
Amazon Web Services (AWS) today announced the general availability of Amazon Bedrock Managed Knowledge Base, a comprehensive suite of capabilities designed to empower developers to rapidly construct enterprise-grade generative artificial intelligence (AI) applications using their proprietary data. This new offering aims to significantly reduce the complexity associated with building and maintaining retrieval-augmented generation (RAG) pipelines, enabling organizations to deploy secure, reliable, and continuously updated AI solutions that deliver accurate, fast, and trustworthy outcomes. The introduction of Managed Knowledge Base represents a strategic move by AWS to abstract away the intricate infrastructure management typically required for RAG, allowing developers to concentrate on achieving business objectives rather than grappling with underlying technical complexities.
Addressing the Core Challenges in Enterprise RAG Development
The journey for developers in building robust knowledge bases for their AI agents has historically been fraught with significant hurdles. The rapid evolution of generative AI, while promising, has also highlighted a gap in accessible, scalable, and manageable infrastructure for integrating proprietary enterprise data. Traditionally, developers faced a tripartite challenge: the sheer complexity of assembling disparate infrastructure components, the time-consuming nature of data preparation for diverse data types, and the inherent difficulty in achieving high accuracy, especially for complex, multi-step user queries. These challenges often force development teams into repetitive, undifferentiated work, diverting valuable resources from application innovation.
Prior to this announcement, constructing a production-ready RAG pipeline involved manually selecting and integrating various components, including vector databases for storage and retrieval, embedding models for converting text into numerical representations, re-ranker models for optimizing search results, and foundation models for generating responses. Each of these components required careful configuration, ongoing maintenance, and expertise to ensure optimal performance and scalability. Furthermore, preparing enterprise data, which often resides in diverse formats across multiple sources like internal documents, databases, and collaboration platforms, demanded extensive data engineering efforts, including parsing, chunking, and metadata extraction. This often led to weeks or even months of experimentation to achieve acceptable retrieval accuracy.

Introducing a Unified, Managed Solution
Amazon Bedrock Managed Knowledge Base directly confronts these challenges by consolidating the multiple infrastructure components into a single, fully managed primitive. By default, the service automates the selection and management of essential elements such as a default embeddings model, a re-ranker model, and a foundational model. This eliminates the need for developers to painstakingly choose and maintain these components themselves, significantly accelerating the initial setup phase. This managed foundation is further enhanced by three core innovations that dramatically improve ease of use and accuracy: Smart Parsing, Agentic Retriever, and seamless integration with AgentCore Gateway.
Smart Parsing for Accurate Data Ingestion
One of the most critical and often overlooked aspects of building effective knowledge bases is the meticulous preparation of diverse data types for accurate retrieval. Enterprises house vast amounts of information in myriad formats—from PDFs and Word documents to web pages, spreadsheets, and internal wikis. Ensuring that this heterogeneous data is correctly ingested, parsed, and indexed is paramount for the downstream accuracy of any generative AI application.
Smart Parsing is designed to automate this complex process. Once a developer points Managed Knowledge Base to their enterprise data sources, the system intelligently determines the optimal parsing strategy for each specific data type and connector. This intelligent automation removes the burden of manual configuration, which traditionally consumed significant developer time and expertise. Smart Parsing employs a combination of advanced techniques:

- Deep Semantic Understanding: It goes beyond simple keyword matching, analyzing the contextual meaning of content to accurately extract key information and relationships within documents.
- Multi-Modal Data Processing: It handles not just text but also understands the structure of tables, images (through OCR), and other embedded elements within documents, ensuring a holistic representation of the data.
- Adaptive Chunking and Indexing: Rather than applying a one-size-fits-all approach, Smart Parsing dynamically adjusts chunking strategies based on document structure and content, optimizing for both retrieval relevance and the context window limitations of foundation models.
- Metadata Extraction and Enrichment: It automatically identifies and extracts relevant metadata from documents, such as author, date, department, and topic tags, which significantly enhances the precision of retrieval queries.
This automated and intelligent approach to data preparation is a game-changer, eliminating the weeks of experimentation typically required to achieve production-quality retrieval accuracy. It allows developers to onboard their proprietary data rapidly and reliably, while still preserving the flexibility to customize parsing rules when highly specialized requirements arise.
