
Amazon Web Services (AWS) has announced the launch of Amazon S3 Files, a groundbreaking new service designed to seamlessly integrate the robust capabilities of Amazon Simple Storage Service (Amazon S3) with the interactive, high-performance demands of file system access. This innovation marks a significant evolution in cloud storage, effectively bridging a long-standing architectural divide between object storage and traditional file systems, enabling any AWS compute resource to access S3 data as if it were local file storage.
The Evolution of Cloud Storage: Bridging a Decades-Old Divide
For over a decade, cloud architects and developers have grappled with the fundamental distinctions between object storage and file systems. Object storage, exemplified by Amazon S3, is renowned for its unparalleled scalability, durability, cost-effectiveness, and global accessibility. It stores data as immutable objects, each with a unique identifier and metadata, ideal for data lakes, backups, archives, and static content hosting. However, its object-centric nature meant that fine-grained, byte-level modifications or hierarchical directory structures, common in traditional file systems, were not natively supported. Editing a single byte in an S3 object typically required replacing the entire object, a process that could be inefficient for interactive workloads.
Conversely, file systems like those found on local servers or network-attached storage (NAS) devices provide hierarchical directory structures and support granular read/write operations, making them indispensable for applications requiring frequent data mutation, shared access, and traditional file-based interfaces. Until now, organizations often had to choose between the economic and durability benefits of S3 for massive data sets and the operational flexibility of a file system for active workloads, frequently leading to data duplication, complex synchronization mechanisms, and increased operational overhead. This trade-off often manifested as data silos, where data stored in S3 for archival or large-scale analytics would need to be moved or copied to a file system for processing by applications that required POSIX-compliant access.
Amazon S3 Files directly addresses this challenge by presenting S3 buckets as fully-featured, high-performance file systems. This eliminates the necessity of compromising on cost-efficiency, durability, or interactive capabilities, positioning S3 as the definitive central hub for all an organization’s data, accessible directly from virtually any AWS compute instance, container, or function.

Unpacking Amazon S3 Files: Features and Capabilities
At its core, S3 Files allows S3 objects to be accessed and manipulated as files and directories, supporting a comprehensive suite of Network File System (NFS) v4.1+ operations. This includes standard commands such as creating, reading, updating, and deleting files, enabling existing applications and tools that rely on file system semantics to interact directly with S3 data without modification.
A key aspect of S3 Files’ architecture is its intelligent data management. When specific files and directories are accessed through the file system, their associated metadata and contents are automatically placed onto a high-performance storage layer. This layer is designed to deliver ultra-low latencies, typically around 1 millisecond (ms), for actively used data. For files that benefit from high throughput, such as those requiring large sequential reads but not frequent random access, S3 Files intelligently serves them directly from Amazon S3. This dynamic approach optimizes performance based on access patterns, ensuring that interactive workloads receive low-latency access while large-scale data transfers leverage S3’s native throughput capabilities. Furthermore, for byte-range reads, only the requested bytes are transferred, significantly minimizing data movement and associated costs.
The system also incorporates intelligent pre-fetching mechanisms, anticipating future data access needs to further enhance performance. Users retain fine-grained control over what data is cached on the high-performance storage, with options to load full file data or metadata only, allowing for precise optimization tailored to specific application requirements.
Operational Simplicity and Integration
Integrating S3 Files into existing AWS environments is designed to be straightforward. The service supports attachment to a wide array of AWS compute resources, including Amazon Elastic Compute Cloud (Amazon EC2) instances, containers running on Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS), and AWS Lambda functions. This broad compatibility ensures that developers and data scientists can leverage S3 Files across their entire application ecosystem.

