
The landscape of artificial intelligence, particularly in the realm of large language models (LLMs), is experiencing a profound transformation, fundamentally reshaping how we approach information retrieval and generation. Retrieval-Augmented Generation (RAG), a technique designed to enhance LLM responses by grounding them in external knowledge, is at the forefront of this evolution. For years, the prevailing wisdom in RAG system design dictated a strategy of breaking down extensive documents into smaller, manageable chunks, embedding these fragments, and retrieving only the most pertinent pieces to feed into an LLM. This approach was a pragmatic necessity, driven by the inherent limitations of early LLMs, whose context windows were both computationally expensive and severely constrained, typically ranging from a mere 4,000 to 32,000 tokens. This limited capacity meant that feeding an entire book or even a lengthy research paper directly into a model was impractical, if not impossible.
However, the rapid advancements in LLM architecture have shattered these previous barriers. Modern models, such as Google’s Gemini Pro and Anthropic’s Claude Opus, now boast astonishing context windows that can encompass 1 million tokens or more. This monumental leap theoretically allows developers to input vast swathes of information – an entire collection of novels, comprehensive legal dossiers, or extensive scientific archives – directly into a single prompt. While this expanded capacity represents a significant achievement and promises unprecedented capabilities for contextual understanding, it concurrently introduces a new set of complex challenges that demand innovative solutions. The simple act of increasing context size does not automatically translate to improved performance; rather, it uncovers deeper issues related to how LLMs process and prioritize information within these enormous inputs, alongside significant cost implications.
The Evolution of RAG and LLM Context Windows: A Brief History
The concept of RAG gained prominence as a crucial bridge between the impressive generative capabilities of LLMs and the need for factual accuracy and up-to-date information. Early LLMs, while adept at generating human-like text, often suffered from "hallucinations" – producing plausible but factually incorrect information – and were limited by the static nature of their training data. RAG offered a dynamic solution, allowing models to consult external, current, and domain-specific knowledge bases in real-time.
Initially, the primary bottleneck was the LLM’s context window. Developers were forced to engineer sophisticated chunking strategies, complex indexing, and precise retrieval mechanisms to ensure that only the most critical information, condensed into concise segments, reached the LLM. Techniques like semantic search using vector embeddings became standard, aimed at identifying conceptual relevance rather than just keyword matches. This era saw a focus on minimizing the input size to maximize the limited processing power and memory available.
The turning point arrived with architectural innovations that dramatically expanded context windows. This shift began subtly, moving from tens of thousands to hundreds of thousands of tokens, culminating in the million-token-plus capabilities seen today. This progression, while exciting, has shifted the focus from merely fitting information into the context window to effectively utilizing that information once it’s there. The initial "RAG mantra" of aggressive chunking, while still valuable, needs to be re-evaluated in light of these new capacities. The challenge is no longer just about what to retrieve, but how to present it to the LLM to ensure optimal attention and comprehension, all while managing the associated computational costs.
The "Lost in the Middle" Phenomenon: A Critical Challenge for Long Context
One of the most significant and extensively studied challenges arising from extremely long context windows is the "Lost in the Middle" problem. Identified in a landmark 2023 study conducted by researchers from Stanford University and UC Berkeley, this phenomenon reveals a critical limitation in how LLMs process information within extensive prompts. The study demonstrated that when LLMs are presented with a long sequence of input tokens, their performance in accurately identifying and utilizing relevant information peaks when that information is situated at the very beginning or the very end of the context window. Conversely, information buried in the middle of a lengthy prompt is significantly more likely to be overlooked, misinterpreted, or simply ignored by the model.
This finding has profound implications for RAG system design. Simply concatenating retrieved documents and feeding them into a million-token context window does not guarantee that the LLM will effectively utilize all the provided information. The model’s attention mechanisms, despite their sophistication, appear to struggle with maintaining consistent focus across vast spans of text, leading to a diminished capacity to extract crucial details from the central portions of the input. This problem is not merely an inconvenience; it can severely undermine the reliability and accuracy of RAG systems, especially in applications requiring deep contextual understanding from large documents. Addressing "Lost in the Middle" is paramount to unlocking the true potential of expanded context windows.
