
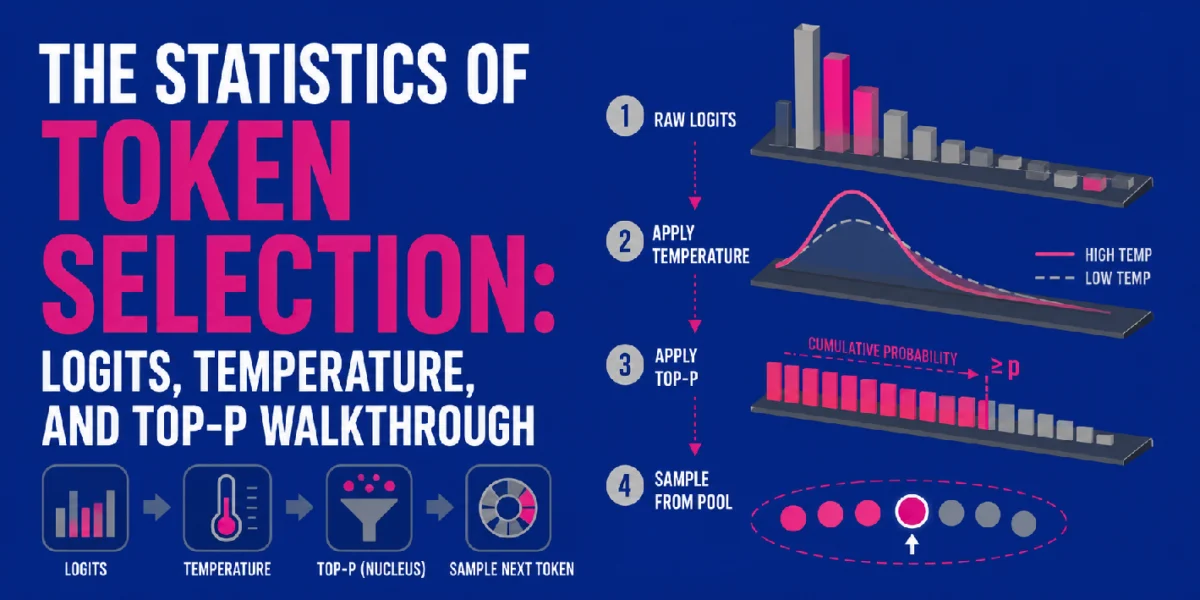
The burgeoning field of artificial intelligence, particularly the advancements in large language models (LLMs), has captivated global attention. These sophisticated systems, capable of generating human-like text, operate on a fundamental principle: predicting the next most probable token in a sequence. However, merely predicting the most probable token would lead to sterile, repetitive, and ultimately unengaging outputs. The true artistry and utility of LLMs lie in the nuanced control over this prediction process, orchestrated by key statistical parameters: logits, temperature, and top-p sampling. Understanding how these elements interact is crucial for anyone seeking to comprehend the underlying mechanics that transform raw computational power into coherent, creative, and contextually relevant language. This article delves into the intricate dance of these parameters, revealing their individual roles and their synergistic effect in shaping the probabilistic landscape of next-token prediction, thereby dictating the very character of an LLM’s output.
