
A significant advancement in local artificial intelligence has emerged with the successful development of a privacy-first, tool-calling agent leveraging Google’s Gemma 4 model family and the Ollama local inference runner. This groundbreaking implementation demonstrates how advanced language model capabilities, traditionally confined to cloud-based systems, can now be deployed on consumer-grade hardware, ensuring robust data privacy and operational autonomy. The project, detailed in a recent technical article, showcases a zero-dependency Python architecture, enabling local execution of complex agentic workflows without reliance on external APIs or cloud infrastructure.
The Rise of Open-Weight Models and Google’s Gemma 4 Initiative
The landscape of artificial intelligence has been rapidly reshaped by the proliferation of open-weight models, offering unprecedented accessibility and control to developers. A pivotal moment in this evolution was the recent release of the Gemma 4 model family by Google. Positioned as a direct response to the community’s demand for powerful yet accessible AI, Gemma 4 variants were engineered to deliver frontier-level capabilities under a permissive Apache 2.0 license. This strategic move by Google empowers machine learning practitioners with complete sovereignty over their AI infrastructure and, critically, their data privacy, a growing concern in an increasingly data-driven world.
The Gemma 4 release is notable for its diverse range of models, catering to various computational requirements and application scenarios. This includes the parameter-dense 31B model, a structurally complex 26B Mixture of Experts (MoE) variant designed for high-performance tasks, and several lightweight, edge-focused iterations. Crucially for AI engineers, the Gemma 4 family features native support for agentic workflows. These models have been meticulously fine-tuned to reliably generate structured JSON outputs and natively invoke function calls based on explicit system instructions. This integrated capability transforms them from mere "reasoning engines" into practical, actionable systems capable of executing predefined workflows and interacting with external APIs locally, moving beyond mere conversational exchanges to tangible task execution.
The Paradigm Shift: Language Models as Autonomous Agents Through Tool Calling
Historically, language models operated as self-contained, closed-loop conversationalists. Their utility was primarily confined to generating text, summarizing information, or answering questions based solely on their internal training data. Queries requiring real-world, dynamic information—such as live sensor readings, current market rates, or up-to-the-minute news—would typically result in apologies for lack of external access or, worse, the generation of plausible but entirely fabricated (hallucinated) responses. This fundamental limitation restricted their application in dynamic, real-world scenarios.
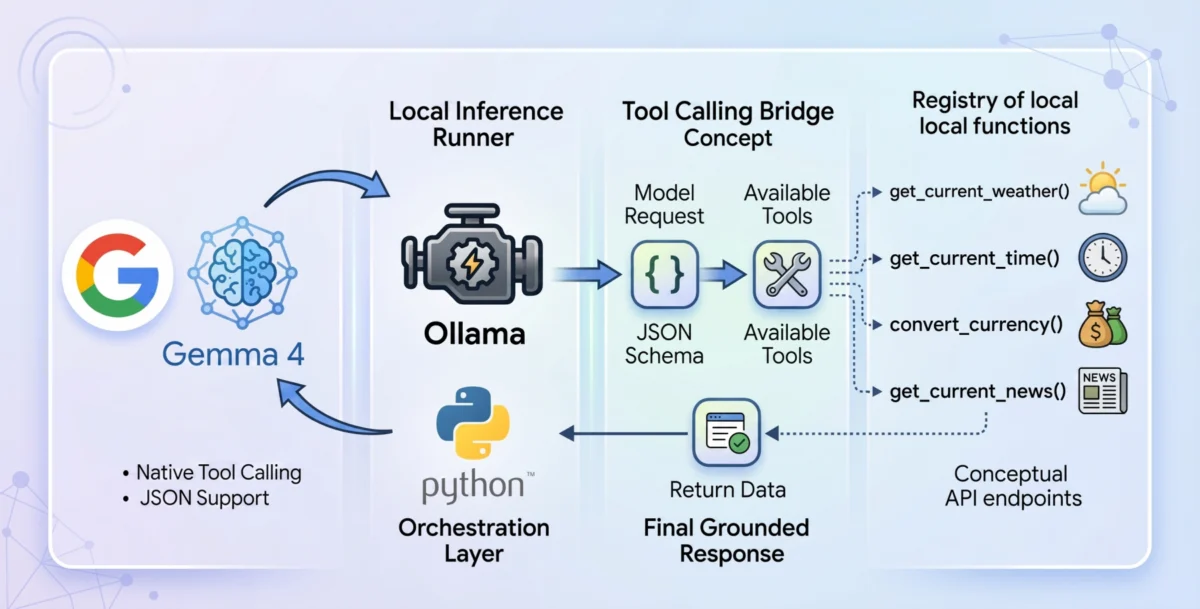