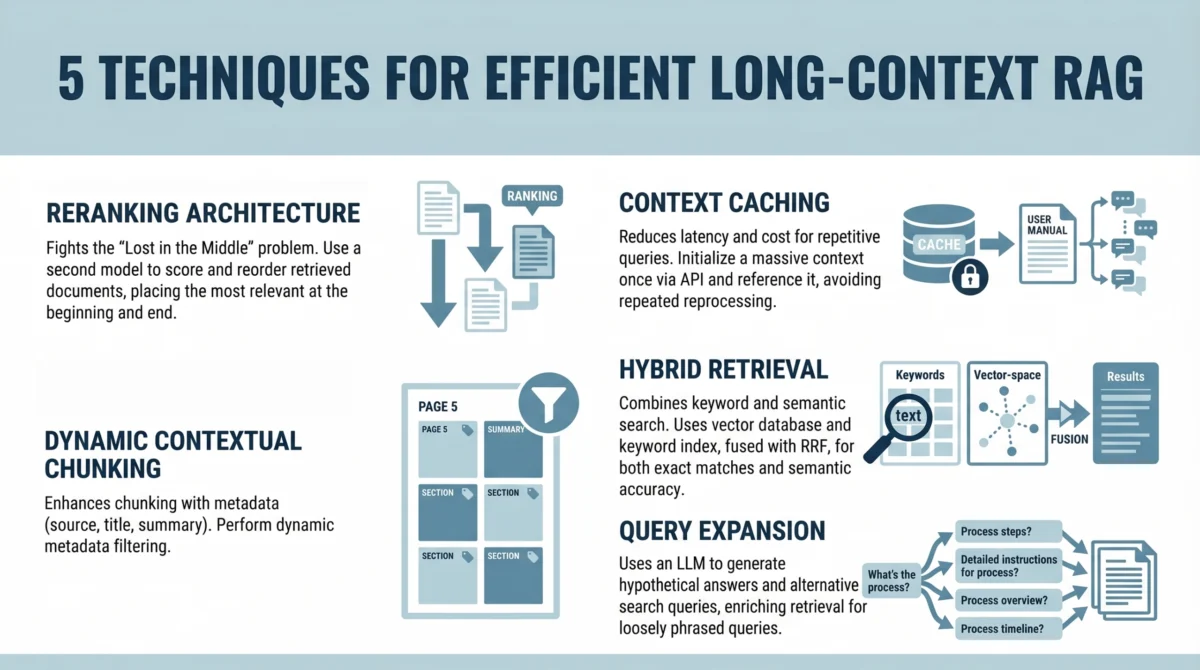
Strategic Solutions for Building Efficient Long-Context RAG Systems
To effectively leverage the power of long-context LLMs while mitigating their inherent challenges, developers are adopting a suite of advanced techniques that move beyond simplistic document partitioning. These strategies focus on enhancing the LLM’s attention, optimizing computational resources, and improving retrieval precision.
1. Implementing a Reranking Architecture to Fight "Lost in the Middle"
Given the "Lost in the Middle" problem, directly inserting retrieved documents into the prompt in their original order is no longer an optimal strategy. A crucial intervention is the introduction of a reranking step. This architectural enhancement involves a two-stage retrieval process designed to present the most relevant information to the LLM in strategically advantageous positions.
Developer Workflow:
- Initial Retrieval: A first-stage retriever (e.g., a vector search system) identifies a broad set of potentially relevant document chunks or passages based on the user’s query. This initial set might be larger than what would traditionally be fed directly into an LLM, perhaps 20-50 documents.
- Reranking: A dedicated reranker model (often a smaller, highly optimized transformer model or a specialized cross-encoder) takes the user query and each of the initially retrieved documents. It then re-scores these documents based on a more granular assessment of their relevance to the query. This reranker is typically trained specifically for relevance ranking.
- Strategic Placement: The top N documents identified by the reranker are then strategically placed within the LLM’s prompt. Critically, these most relevant documents are positioned at the beginning and/or the end of the input context, where the LLM’s attention is known to be strongest. Less critical, but still potentially useful, context can be placed in the middle.
This strategic placement ensures that the most important information receives maximum attention from the LLM, directly combating the "Lost in the Middle" problem. Studies have shown that even a simple reranking step can lead to significant improvements in answer quality and factual accuracy, especially when dealing with a large pool of retrieved documents. Companies like Cohere and cross-encoder models are popular choices for implementing robust reranking capabilities.