The Foundational Role of Logits: The Model’s Raw Assessment
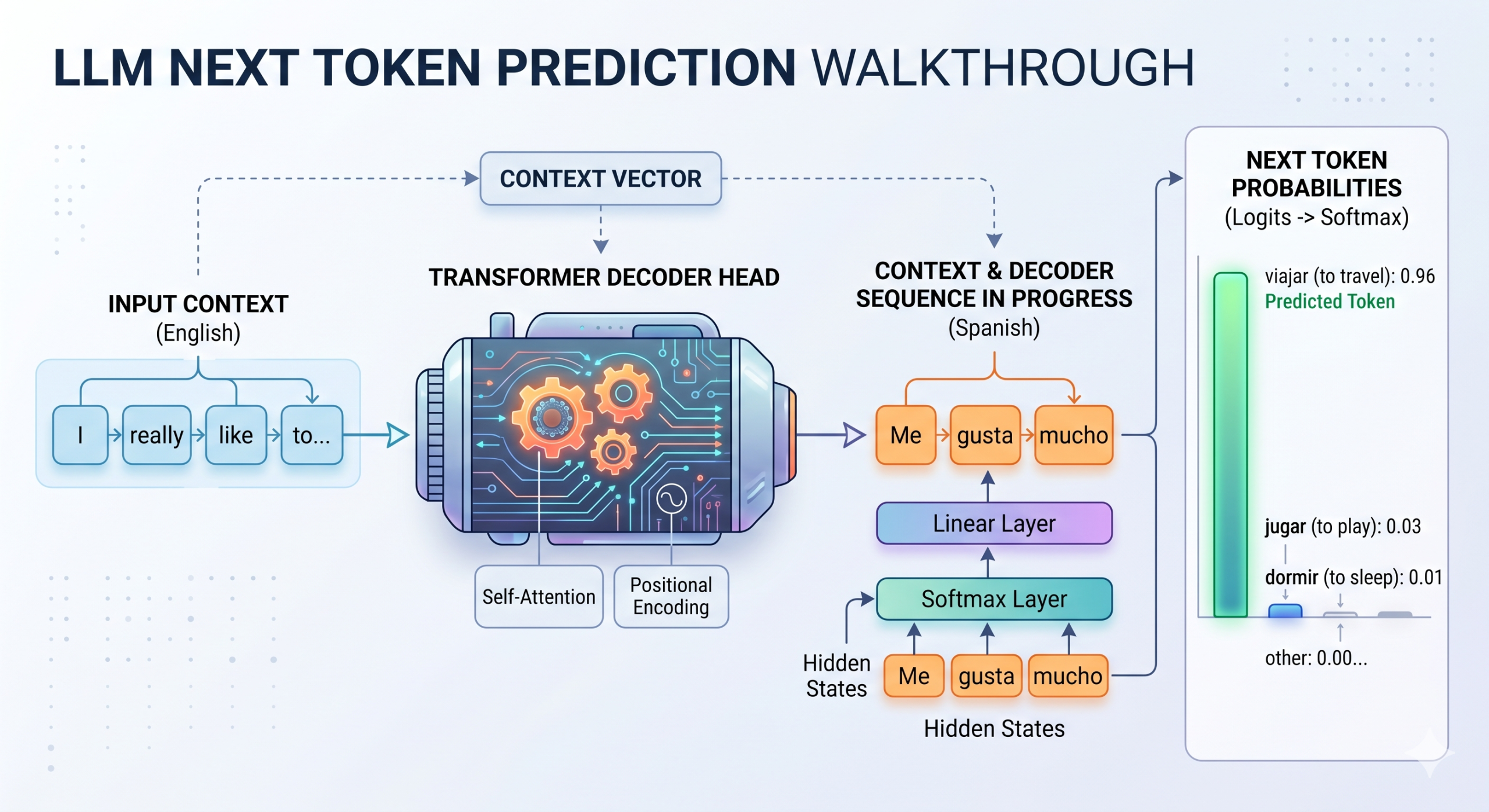
At the very core of any large language model’s generative process are logits. These are the raw, unnormalized scores produced by the model’s final linear layer, reflecting its internal assessment of the likelihood of each potential next token. Unlike probabilities, which are bounded between 0 and 1 and sum to 1, logits are unbounded values, ranging from negative infinity to positive infinity. A higher logit score for a particular token indicates that the model perceives it as more plausible given the preceding context.