Tool calling, also known as function calling, represents a foundational architectural shift designed to bridge this critical gap. It serves as the essential mechanism that transforms static language models into dynamic, autonomous agents. When tool calling is enabled, the model intelligently evaluates a user prompt against a provided registry of available programmatic tools, typically defined via a JSON schema. Instead of attempting to infer an answer using only its internal weights, the model pauses its inference process. It then formulates a structured request specifically designed to trigger an external function, patiently awaiting the result. Once this external result is processed by the host application and fed back to the model, the model synthesizes this newly injected live context to formulate a grounded, accurate, and relevant final response. This iterative process allows the AI to extend its capabilities far beyond its initial training data, connecting it to the vast array of real-world information and services.
Building a Local Foundation: Ollama and Gemma 4:E2B for Privacy-First Operations
To construct a genuinely local and privacy-first tool-calling system, the project strategically selected Ollama as the local inference runner, paired with the gemma4:e2b (Edge 2 billion parameter) model. Ollama has emerged as a popular choice for running large language models locally, offering ease of setup and robust performance on a variety of hardware configurations. Its ability to serve models directly from a local machine is paramount for privacy, ensuring that sensitive data never leaves the user’s environment.
The gemma4:e2b model is particularly noteworthy. Specifically engineered for mobile devices and Internet of Things (IoT) applications, it represents a significant paradigm shift in what is achievable on consumer hardware. During inference, this model activates an effective 2 billion parameter footprint, a remarkable optimization that preserves system memory while achieving near-zero latency execution. This lean operational profile means the agent can run entirely offline, circumventing rate limits, API costs, and, most importantly, preserving strict data privacy by eliminating the need for data transmission to remote servers. Despite its incredibly compact size, Google has engineered gemma4:e2b to inherit the multimodal properties and native function-calling capabilities of its larger sibling, the 31B model. This makes it an ideal foundation for developing fast, responsive desktop agents, and crucially, allows developers to test the full range of capabilities of the new Gemma 4 family without requiring a high-end Graphics Processing Unit (GPU). This accessibility lowers the barrier to entry for local AI development, fostering innovation across a broader developer community.
Crafting the Agent: A Zero-Dependency Architectural Approach
The core philosophy guiding the implementation of this tool-calling agent was a commitment to zero-dependency. To orchestrate the language model and its various tool interfaces, the developers relied exclusively on standard Python libraries such as urllib for network requests and json for data serialization. This deliberate choice ensures maximum portability and transparency, preventing "dependency bloat" and simplifying deployment across different environments. The complete codebase for this tutorial has been made publicly available on a GitHub repository, promoting open collaboration and reproducibility.
The architectural flow of the application is meticulously designed for efficiency and clarity. Upon receiving a user query, the system initializes a JSON payload for the Ollama API. This payload explicitly specifies gemma4:e2b as the target model and dynamically appends a global array containing the parsed definitions of all available tools. This initial request allows the model to analyze the user’s intent in the context of the tools it has access to.