2. Leveraging Context Caching for Repetitive Queries
While large context windows offer immense potential, they also introduce significant latency and cost overhead. Processing hundreds of thousands or even millions of tokens for every single query can quickly become prohibitively expensive and slow, especially in high-throughput applications. Context caching addresses this issue by recognizing and reusing previously processed context.
Mechanism:
- Persistent Context Initialization: For applications where a significant portion of the context remains static across multiple user interactions (e.g., a chatbot interacting with a fixed knowledge base, an internal document Q&A system for a specific project), a "base" or "persistent" context can be pre-processed and cached. This might include foundational documents, company policies, or the general theme of a conversation.
- Incremental Updates: When a new query arrives, the system first checks if the query can be answered using the cached context. If not, or if new, dynamic information is required, only the delta – the new or updated relevant information – is retrieved and added to the prompt alongside the cached context.
- Prefix Caching: Some LLM inference engines and frameworks support "prefix caching" or "kv-cache reuse." This allows the key-value cache (KV cache) generated from processing a common prefix (the cached context) to be reused across multiple requests, avoiding redundant computation for that shared portion of the input.
This approach is particularly useful for chatbots built on static knowledge bases, internal support systems, or long-running conversational agents. It significantly reduces the computational load and inference time for repetitive queries, leading to substantial cost savings and improved user experience.
3. Using Dynamic Contextual Chunking with Metadata Filters
Even with the advent of enormous context windows, the principle of relevance remains paramount. Simply increasing the context size does not inherently eliminate noise or guarantee that the LLM will focus on the most pertinent details. Overloading the LLM with irrelevant information can still degrade performance, akin to asking a person to find a needle in a haystack, even if the haystack is now larger.
Approach:
- Enhanced Traditional Chunking: This technique builds upon traditional document chunking but enhances it significantly with structured metadata. Instead of uniform, fixed-size chunks, documents are broken down into semantically meaningful segments. For instance, a technical manual might be chunked by sections, subsections, diagrams, and code examples.
- Rich Metadata Association: Each chunk is then associated with comprehensive metadata. This metadata can include:
- Source: Document title, author, date, URL.
- Structure: Section heading, chapter, paragraph number.
- Content Type: Text, table, image description, code snippet.
- Keywords/Tags: Automatically extracted or manually assigned keywords.
- Permissions: Access control information.
- Dynamic Filtering: When a user query is processed, the system first analyzes the query for explicit or implicit filtering criteria. For example, a query like "What are the security protocols for customer data after 2023?" can trigger a metadata filter for documents published or updated post-2023. Similarly, "Show me code examples for API integration" can filter for chunks explicitly tagged as "code snippet."
- Retrieval Refinement: The initial retrieval (e.g., vector search) is then performed on the filtered set of chunks, or the metadata is used to re-rank results. Only chunks that meet both semantic relevance and metadata criteria are then passed to the LLM.
This approach significantly reduces irrelevant context, improving the precision of the retrieved information and ensuring the LLM receives a cleaner, more focused input. It allows for highly targeted retrieval, making the RAG system more robust and reliable across diverse query types.
4. Combining Keyword and Semantic Search with Hybrid Retrieval
Vector search, a cornerstone of modern RAG, excels at capturing the semantic meaning and conceptual similarity between a query and document chunks. It can successfully retrieve documents that discuss a topic without necessarily using the exact keywords from the query. However, pure semantic search can sometimes miss exact keyword matches, which are often crucial for technical queries, specific names, dates, or precise numerical data. For example, a query about a specific product ID or an error code might perform better with an exact match.
Methodology:
- Dual Retrieval Paths: Hybrid search combines the strengths of both semantic (vector-based) retrieval and keyword-based (lexical) retrieval.
- Semantic Search: Uses embedding models to generate vector representations of both the query and document chunks, then calculates similarity (e.g., cosine similarity) to find conceptually related content.
- Keyword Search: Utilizes traditional search algorithms (e.g., BM25, TF-IDF, or inverted indexes) to find documents containing exact or highly similar keyword matches.
- Fusion Algorithm: The results from both retrieval methods are then combined using a fusion algorithm, such as Reciprocal Rank Fusion (RRF). RRF aggregates the ranked lists from semantic and keyword search, giving higher scores to documents that appear high in both lists. This ensures that documents that are both semantically relevant and contain critical keywords are prioritized.