In the intricate architecture of transformer models, which form the backbone of most modern LLMs, the journey to producing logits begins with the processing of "hidden states." These hidden states are rich, numerical representations that encapsulate the gradually accumulated linguistic knowledge and contextual understanding of the input text gathered throughout the transformer’s many layers. The final linear layer then takes these hidden states and projects them into a vector of logits. The dimensionality of this vector is staggering, corresponding precisely to the model’s entire vocabulary size. For state-of-the-art LLMs, this can mean a vocabulary encompassing anywhere from 50,000 to over 100,000 distinct tokens, each receiving a unique logit score for every prediction step.
Consider an LLM trained for English-to-Spanish translation, tasked with completing the sequence "me gusta mucho" (I really like to). The model might assign a logit score of 12.5 to "viajar" (travel), 8.2 to "jugar" (play), and a significantly lower, even negative, score like -3.1 to "dormir" (sleep). These raw values, while indicative of relative preference, are not directly interpretable as probabilities. They are, however, the fundamental building blocks upon which all subsequent probability calculations and sampling decisions are made. The critical next step, therefore, involves transforming these logits into a standard, interpretable probability distribution over the entire vocabulary, a process typically achieved through the application of a softmax function. This normalization ensures that all token probabilities sum to one, providing a clear and coherent basis for selection.
From Determinism to Nuance: The Evolution of Decoding Strategies
The journey to sophisticated token selection methods has been an evolutionary one, driven by the persistent challenge of making LLM outputs both coherent and diverse. Early decoding strategies, while computationally straightforward, often sacrificed quality for simplicity.
One of the most basic approaches is Greedy Decoding. As its name suggests, this method simply selects the token with the highest probability at each step. While seemingly logical, greedy decoding suffers from significant drawbacks. It often leads to highly repetitive, predictable, and sometimes locally optimal but globally suboptimal text sequences. The model might get stuck in a loop or fail to explore more creative and ultimately more fitting continuations. For example, if a model is asked to write a story, greedy decoding might produce a narrative that lacks imagination or gets bogged down in reiterating the same phrases.
An improvement over greedy decoding is Beam Search. Instead of tracking only the single most probable token at each step, beam search maintains a "beam" of the k most probable partial sequences (or "hypotheses"). At each step, it expands all k sequences by considering the next most probable tokens, then prunes them back to the top k new sequences. This allows the model to explore multiple potential paths simultaneously, often leading to more grammatically correct and coherent outputs than greedy decoding. However, beam search still tends to favor safe, common phrases and can struggle with generating truly novel or creative text. Its inherent bias towards high-probability sequences often results in generic outputs, suitable for tasks like machine translation where accuracy is paramount, but less so for creative writing.
The limitations of these deterministic approaches spurred the development of sampling methods. The realization that injecting an element of randomness could unlock greater diversity and creativity marked a pivotal shift. However, pure random sampling from the full softmax distribution presented its own set of problems. Even very low-probability tokens could be selected, potentially leading to nonsensical or irrelevant output. This is where parameters like temperature and top-p emerged as crucial tools, designed to guide and refine the sampling process, striking a delicate balance between predictability and exploratory generation. These innovations, largely developed alongside the rise of transformer architectures in the late 2010s, have been instrumental in making LLMs as versatile and powerful as they are today.
Temperature: Sculpting the Probability Landscape
Temperature is arguably one of the most intuitive and powerful hyperparameters in controlling the stochasticity of LLM outputs. It is applied before the softmax function, directly scaling the raw logits. Its primary function is to redistribute the probabilities, either sharpening or flattening the distribution over possible next tokens.
The mechanism is straightforward: the raw logits are divided by the temperature value (T).
-
Low Temperature (e.g., 0.1 to 0.5): When
Tis less than 1, it effectively magnifies the differences between logit scores. A small difference in raw logits becomes a larger difference in scaled logits, and subsequently, an even larger difference in the final probabilities after softmax. This results in a "sharper" probability distribution, where the highest-probability tokens become overwhelmingly more likely to be chosen. For instance, if a token has a logit of 10 and another has 9, withT=0.1, their scaled logits become 100 and 90, creating a vast gap in relative probability. This leads to more deterministic, focused, and predictable outputs, minimizing randomness. In practical terms, a model with a very low temperature might always choose "cat" after "the black," even if "dog" was a close second.
