
Amazon Web Services (AWS) today announced a significant advancement in data management capabilities for Amazon Simple Storage Service (Amazon S3) with the introduction of "annotations." This new metadata feature empowers organizations to embed rich, extensive business context directly alongside their S3 objects, addressing long-standing challenges in data discoverability, governance, and autonomous workflow enablement. The announcement marks a pivotal step in evolving how enterprises manage the vast and growing volumes of unstructured data stored in their cloud data lakes.
A New Era for Data Context in Cloud Storage
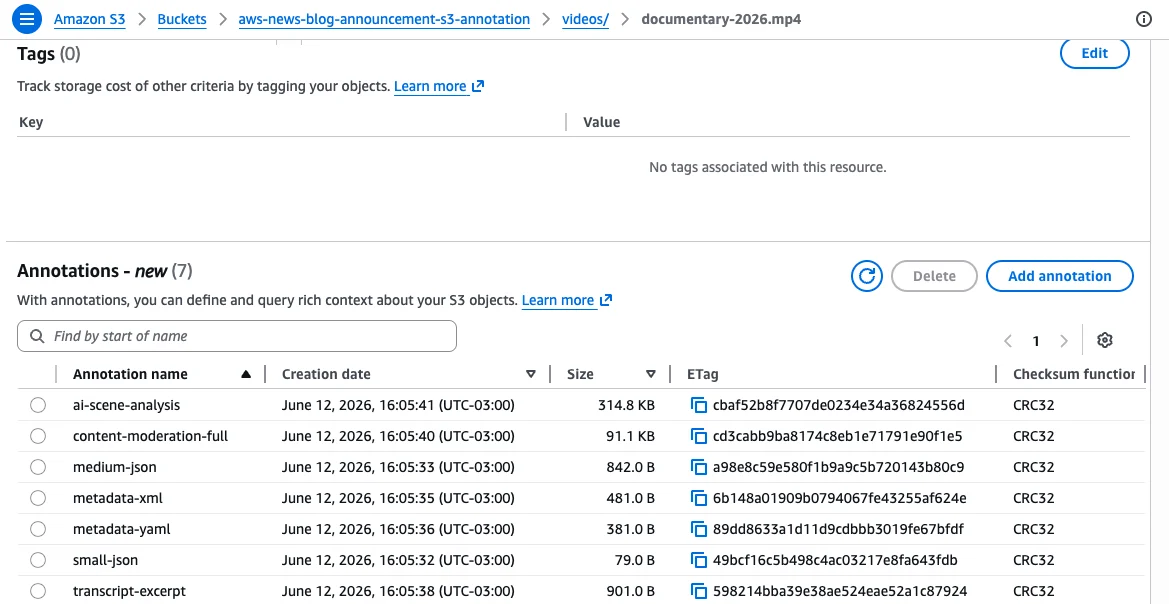
At its core, S3 annotations allow users to attach up to 1,000 named annotations per object, each capable of storing up to 1 MB of data. This translates to an impressive total of 1 GB of metadata per object, far exceeding previous S3 metadata limits. The flexibility to store annotations in widely adopted formats such as JSON, XML, YAML, or plain text is a critical differentiator, enabling diverse types of structured and unstructured context to be associated with data. Crucially, annotations can be modified or deleted at any time without requiring a rewrite of the underlying object, ensuring that metadata remains current and accurate throughout the object’s lifecycle. This mutability is a key enhancement for dynamic data environments, where context frequently evolves.
The proliferation of artificial intelligence (AI) agents and autonomous workflows has underscored an urgent need for data to be self-describing. These intelligent systems require robust, machine-readable metadata to efficiently find, comprehend, and act upon data without human intervention. Traditional metadata solutions often fall short in providing the scale, flexibility, and queryability necessary for petabyte-scale object stores. S3 annotations directly confront these limitations, providing metadata that can evolve synchronously with the data, scale to massive datasets, and remain readily queryable without incurring expensive retrieval costs.
Organizations can leverage S3 annotations to store a wide array of contextual information. This includes AI-generated transcripts for audio or video files, content ratings for media assets, technical specifications for engineering data, or compliance-related tags for regulated industries. A significant operational advantage is that this context automatically moves with the object during copy, replication, and cross-region transfers, simplifying data lifecycle management. Furthermore, S3 automatically removes annotations when the associated object is deleted, preventing orphaned metadata. When S3 Metadata is enabled, annotations seamlessly flow into fully managed annotation tables, which can then be queried using powerful analytics engines like Amazon Athena, unlocking unprecedented analytical capabilities.
Addressing Persistent Metadata Challenges
For years, AWS S3 has offered various methods to describe objects, each serving specific purposes but with inherent limitations. System-defined metadata, such as object size and storage class, provides immutable, fundamental properties. User-defined metadata allows for small, custom key-value pairs, but these are set at upload time and cannot be changed without re-uploading the object, typically limited to 2 KB. Object tags, while mutable and useful for operational tasks like access control, lifecycle management, and cost allocation, are restricted to 10 tags per object, each with character limits for keys and values (128 and 256 characters respectively).

