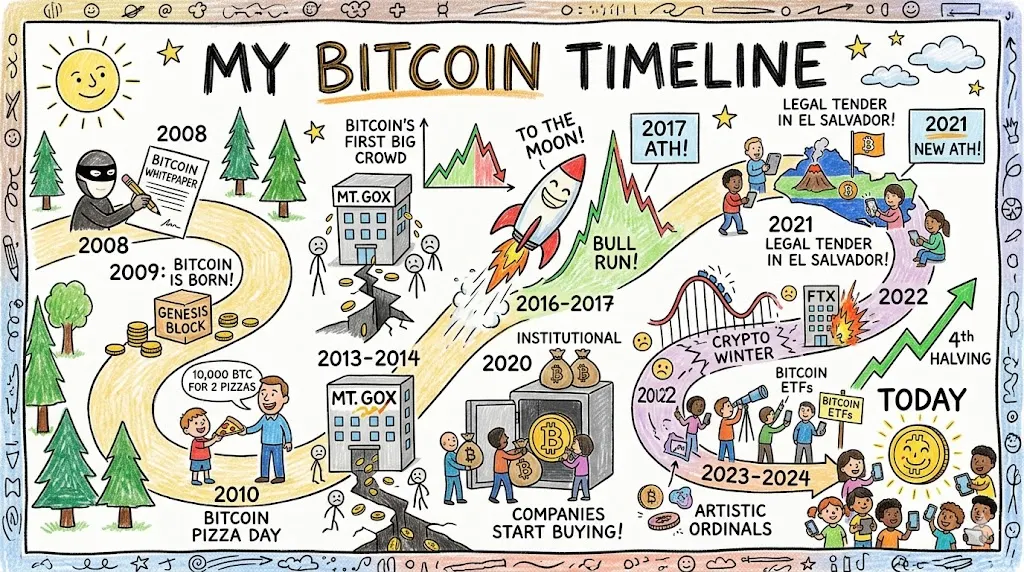
Agentic Research: The Bitcoin Timeline
This category assessed a different capability: editorial judgment and information architecture, utilizing the models’ agentic research functions. The prompt requested a widescreen Bitcoin history timeline rendered in a kid’s drawing style, with a strict emphasis on information accuracy.
GPT Image 2 approached this task as an infographic commission. The output featured a horizontal timeline with color-coded year markers, illustration slots above, and explanatory text below each event. Key dates were accurately presented: October 31, 2008, for the white paper; January 3, 2009, for the genesis block; and May 22, 2010, for Pizza Day. The Mt. Gox entry correctly cited the loss of 850,000 BTC, and events were evenly distributed from 2008 to 2024.
Nano Banana 2’s output was more visually charming, employing a winding road metaphor for Bitcoin’s volatile journey, which was genuinely clever. However, the first-person title "My Bitcoin Timeline" was peculiar for an informational piece. The 2020-2024 section was visually congested, and the information density was uneven across different eras.

Verdict: A tie. Nano Banana 2 is more visually pleasing, but GPT Image 2 presents more accurate information.
Image Editing: Living Room Redesign
This final test measured the models’ ability to modify an existing image while retaining its core identity, akin to the functionality required by staging apps or interior architect tools. The prompt instructed: "Here is a photo of my living room. Make it more modern and minimalistic. Change the floor for a marble white one, use mirrors in a cohesive style to decorate the front wall, and make the overall aesthetic modern and more pleasing to the eyes."
GPT Image 2’s output was immediately recognizable as the original room. Key elements like the door, smart lock, wall art arrangement, hanging plant, and shelf were preserved. The model’s redesign choices were well-executed for the prompt’s intent: a lit triptych replaced the mixed mirror arrangement, creating a focal wall with a warm LED halo, a recognized interior design technique. The reflections on the mirror accurately matched the references, demonstrating a sophisticated implementation. However, the instruction to change the floor to white marble was not implemented.
Nano Banana 2’s output looked more realistic due to its lighting but exhibited a more chaotic relationship with the source material. It interpreted the "use mirrors" instruction too literally, incorporating mirrors on mirrors. The mixed frame styles (gold, brass, varied shapes) contradicted the "cohesive style" instruction. It appeared as though the model applied an inpainting layer to specific areas, and the perspective was slightly off.
Winner: GPT Image 2, due to superior adherence to design choices. It is easier to iteratively change individual elements than to instruct Nano Banana 2 to correct its numerous misinterpretations.
Overall Verdict and Implications
GPT Image 2 emerges as the dominant force in this comparative analysis, winning in the majority of categories: realism, classical art rendition, signature calligraphy, image editing, and lettering density. Nano Banana 2 secured victories in anime illustration, spatial composition, and structured information design.
A significant observation is that GPT Image 2 demonstrates remarkable consistency across prompts, particularly when provided with sufficient creative freedom to avoid triggering its over-sharpening artifact. When this issue is circumvented, the generated results are aesthetically pleasing, highly realistic, and excel in text rendering.
The competitive landscape has narrowed significantly, with both models showcasing advanced capabilities. The proximity in quality suggests that effective prompting strategies may become the deciding factor in achieving optimal outcomes for each model.
For users approaching AI image generation for the first time, GPT Image 2 appears to be the more accessible model. However, Nano Banana 2, when guided by a refined prompting technique and iterated upon, can produce outstanding results that may appear more professional and polished depending on the specific use case. The introduction of GPT Image 2 signifies a considerable advancement in the field, pushing the boundaries of what is possible in AI-generated imagery and setting a new standard for its competitors to meet. The ongoing evolution of these models suggests a future where AI-generated visuals will become increasingly indistinguishable from human-created art and design.