-
High Temperature (e.g., 0.7 to 1.0+): When
Tis greater than 1, it "smooths out" the logit differences. Dividing by a larger number reduces the relative gap between high and low logit scores. This results in a "flatter" probability distribution, where even tokens with moderately lower raw logits receive a more substantial probability share. For example, if the logits are 10 and 9, withT=1.0, they remain 10 and 9, but ifT=2.0, they become 5 and 4.5. This allows for a richer variety of tokens to be sampled, increasing creativity, diversity, and sometimes unexpected outputs. A very high temperature might lead to more "surprising" or even nonsensical word choices, as it amplifies the chances of less probable tokens.
A temperature of T=1.0 is often considered the baseline, where logits are used directly in the softmax calculation without scaling. A temperature of T=0 effectively collapses the distribution to a single point, always selecting the token with the highest logit, essentially mimicking greedy decoding after softmax.
The choice of temperature is a critical decision for developers, directly impacting the user experience. For applications requiring factual accuracy and minimal deviation, such as legal document generation, code completion, or precise summarization, a low temperature is preferred. Conversely, for creative tasks like poetry generation, brainstorming, or fiction writing, a higher temperature can unlock a wider range of linguistic expression and imaginative outcomes.
Top-P (Nucleus Sampling): Focusing the Creative Spark
While temperature adjusts the overall shape of the probability distribution, Top-P sampling, also known as Nucleus Sampling, provides a more dynamic and adaptive mechanism for filtering the candidate tokens from which to sample. It operates after the softmax function has converted scaled logits into probabilities.
Top-P works by identifying the smallest set of tokens whose cumulative probability exceeds a specified threshold p. The process is as follows:
- All tokens in the vocabulary are sorted in descending order based on their assigned probabilities.
- The model then iteratively sums these probabilities, starting from the most likely token.
- Once the cumulative sum reaches or exceeds the threshold
p, all tokens beyond that point are discarded from the candidate pool. - Finally, the next token is randomly sampled only from this reduced "nucleus" of most probable tokens.
This approach offers a significant advantage over its predecessor, Top-K sampling (which simply selects the K most probable tokens, regardless of their individual probabilities). Top-P dynamically adjusts the size of the candidate pool based on the sharpness of the probability distribution. If the distribution is very sharp (e.g., after a low temperature), only a few tokens might be needed to reach p=0.9. If the distribution is flatter (e.g., after a high temperature), many more tokens might be included in the nucleus. This adaptability ensures that the model can still explore diverse options when appropriate, without risking the selection of extremely low-probability, irrelevant tokens that might exist in the long tail of the distribution.
For example, if the probabilities for possible next tokens are: "travel" (0.6), "play" (0.2), "sleep" (0.1), "eat" (0.05), "read" (0.03), and "fly" (0.02), and p is set to 0.9.
- "travel" (0.6) – Cumulative: 0.6
- "play" (0.2) – Cumulative: 0.8
- "sleep" (0.1) – Cumulative: 0.9
At this point, the cumulative probability has reached 0.9. So, the nucleus for sampling would only include "travel," "play," and "sleep." All other tokens ("eat," "read," "fly") would be excluded, even though they have non-zero probabilities. This effectively prunes the search space to the most semantically relevant and probable options, while still maintaining an element of choice.
Top-P sampling is particularly effective at balancing randomness with coherence. It prevents the model from generating utter nonsense by excluding tokens from the extreme tail of the probability distribution, while simultaneously fostering creativity by allowing sampling from a diverse yet plausible set of options. Together, temperature and top-p provide a powerful tandem for fine-tuning the generative behavior of LLMs.