While these existing capabilities have been effective for their intended uses, they posed significant hurdles when organizations needed to attach richer, more dynamic context to their data. The common workaround involved building and maintaining separate metadata systems—often external databases or sidecar files—which introduced complexity, synchronization challenges, potential data consistency issues, and often exceeded the cost of the actual data storage.
S3 annotations fundamentally redefines metadata capabilities by offering a different scale and flexibility. Unlike 10 immutable tags or a 2 KB header, annotations provide up to 1 GB of mutable, queryable context per object. This paradigm shift means that critical business intelligence, compliance information, or AI-derived insights no longer need to reside in disconnected systems. The following table highlights the distinct advantages of annotations compared to previous metadata options:
| Capability | Max Size | Mutable? | Best For |
|---|---|---|---|
| System-defined metadata | Fixed | No | Object properties (size, storage class, creation time) |
| User-defined metadata | 2 KB | No | Small custom key-value pairs (set at upload) |
| Object tags | 10 tags, 128/256 chars/key/value | Yes | Access control, lifecycle rules, cost allocation |
| Annotations | 1 GB (1,000 × 1 MB) | Yes | Rich business context (JSON, XML, YAML, plain text) |
The integration with S3 Metadata annotation tables ensures that this embedded context becomes queryable at scale through Amazon Athena. Furthermore, AI agents can now discover data through natural language queries, facilitated by the S3 Tables MCP server. This server provides a standardized interface, enabling AI models to interrogate annotations, drastically reducing the time and effort required for data discovery. A critical advantage is the ability to query annotations for objects in any storage class, including S3 Glacier, without the need to restore the objects or incur retrieval charges, offering substantial cost and time savings for archival data analysis.
Diverse Applications Across Industries
The introduction of S3 annotations is expected to have a transformative impact across a multitude of industries:
- Media and Entertainment: A media company, as illustrated by AWS, can attach technical specifications (e.g., codec, resolution, audio tracks, frame rate) and AI-produced summaries to video assets. Beyond this, annotations can store licensing information, director’s cuts, subtitle tracks in various languages, content ratings, and compliance metadata for global distribution. This streamlines content management, search, and automated processing pipelines.
- Healthcare and Life Sciences: For medical imaging or genomics data, annotations can store de-identified patient information, scan parameters (e.g., MRI sequence, dosage), research study identifiers, consent forms, and regulatory compliance flags (e.g., HIPAA, GDPR status). This facilitates secure data sharing, advanced analytics, and adherence to strict data governance policies.
- Financial Services: Annotations can be used to store detailed transaction metadata, audit trails, risk assessment scores, regulatory filing references, and compliance context (e.g., SOX, Basel III). This enables quicker identification of relevant data for audits, risk analysis, and regulatory reporting, reducing the manual effort involved in compliance.
- Manufacturing and Internet of Things (IoT): Sensor data streams can be annotated with device IDs, location data, calibration parameters, maintenance logs, quality control checks, and operational context. This empowers predictive maintenance, real-time analytics, and supply chain optimization by providing rich context to raw sensor readings.
- Scientific Research: Researchers can attach experiment parameters, data provenance, author details, publication references, analytical methodologies, and interim results to large datasets. This enhances reproducibility, facilitates collaboration, and improves the discoverability of research findings within large scientific consortia.
Getting Started: Implementation and Querying at Scale
To begin utilizing S3 annotations, users must ensure their AWS Identity and Access Management (IAM) policy or bucket policy grants permissions for the s3:PutObjectAnnotation and s3:GetObjectAnnotation actions. Annotations can then be added to any existing or new S3 object via the PutObjectAnnotation API.
For instance, using the AWS Command Line Interface (AWS CLI), a media company could attach mediainfo (structured JSON) and ai_summary (plain text) annotations to a video file:

# Create a JSON file with technical metadata
cat > mediainfo.json << 'EOF'
"codec":"H.265","resolution":"3840x2160","audio_tracks":8,"frame_rate":29.97
EOF
# Attach it as an annotation
aws s3api put-object-annotation
--bucket my-media-bucket
--key videos/documentary-2026.mp4
--annotation-name mediainfo
--annotation-payload ./mediainfo.json
# Attach a plain-text AI-generated summary as a separate annotation
echo "A 90-minute nature documentary covering wildlife migration patterns across three continents, featuring aerial footage and underwater sequences. Languages: English, Spanish, Portuguese." > ai_summary.txt
aws s3api put-object-annotation
--bucket my-media-bucket
--key videos/documentary-2026.mp4
--annotation-name ai_summary
--annotation-payload ./ai_summary.txtThese commands illustrate the ability to attach multiple, distinct annotations to a single object, each identified by a unique name. This design allows different teams or automated workflows to enrich objects concurrently without conflicts. Annotations can be retrieved using GetObjectAnnotation, listed using ListObjectAnnotations, and removed with DeleteObjectAnnotation. Updates are straightforward, requiring another call to PutObjectAnnotation with the same annotation name. For large objects uploaded via multipart upload, annotations are attached after the upload is complete.