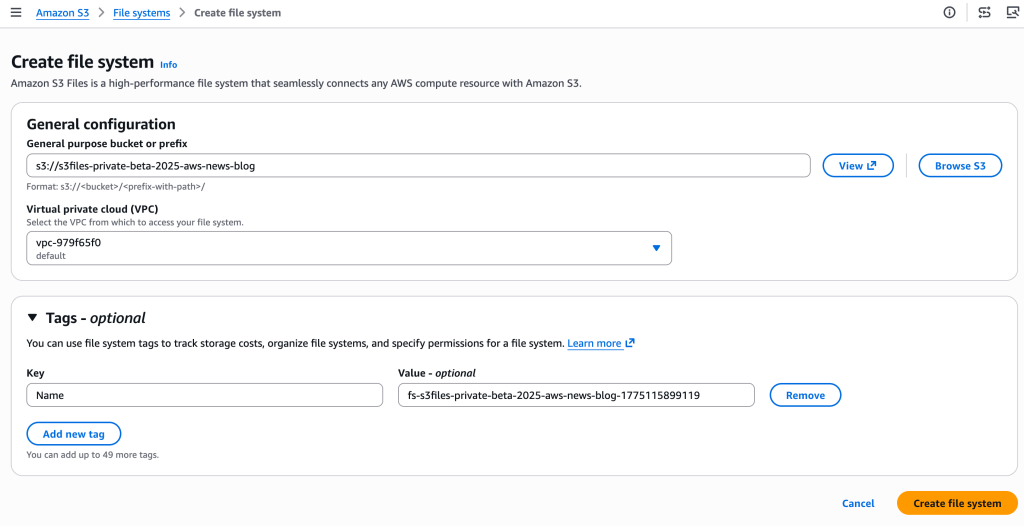
Setting up an S3 file system involves a few intuitive steps, achievable through the AWS Management Console, AWS Command Line Interface (AWS CLI), or Infrastructure as Code (IaC) tools. Users simply designate an existing general-purpose S3 bucket, and S3 Files provisions the necessary infrastructure, including mount targets within their Virtual Private Cloud (VPC). These mount targets act as network endpoints, allowing compute instances to connect to the S3 file system using standard NFS commands.
Once mounted, users can interact with their S3 data using conventional file system operations. For instance, creating a file within the mounted directory automatically triggers the creation of a corresponding object in the S3 bucket. Updates made to files in the file system are automatically reflected as new versions or new objects in the S3 bucket within minutes, ensuring data consistency and leveraging S3’s robust versioning capabilities. Similarly, changes made directly to objects in the S3 bucket become visible in the file system within seconds, though occasional delays of a minute or more can occur. This automatic, bi-directional synchronization removes the manual overhead previously associated with managing data across different storage types.
Real-World Applications and Use Cases
The introduction of S3 Files unlocks new possibilities and significantly enhances existing workflows across various industries and use cases:
- Machine Learning (ML) Training and Inferencing: ML workloads often require rapid access to large datasets and the ability to frequently update model parameters or intermediate results. S3 Files allows ML engineers to store vast datasets in S3, leveraging its cost-effectiveness and scalability, while providing their training pipelines and agentic AI systems with the low-latency, file-system access required for efficient model development and deployment. This is particularly beneficial for iterative training, where models frequently read and write to shared data.
- Agentic AI Systems: Emerging agentic AI architectures, which rely on AI agents collaborating through file-based tools and scripts (e.g., Python libraries, shell scripts), can now leverage S3 Files. This provides a persistent, shared, and high-performance file system interface where agents can store their states, exchange information, and access tools, all backed by the durability and scalability of S3.
- Production Applications: Many legacy and modern production applications are designed to interact with file systems. S3 Files enables these applications to directly utilize S3 as their primary data store without extensive re-architecting, benefiting from S3’s inherent resilience and cost advantages. This is particularly valuable for applications that require shared, concurrent access to data across multiple compute instances or containers.
- Data Analytics and Processing: For data analysis pipelines that involve multiple stages of processing, where intermediate results are frequently read, modified, and written back, S3 Files streamlines the workflow. It eliminates the need to move data between S3 and temporary file systems, simplifying data governance and reducing latency.