The Integrated Decoding Pipeline: A Multi-Step Process
The mechanisms of logits, temperature, and top-p are not isolated but form a sequential, multi-step pipeline that culminates in the selection of the next token. This integrated process ensures that LLM outputs are not only statistically sound but also align with desired characteristics of relevance, coherence, and creativity.
The full walkthrough can be visualized as follows:
-
Logit Generation: The process begins when the LLM, having processed the preceding sequence of tokens, outputs a vector of raw, unnormalized logits. Each logit corresponds to the model’s internal score for every possible token in its vast vocabulary. These scores are a direct reflection of the model’s learned patterns and contextual understanding.
-
Temperature Scaling: Before these logits can be converted into probabilities, they undergo a crucial scaling step based on the specified temperature parameter. Each raw logit is divided by the temperature value. As discussed, a low temperature will sharpen the differences between logits, making the highest-scoring tokens even more dominant. A high temperature will flatten these differences, giving lower-scoring tokens a more equitable chance. This step fundamentally reshapes the underlying distribution before probabilities are even calculated.
-
Softmax Normalization: The scaled logits are then fed into a softmax function. This mathematical operation transforms the unbounded scaled logits into a proper probability distribution. The output is a vector where each element represents the probability of a specific token being the next in the sequence. All these probabilities are positive and sum exactly to 1, making them directly interpretable.
-
Top-P Filtering (Nucleus Creation): With the normalized probability distribution in hand, the top-p sampling mechanism comes into play. The tokens are sorted by their probabilities in descending order. The model then iteratively accumulates these probabilities until the sum reaches the predefined
pthreshold. All tokens whose probabilities fall outside this cumulative sum are discarded, forming a "nucleus" of the most probable and contextually relevant candidate tokens. This step intelligently prunes the vast vocabulary down to a manageable and meaningful set. -
Random Sampling: Finally, the next token is randomly sampled from within this filtered nucleus. Because the sampling is constrained to a curated set of plausible tokens, the risk of generating irrelevant or nonsensical output is significantly reduced, while still allowing for the introduction of variability and creativity. This final stochastic step ensures that the LLM doesn’t merely repeat the most obvious choice but can explore nuanced alternatives within a well-defined boundary of likelihood.
This intricate, multi-stage pipeline is executed thousands of times for every generated sentence, with each selected token feeding back into the model as part of the new context for the next prediction. This iterative process allows LLMs to construct complex and extended pieces of text, dynamically adjusting their choices based on the evolving narrative and the subtle interplay of these control parameters.
Strategic Parameter Selection: Tailoring AI for Specific Applications
The profound impact of logits, temperature, and top-p on LLM output quality necessitates a strategic approach to their configuration. Developers and users alike must carefully consider the specific application and desired characteristics of the generated text to strike the optimal balance between predictability, accuracy, and creative flair. This is less a rigid science and more an informed art, often refined through empirical testing.
For high-stakes or factual scenarios, where precision, determinism, and minimizing "hallucinations" (generating factually incorrect information) are paramount, a more constrained approach is advisable. This includes applications such as:
- Legal document drafting: Precision is non-negotiable.
- Medical information retrieval or summarization: Accuracy is critical for patient safety.
- Code generation and debugging: Functional correctness is key.
- Technical report writing: Objectivity and factual grounding are essential.
In such cases, developers typically opt for a low temperature (e.g., 0.1 to 0.3) to sharply focus the probability distribution on the most likely tokens, coupled with a strict top-p value (e.g., 0.5 to 0.7) to severely limit the pool of candidate tokens. This configuration yields highly deterministic and predictable model responses, reducing the likelihood of unexpected or erroneous outputs.
Conversely, for creative domains where novelty, diversity, and imaginative output are valued, a more exploratory approach is preferred. This includes applications like:
- Poetry and fiction writing: Encouraging unique phrasing and narrative turns.
- Brainstorming and idea generation: Fostering a wide range of possibilities.