The true power of S3 annotations is realized through large-scale querying. By enabling S3 Metadata annotation tables on a bucket, S3 automatically indexes annotations into a fully managed Apache Iceberg table. This annotation table, along with an optional journal table for near real-time change tracking, becomes queryable with Amazon Athena or any Iceberg-compatible engine.
Enabling annotation tables is done via the S3 console or the CreateBucketMetadataConfiguration API. A configuration example might look like this:
"JournalTableConfiguration":
"RecordExpiration": "Expiration": "DISABLED"
,
"InventoryTableConfiguration": "ConfigurationState": "DISABLED" ,
"AnnotationTableConfiguration":
"ConfigurationState": "ENABLED",
"Role": "arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"
Once enabled, new annotations appear in the table within approximately one hour. If enabled on an already annotated bucket, S3 backfills existing annotations, a process that can take hours to days depending on object count. Unlike traditional metadata tables that demand predefined schemas, annotation tables automatically adapt to the JSON, XML, or YAML structures of the annotations. Each annotation becomes a row in the table, with its content stored in a text_value column, allowing schema-less querying across all annotations.
This capability unlocks sophisticated queries. For example, to find all video assets in a bucket with more than 8 audio tracks:
SELECT DISTINCT bucket, object_key
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation"
WHERE name = 'mediainfo'
AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8For event-driven workflows, the journal table can track annotation changes in near real time:
SELECT bucket, key, version_id, record_timestamp, annotation.name
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."journal"
WHERE record_timestamp >= (current_date - interval '1' day)
AND annotation.name IS NOT NULL
AND record_type IN ('CREATE_ANNOTATION', 'DELETE_ANNOTATION')Furthermore, the integration with the S3 Tables MCP server allows for natural language querying, enabling users to ask questions like "find all PG-rated movies with Spanish subtitles from 2023" within environments like Amazon SageMaker Unified Studio, yielding results in seconds rather than hours of querying disparate systems.
Broader Implications and Strategic Value
The introduction of S3 annotations represents a strategic enhancement for AWS’s robust S3 service, reinforcing its position as the de facto standard for cloud object storage. This feature directly addresses the escalating complexity of data management in an era dominated by large-scale data lakes, machine learning, and autonomous systems. By enabling rich, mutable, and queryable metadata directly alongside objects, AWS is empowering organizations to:
- Accelerate AI/ML Workflows: Data discoverability is a critical bottleneck for AI/ML projects. Annotations, especially when queried via natural language, can drastically reduce the time data scientists spend finding and understanding relevant datasets.
- Enhance Data Governance and Compliance: The ability to embed detailed compliance context, retention policies, and data provenance information directly with objects simplifies audit trails and ensures adherence to regulatory requirements across diverse datasets.
- Reduce Operational Overhead and Costs: Eliminating the need for separate, custom-built metadata systems reduces development, maintenance, and synchronization costs. The ability to query annotations without object retrieval further optimizes expenses for large archival datasets.
- Foster Data Collaboration and Interoperability: Standardized, rich metadata facilitates better understanding and sharing of data across different teams, departments, and even external partners, improving data interoperability within large enterprises.
- Enable Smarter Data Automation: With more descriptive data, automated systems and agents can make more intelligent decisions about data processing, routing, and lifecycle management, leading to more efficient and resilient data pipelines.
An AWS spokesperson commented on the launch, stating, "Our customers have consistently expressed a need for more sophisticated ways to manage metadata at scale, especially as their data lakes grow and AI applications become central to their operations. S3 annotations is a direct response to this feedback, providing unprecedented flexibility and power to embed business context directly into their objects. This feature is not just about storing more metadata; it’s about making data inherently more intelligent and actionable for the next generation of autonomous workflows."
Availability and Pricing
Amazon S3 annotations are now generally available in all AWS Regions, including the AWS China Regions. Annotation tables are available in all AWS Regions where S3 Metadata is supported. Storage for annotations is consistently billed at S3 Standard rates, irrespective of the parent object’s storage class, even for objects residing in S3 Glacier. This simplifies cost management and provides predictable pricing.
This new capability is set to significantly streamline data management practices for organizations worldwide, enabling more intelligent, efficient, and compliant data operations in the cloud. For further details and to begin leveraging S3 annotations, users are encouraged to visit the Amazon S3 Metadata overview page and consult the comprehensive Amazon S3 documentation. Feedback and inquiries can be directed to AWS re:Post for S3 or through existing AWS Support channels.