- Shared Data Access Across Clusters: S3 Files supports concurrent access from multiple compute resources, ensuring NFS close-to-open consistency. This makes it an ideal solution for collaborative workloads where multiple users or applications need to read and write to the same dataset simultaneously, without the complexity and cost of data duplication across clusters.
A Deeper Dive into the Technology
Under the hood, Amazon S3 Files leverages the proven technology of Amazon Elastic File System (Amazon EFS). EFS is a fully managed, scalable, and highly available NFS file system service, known for its low latency and ability to scale to petabytes of data while offering multi-AZ redundancy. By building on EFS, S3 Files inherits a robust, performant, and reliable foundation for its high-performance storage layer. This strategic integration means customers benefit from the best of both worlds: the cost-efficiency and immense scale of S3 combined with the interactive performance and file system semantics of EFS.
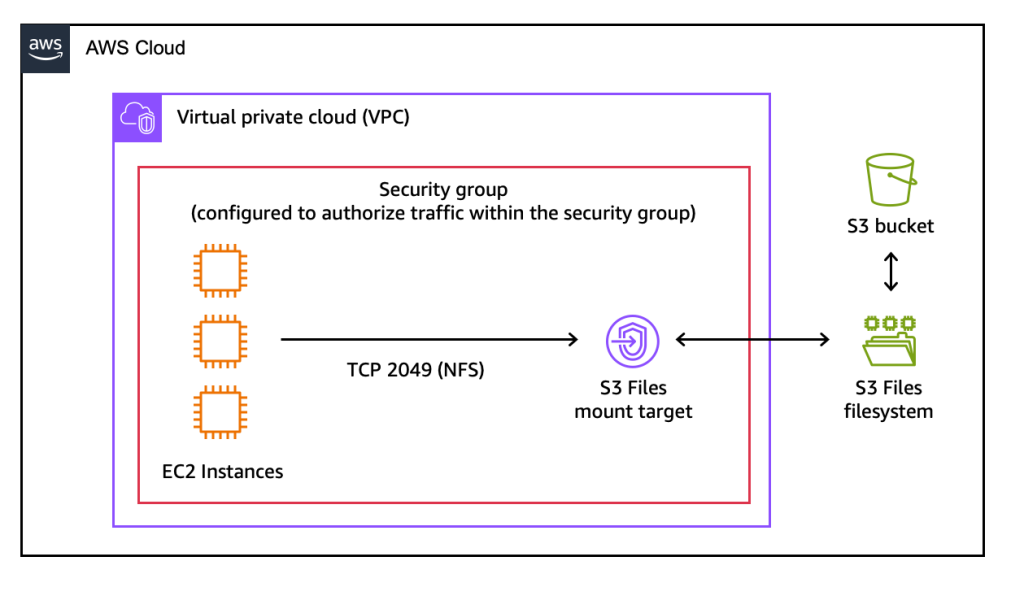
The service’s support for NFS v4.1+ is crucial, as it provides a widely adopted, industry-standard protocol for network file sharing. This ensures broad compatibility with various operating systems and applications, simplifying adoption for existing IT environments. The intelligent caching and pre-fetching mechanisms are critical for achieving the advertised sub-millisecond latencies for active data, as they reduce the need to constantly retrieve data from the potentially higher-latency S3 backend. This sophisticated caching strategy, combined with byte-range read optimization, minimizes data transfer costs and maximizes efficiency.
Strategic Positioning: S3 Files vs. AWS’s Broader Storage Portfolio
AWS offers a comprehensive suite of storage services, each optimized for different use cases. With the introduction of S3 Files, understanding the nuances between these services becomes even more pertinent for cloud architects.
-
Amazon S3 Files: Best suited for interactive, shared access to data residing in Amazon S3, especially for workloads that frequently read, write, and mutate data collaboratively. It’s ideal when the primary data store is S3, and applications require a file system interface with low-latency access for active data, automatic synchronization, and concurrent access across compute clusters without data duplication. This includes agentic AI, ML training with S3-backed datasets, and production applications that can leverage S3’s cost and durability benefits.