- Marketing copy and slogan creation: Seeking innovative and engaging language.
- Scriptwriting: Developing dynamic dialogue and plot elements.
Here, a higher temperature (e.g., 0.7 to 1.0 or even higher) is often employed to flatten the probability distribution, giving a greater chance to a wider array of tokens. This is combined with a broader top-p value (e.g., 0.9 to 0.99) to expand the nucleus of candidate tokens, allowing the model to explore more diverse linguistic paths. This configuration encourages richer variety and more unexpected, yet often coherent, outputs.
For conversational AI and chatbots, a middle ground is often sought. The goal is to maintain engaging, natural-sounding dialogue without becoming overly repetitive or entirely erratic. Parameters like t=0.5-0.7 and p=0.8-0.9 are frequently used to provide a good balance between coherence and spontaneity, making interactions feel more dynamic and less robotic. The optimal settings can vary significantly between models and specific use cases, underscoring the importance of empirical validation and user feedback in fine-tuning these parameters for production environments.
Broader Implications and the Future of Controllable AI
The statistical orchestration of logits, temperature, and top-p extends far beyond mere technical adjustments; it forms the bedrock of controllable AI and significantly impacts the broader adoption and utility of large language models. These mechanisms are not just footnotes in an LLM’s architecture but critical levers that define its behavior, reliability, and ultimately, its value to society.
Their impact on AI adoption is immense. Without these nuanced controls, LLMs would either be too bland and predictable to be useful for creative tasks, or too erratic and unreliable for critical applications. The ability to fine-tune the output characteristics means that a single LLM architecture can be adapted for a multitude of distinct use cases, from generating highly structured reports to crafting imaginative narratives, thereby expanding the potential market and utility of AI technologies across virtually every industry.
However, the power of these parameters also brings significant ethical considerations.
- Bias Amplification: The choice of sampling parameters can inadvertently amplify biases present in the training data. For instance, a higher temperature might allow for the generation of more stereotypical or harmful content if those biases exist in the model’s underlying knowledge. Researchers and developers must meticulously evaluate how different parameter settings influence the generation of biased or unfair outputs.
- Factuality and Hallucination: While lower temperatures generally reduce hallucination by sticking closer to the most probable (and often factual) sequences, they can also limit a model’s ability to synthesize novel information or engage in creative problem-solving. Higher temperatures, while fostering creativity, inherently increase the risk of generating factually incorrect or confidently fabricated content, posing challenges for applications where truthfulness is paramount.
- Safety and Harmful Content: The control over token selection is crucial for mitigating the generation of harmful, abusive, or inappropriate content. Stricter sampling parameters can act as a guardrail, but no system is foolproof, necessitating continuous research into robust safety mechanisms.
Looking ahead, future research in decoding strategies will likely focus on several exciting avenues:
- Dynamic Parameter Adjustment: Developing systems that can intelligently adjust temperature and top-p (and other parameters) on the fly, based on the real-time context, user intent, or specific task requirements.
- More Sophisticated Decoding Methods: Exploring hybrid approaches that combine the strengths of different techniques, potentially moving beyond fixed probabilities to incorporate more complex semantic or structural constraints.
- User-Friendly Interfaces: Creating intuitive tools that allow non-technical users to effectively control these parameters, democratizing access to powerful generative AI capabilities.
- Explainable AI (XAI): Enhancing our ability to understand why a particular token was chosen, providing greater transparency and trust in LLM decisions.
In conclusion, the seemingly invisible statistical processes of logits, temperature, and top-p are anything but minor technical details. They are fundamental to the operational integrity and versatile capabilities of large language models. As LLMs continue to evolve and integrate into more facets of daily life, a deeper appreciation of these control mechanisms becomes indispensable for developers, policymakers, and end-users alike. They are the silent orchestrators behind the magic of generative AI, shaping how these powerful tools interact with our world and dictating the very future of human-AI collaboration.