Agentic Retriever for Complex Query Resolution
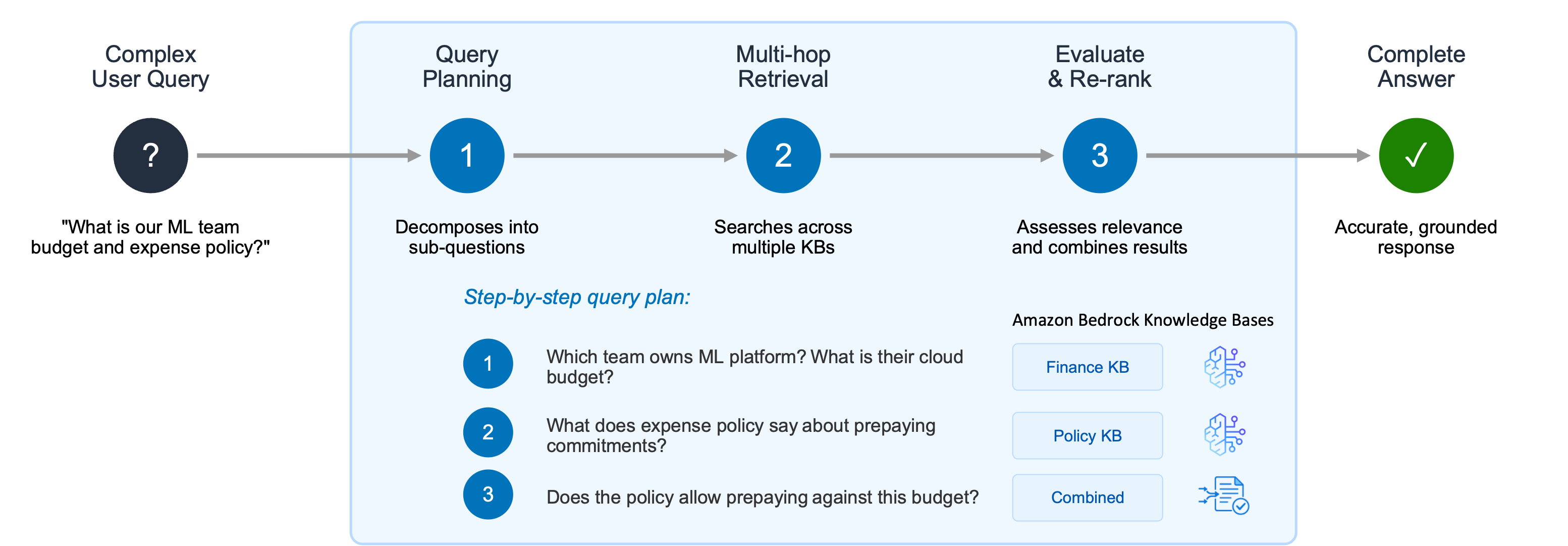
Traditional generative AI applications often struggle when confronted with complex user queries that demand multi-step reasoning, recursive retrieval across various data sources, and intermediate evaluations of results. A user inquiry like, "What is the cloud infrastructure budget for the ML platform team, and does our expense policy allow prepaying annual commitments related to such budgets?" exemplifies this challenge. A simplistic, single-step retrieval might pull documents related to the ML platform team or the expense policy independently, but fail to synthesize the information to provide a comprehensive, grounded answer.
The Agentic Retriever is designed specifically to address these sophisticated queries. It operates by creating a step-by-step query plan, effectively decomposing a complex request into a series of manageable sub-questions. For the example above, the Agentic Retriever would formulate a plan such as:
- Identify which team is responsible for the ML platform and ascertain their specific cloud infrastructure budget.
- Consult the enterprise expense policy to determine guidelines regarding prepaying annual commitments.
- Synthesize the findings to answer whether the ML platform team’s budget allows for prepaying annual commitments, considering the expense policy.
Crucially, the system performs multi-hop retrieval and reasoning at each step. It intelligently navigates across multiple knowledge bases or data segments, gathering relevant passages iteratively. This iterative process allows it to refine its search and understanding, stopping only when it has accumulated sufficient relevant information to formulate an accurate and grounded response. By abstracting away the complexity of building and orchestrating a separate multi-hop reasoning pipeline, the Agentic Retriever dramatically enhances accuracy for intricate queries, empowering developers to focus on the business logic of their agentic search applications rather than on complex orchestration logic. This capability can be tested directly within the Amazon Bedrock AgentCore console, where users can select "Agentic retrieval only" to observe the system’s ability to plan and execute multi-step queries automatically.
Seamless Integration with AgentCore Gateway and Model Agnosticism
Amazon Bedrock Managed Knowledge Base is engineered for seamless integration with AgentCore Gateway, serving as a native target type. This integration obviates the need for manual setup, automatically providing built-in observability, policy enforcement, and permission management. Developers can easily expose their knowledge bases through AgentCore Gateway, which in turn supports the standard Model Context Protocol (MCP). This adherence to MCP ensures that knowledge base tools are automatically discoverable by clients utilizing any MCP-compatible framework, including popular open-source tools like Strands Agents, LangChain, CrewAI, LlamaIndex, and LangGraph, without requiring custom integration code. This level of interoperability is critical for fostering a vibrant ecosystem and reducing vendor lock-in.
Furthermore, a significant advantage of Amazon Bedrock Managed Knowledge Base is its commitment to model choice and flexibility. Unlike some managed solutions that confine users to specific model providers, Bedrock’s approach separates infrastructure management (connectors, parsing, storage, retrieval orchestration) from model selection. This architectural design provides unparalleled flexibility:
- Foundation Model Choice: Every foundation model available on Bedrock can power the generation step, allowing enterprises to select the best-fit model for their specific use case, considering factors like performance, cost, and latency.