-
Amazon Elastic File System (EFS): While S3 Files leverages EFS technology, EFS itself remains a distinct service. EFS is a fully managed NFS file system that provides scalable, elastic, and highly available file storage for Linux-based workloads. It’s excellent for shared file access across EC2 instances, containerized applications, and serverless functions where persistent, POSIX-compliant file storage is needed and the primary data doesn’t necessarily originate from or need to reside long-term in S3 objects. EFS is often chosen for general-purpose file storage, web serving, and content management systems.
-
Amazon FSx Family: This family of services provides fully managed third-party file systems for specialized workloads requiring specific features or performance characteristics.
- Amazon FSx for Lustre: Designed for high-performance computing (HPC) and machine learning workloads, offering extreme throughput and low latency for large datasets. It’s often used for scratch space or processing large scientific datasets.
- Amazon FSx for Windows File Server: Provides fully managed, highly available file storage accessible via the Server Message Block (SMB) protocol, ideal for Windows-based applications and environments, including Microsoft SQL Server, home directories, and corporate file shares.
- Amazon FSx for NetApp ONTAP: Offers the familiar features and protocols of NetApp ONTAP file systems, including advanced data management features like snapshots, replication, and data deduplication, catering to enterprises with existing NetApp investments or specific data management requirements.
- Amazon FSx for OpenZFS: Delivers high-performance, open-source ZFS file systems with advanced data management features, suitable for demanding Linux workloads that require high IOPS, low latency, and efficient data compression.
In essence, S3 Files simplifies architectures by eliminating the need to choose between S3’s object storage benefits and a file system’s interactive capabilities when the data’s ultimate home is S3. For workloads migrating from on-premises NAS or requiring specialized file system features beyond NFS v4.1+, the FSx family remains the go-to solution.
Pricing Structure and Global Availability
Amazon S3 Files is now globally available in all commercial AWS Regions, enabling organizations worldwide to leverage this new capability. The pricing model for S3 Files is transparent and designed to reflect its hybrid nature. Customers pay for:
- The portion of data actively stored in the S3 file system’s high-performance layer, which benefits from EFS-like performance characteristics.
- Small file read and all write operations performed directly on the file system.
- S3 requests incurred during the automatic data synchronization process between the S3 file system and the underlying S3 bucket.
Detailed pricing information, including specific rates for storage, operations, and data synchronization, is available on the Amazon S3 pricing page. This pay-as-you-go model ensures that costs scale with actual usage, providing flexibility and cost predictability.
Industry Implications and Future Outlook
The launch of Amazon S3 Files is more than just a new service; it represents a significant architectural shift in cloud data management. By unifying the capabilities of object and file storage under the S3 umbrella, AWS is poised to simplify cloud architectures, reduce operational complexity, and accelerate innovation across various domains.
For organizations previously constrained by the dual nature of cloud storage, S3 Files offers a pathway to consolidated data strategies. It eliminates data silos, reduces the need for manual data movement, and streamlines application development by allowing direct access to S3 data through familiar file system interfaces. This is particularly impactful for the rapidly evolving fields of AI and ML, where data accessibility and efficient processing are paramount. As agentic AI systems become more prevalent, the ability to store vast amounts of data in S3 while providing agents with low-latency, file-based access will be critical for their performance and scalability.
Looking ahead, S3 Files reinforces Amazon S3’s position as the foundational data store for the cloud, capable of supporting an even broader spectrum of workloads. Its introduction is expected to foster new patterns of application development and data interaction, further blurring the lines between different storage paradigms and enabling customers to extract more value from their data with greater ease and efficiency. This strategic move by AWS solidifies its commitment to continuously evolve its cloud infrastructure to meet the increasingly complex and diverse needs of its global customer base.