Tool Development: The ‘get_current_weather’ Example
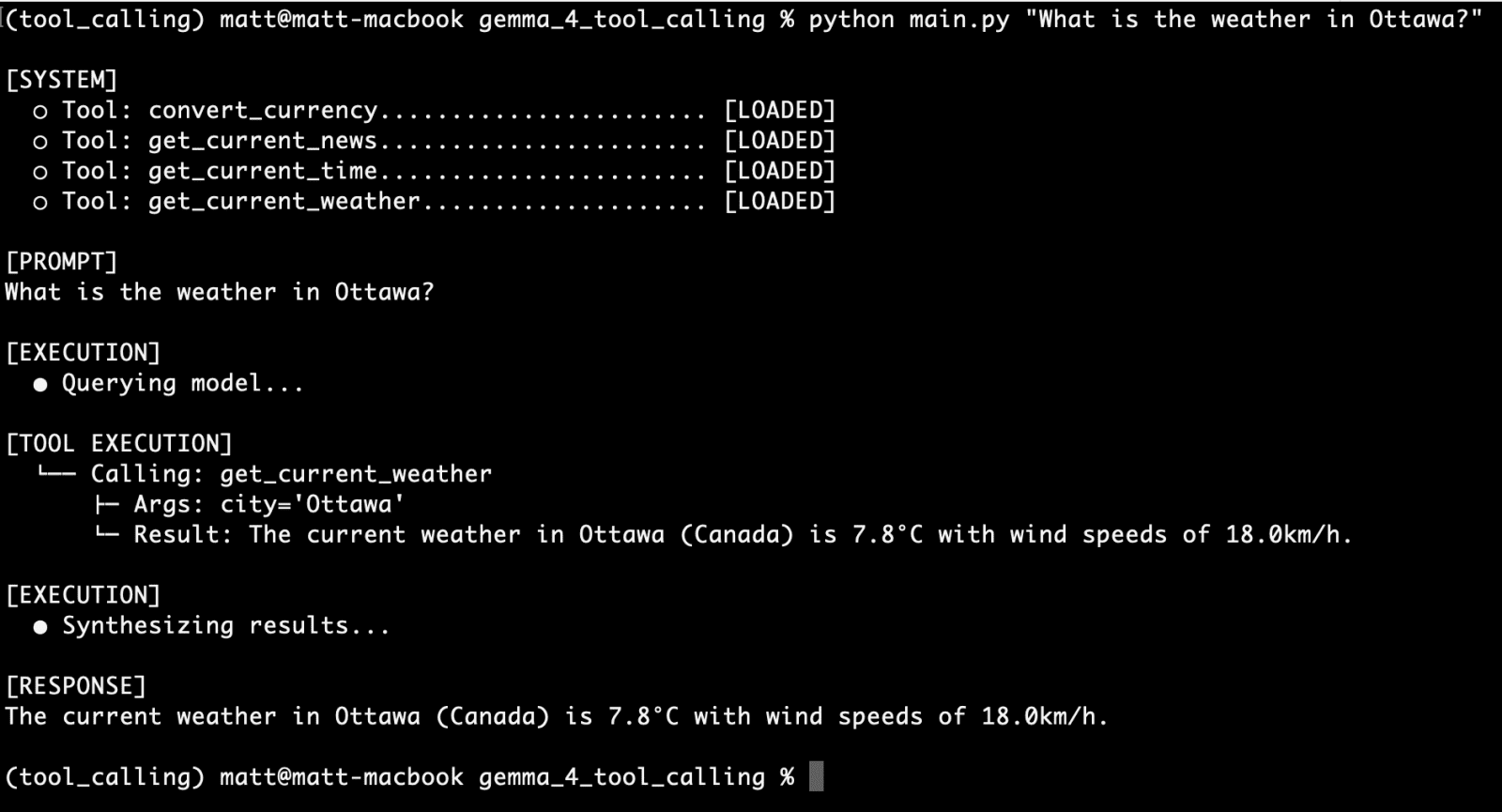
The efficacy of any tool-calling agent is directly proportional to the quality and utility of its underlying functions. A primary example developed for this agent is the get_current_weather function. This Python function interacts with the open-source Open-Meteo API to retrieve real-time weather data for a specified location. The function employs a two-stage API resolution pattern: standard weather APIs typically demand precise geographical coordinates, so get_current_weather transparently intercepts the city string provided by the model, geocodes it into latitude and longitude coordinates using a separate geocoding API endpoint, and then, with the coordinates formatted, invokes the Open-Meteo weather forecast endpoint. Finally, it constructs a concise, natural language string representing the current telemetry point, which can then be presented to the user.