- Configurable Weighting: Developers can often configure the weighting between semantic and keyword scores based on the specific domain or expected query types. For highly technical domains, keyword matching might receive a higher weight.
This hybrid approach ensures both semantic relevance and lexical accuracy, leading to a more comprehensive and robust retrieval process. It is particularly effective for complex queries that require both conceptual understanding and precise factual recall.
5. Applying Query Expansion with Summarize-Then-Retrieve
User queries, especially in natural language interfaces, often suffer from ambiguity, brevity, or a lack of explicit detail. They might be phrased differently from how information is expressed in the underlying documents, or they might imply a broader intent than what is explicitly stated. Query expansion techniques help bridge this gap by transforming the initial user query into more effective search prompts.
Process:
- Lightweight LLM for Expansion: A lightweight or smaller LLM (which is faster and cheaper to run than a full-scale generative model) is employed to generate alternative search queries or rephrased versions of the original query.
- Hypothetical Document Generation (HyDE): A popular technique involves instructing the LLM to generate a "hypothetical document" that would answer the user’s query, even if no such document exists. This hypothetical document is then embedded and used as the query vector for semantic search. This provides a richer, more contextual embedding than the original short query.
- Paraphrasing and Synonyms: The LLM can also generate paraphrases, synonyms, or related terms to broaden the search space.
- Summarize-Then-Retrieve: For complex or multi-part queries, the LLM can first summarize the core intent of the user’s request. This summary, or multiple hypothetical sub-queries derived from it, can then be used for retrieval.
Example:
- User Query: "What do I do if the fire alarm goes off?"
- Generated Hypotheticals (by lightweight LLM):
- "Emergency procedures for fire alarms"
- "Building evacuation steps during a fire"
- "Safety guidelines for fire incidents"
- "What to do when a smoke detector sounds"
- "Fire safety instructions"
- Retrieval with Expanded Queries: The RAG system then performs retrieval using the original query and all generated hypotheticals. The combined results are then reranked and presented to the main LLM.
This approach significantly improves performance on inferential and loosely phrased queries by generating a richer set of search terms and contexts, thereby increasing the likelihood of retrieving highly relevant documents.
Broader Implications and Future Outlook
The emergence of million-token context windows marks a pivotal moment in the development of AI, but it does not diminish the critical role of retrieval-augmented generation. Instead, it fundamentally reshapes RAG, elevating it from a workaround for limited context to an indispensable tool for precision, cost-efficiency, and accuracy in an era of abundant information. The techniques discussed – reranking, context caching, dynamic chunking with metadata, hybrid retrieval, and query expansion – are not mere optimizations; they represent essential strategies for building robust, scalable, and intelligent systems.
The implications for various industries are profound. In legal tech, RAG systems can now process entire case files, contracts, and legal precedents, enabling lawyers to quickly extract critical clauses, identify relevant statutes, and cross-reference documents with unprecedented accuracy. For healthcare, processing extensive patient records, research papers, and drug information becomes more feasible, aiding in diagnosis, treatment planning, and drug discovery. Customer service chatbots, powered by these advanced RAG systems, can provide more comprehensive and contextually aware responses, drawing from vast knowledge bases without incurring excessive costs or latency. In enterprise knowledge management, employees can query internal documents, training manuals, and historical data with greater confidence, knowing that the LLM is guided by the most relevant and precise information.
The goal is no longer simply to provide more context to an LLM, but to ensure that the model consistently focuses on the most relevant information within that context, while managing the computational and financial overhead. As LLM capabilities continue to advance, the sophistication of RAG systems will evolve in tandem, focusing on adaptive retrieval, multi-modal context understanding, and even more intelligent interaction with external knowledge sources. The future of AI-powered information systems hinges on this synergistic relationship, where the generative power of LLMs is meticulously guided and enriched by highly efficient and intelligent retrieval mechanisms.
References
- Stanford University & UC Berkeley Study on "Lost in the Middle" (2023). Specific citation details would be included here if available and publicly referenced in the original article. For this exercise, it serves as a placeholder for inferred data.
- Machine Learning Mastery. "Understanding RAG Part I: Why It’s Needed."
- IBM. "Large Language Models."
- Google DeepMind. "Gemini Pro."
- Anthropic. "Claude 3 Opus."