- Optimized Retrieval Models: Developers can choose from various embedding and re-ranking models to fine-tune retrieval accuracy. This enables teams to experiment and optimize for their unique data characteristics and query patterns without altering the underlying infrastructure.
- Future-Proofing: The platform supports swapping models as new, more capable, or more cost-effective models become available, ensuring that applications remain at the cutting edge without requiring costly re-architecting.
- Cost-Performance Optimization: The ability to select different models allows organizations to balance accuracy requirements with cost constraints, optimizing the overall cost-performance ratio of their generative AI applications.
This model-agnostic strategy ensures that developers can dedicate their time to refining their generative AI applications, secure in the knowledge that they retain the agility to adapt to evolving requirements and leverage the latest advancements in AI models.
Broader Context: The Evolution of Enterprise Generative AI
The launch of Amazon Bedrock Managed Knowledge Base arrives at a pivotal moment in the evolution of enterprise AI. As organizations increasingly recognize the transformative potential of generative AI, the focus has shifted from mere experimentation to the practical deployment of production-ready applications. A key barrier to this deployment has been the challenge of grounding large language models (LLMs) with up-to-date, accurate, and proprietary enterprise data. Generic LLMs, while powerful, lack the specific domain knowledge of individual companies, leading to "hallucinations" or irrelevant responses when queried about internal processes, policies, or customer data. RAG has emerged as the leading architectural pattern to overcome this limitation, allowing LLMs to retrieve information from a curated knowledge base before generating responses, thereby improving accuracy, relevance, and trustworthiness.
AWS has been a significant player in democratizing access to generative AI through Amazon Bedrock, which provides a fully managed service offering a choice of high-performing foundation models from leading AI companies, alongside tools to build and scale generative AI applications. The introduction of Managed Knowledge Base reinforces AWS’s commitment to simplifying the end-to-end generative AI development lifecycle, moving beyond just offering models to providing comprehensive tools for data integration and retrieval. This aligns with a broader industry trend of cloud providers offering increasingly sophisticated, managed services that abstract away complex AI infrastructure, making advanced capabilities accessible to a wider range of developers and businesses.
Market Impact and Future Outlook
The implications of Amazon Bedrock Managed Knowledge Base are significant for the enterprise AI landscape. By drastically lowering the technical barrier to implementing sophisticated RAG pipelines, AWS is poised to accelerate the adoption of generative AI across industries. Small and medium-sized enterprises, which may lack extensive in-house AI engineering teams, can now leverage these advanced capabilities with reduced overhead. Larger enterprises can reallocate their AI talent from infrastructure management to developing innovative applications that drive competitive advantage.
Industry analysts anticipate that this simplification will lead to a proliferation of more accurate, reliable, and contextually aware AI applications across various business functions, from enhanced customer service chatbots and intelligent internal knowledge management systems to sophisticated data analysis tools and personalized content generation platforms. The emphasis on model flexibility also positions AWS favorably, as it empowers customers to choose the best models for their specific needs, fostering innovation across the AI ecosystem rather than locking users into a single vendor’s offerings.
Looking ahead, the integration with AgentCore Gateway suggests a future where autonomous AI agents can seamlessly interact with and leverage enterprise knowledge bases, further automating complex workflows and decision-making processes. AWS’s ongoing investment in generative AI, coupled with its vast cloud infrastructure and developer community, indicates a continued trajectory towards making advanced AI capabilities more accessible and impactful for businesses worldwide.
Availability and Pricing Details
Amazon Bedrock Managed Knowledge Base is now available in multiple AWS Regions, including US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney, Tokyo), Europe (Dublin, Frankfurt, London), and AWS GovCloud (US-West) Regions. Customers interested in exploring regional availability and future roadmap updates can visit the AWS Capabilities by Region page.
The service operates on a pay-for-what-you-use model, with no upfront commitments. Pricing is structured around two primary dimensions: the volume of indexed data stored within the knowledge base and the number of retrievals performed (on-demand). Detailed pricing information is available on the Amazon Bedrock pricing page. Furthermore, Amazon Bedrock is included as part of the AWS Free Tier, allowing new AWS customers to explore these capabilities at no initial cost.
These newly released capabilities are designed to be highly interoperable, working seamlessly with popular open-source frameworks such as CrewAI, LangGraph, LlamaIndex, and Strands Agents, as well as with any foundation model supported by Bedrock. Developers can utilize Bedrock services independently or in conjunction with each other, initiating their projects within their preferred AI-assisted development environments using the AgentCore open-source MCP server. For comprehensive guidance and to begin using Amazon Bedrock Managed Knowledge Base, developers are encouraged to consult the Bedrock Knowledge Bases Developer Guide.