However, writing the function in Python is only one part of the implementation. For the model to effectively utilize this tool, it must be visually informed of its existence and operational parameters. This is achieved by mapping the Python function into an Ollama-compliant JSON schema dictionary. This rigid structural blueprint is paramount for reliable function calling, as it explicitly details variable expectations (e.g., city as a string), strict string enums (e.g., unit accepting "celsius" or "fahrenheit"), and required parameters. Such precise definitions guide the gemma4:e2b weights into consistently generating syntax-perfect calls, minimizing errors and maximizing agent reliability.
Behind the Scenes: The Tool-Calling Orchestration Mechanism
The core of the autonomous workflow resides within the main loop orchestrator. Once the initial JSON payload is sent to the Ollama API and the web request resolves, the system critically evaluates the architecture of the returned message block. The process is not a blind assumption of text output. Instead, the model, acutely aware of the active tools, signals its desired outcome by attaching a tool_calls dictionary within its response if it determines that a tool is necessary to fulfill the user’s request.
If the tool_calls dictionary exists and contains valid function calls, the standard text synthesis workflow is temporarily paused. The system then parses the requested function name and its corresponding arguments (kwargs) dynamically from the dictionary block. It subsequently executes the associated Python tool using these parsed arguments. The live data returned from the tool’s execution is then injected back into the conversational array, formatted as a "tool" role message. This step is crucial for feeding the real-world context back to the language model.
A critical secondary interaction then occurs: once the dynamic result is appended as a "tool" role, the entire messages history (including the original user query, the model’s tool call, and the tool’s output) is bundled together and sent back to the Ollama API, triggering the model again. This second pass is what allows the gemma4:e2b reasoning engine to process and synthesize the telemetry strings it previously "hallucinated around," bridging the final gap to output the data logically and coherently in human-understandable terms. This multi-turn interaction is the essence of effective tool calling, enabling dynamic, context-aware responses.
Expanding Agent Capabilities: Diverse Functionality and Modular Growth
With the foundational architecture for tool calling firmly established, enriching the agent’s capabilities becomes a straightforward exercise in adding modular Python functions. Using the identical methodology described for get_current_weather, the project incorporated several additional live tools. While not explicitly detailed in the original excerpt, a robust agent would typically include functions like convert_currency (interacting with a currency exchange API), get_current_time (accessing a time zone API), and get_latest_news (querying a news API). Each new capability is processed through the JSON schema registry, expanding the baseline model’s utility without demanding complex external orchestration or introducing heavy dependencies. This modular approach allows for rapid expansion and customization of the agent’s skillset.
Rigorous Testing and Demonstrations of Reliability
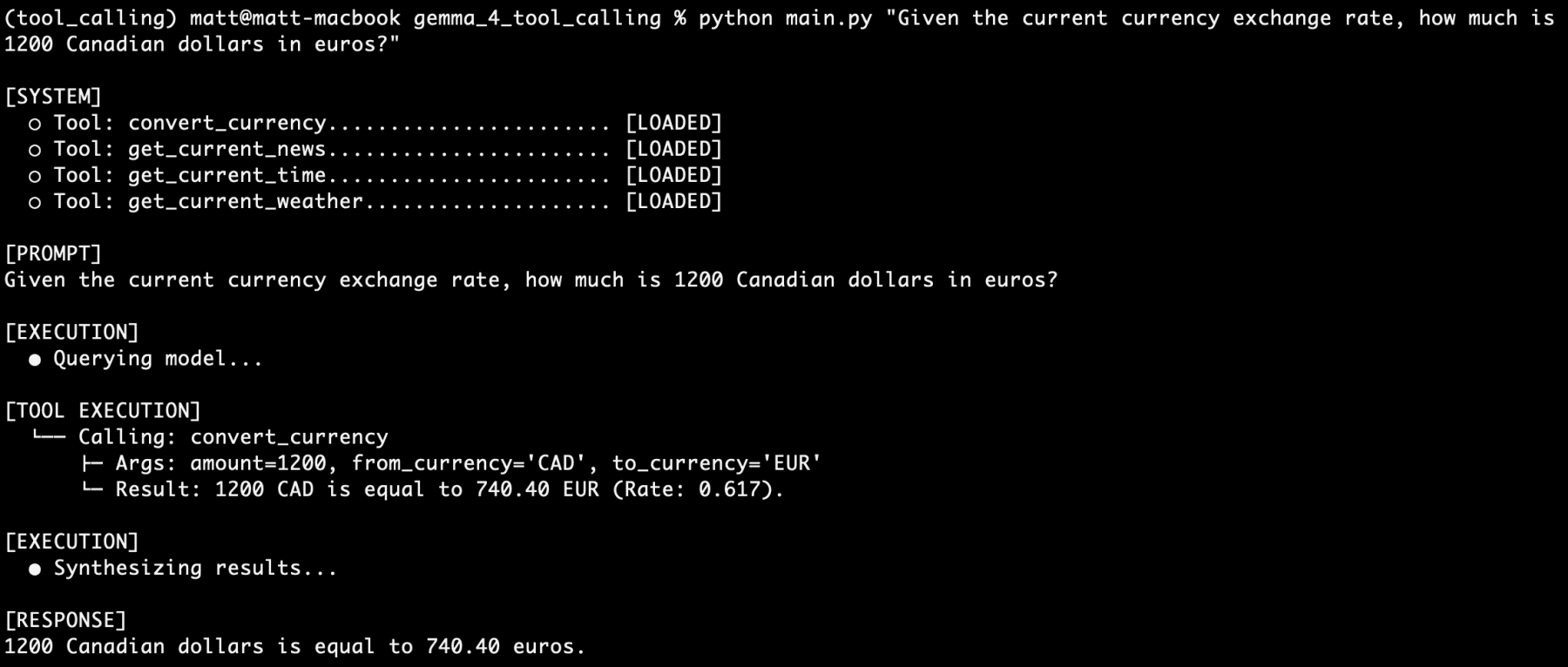
The true test of any AI agent lies in its performance and reliability under diverse querying conditions. The article highlights several successful test runs. For the get_current_weather function, a query like "What is the weather in Ottawa?" successfully triggered the tool, returned real-time data, and presented it to the user. Similarly, the convert_currency tool, when prompted with "Given the current currency exchange rate, how much is 1200 Canadian dollars in euros?", accurately calculated and reported the conversion.
The most impressive demonstration involved stacking multiple tool-calling requests within a single complex query: "I am going to France next week. What is the current time in Paris? How many euros would 1500 Canadian dollars be? what is the current weather there? what is the latest news about Paris?" In response, the gemma4:e2b agent successfully identified and executed calls to four different functions, providing accurate answers to each part of the multi-faceted query. This ability to handle complex, multi-tool requests from a single prompt underscores the sophisticated reasoning capabilities embedded within Gemma 4, even in its compact e2b variant. The developer reported running "hundreds of prompts" over a weekend, observing that "never once did the model’s reasoning fail." This consistent reliability, regardless of the vagueness or complexity of the reasonable wording, highlights Gemma 4’s robust performance in tool-calling scenarios.
Implications and the Future of Local AI Agents
The advent of native tool-calling behavior within open-weight models like Gemma 4 marks one of the most practical and impactful developments in local AI in recent times. The ability to operate securely offline, building complex systems unfettered by cloud and API restrictions, ushers in a new era of possibilities. By architecturally integrating direct access to the web, local file systems, raw data processing logic, and localized APIs, even low-powered consumer devices can now operate autonomously in ways previously restricted exclusively to cloud-tier hardware.
This breakthrough has profound implications for edge computing, IoT applications, and mobile AI. Businesses and individuals can now develop highly customized, private AI assistants and applications that keep sensitive data entirely on-device, mitigating privacy concerns and reducing operational costs associated with cloud services. The economic impact is significant, as developers can bypass recurring API fees and leverage readily available local computing resources. Furthermore, the demonstrated reliability of Gemma 4’s tool-calling capabilities suggests a near future where fully agentic systems, capable of orchestrating multiple tools and complex decision-making processes, become commonplace on personal devices. This development paves the way for a more personalized, secure, and efficient interaction with artificial intelligence, empowering users with unprecedented control and functionality directly from their local environments. The next logical step, as hinted by the developers, will be to build out a fully agentic system, further pushing the boundaries of what is achievable with local, privacy-first AI.
