
Amazon Web Services (AWS) today announced the general availability of Amazon Bedrock Managed Knowledge Base, a comprehensive suite of capabilities designed to empower developers to construct enterprise-grade generative AI applications utilizing their proprietary data in a matter of minutes. This new offering significantly streamlines the traditionally complex process of building and managing Retrieval-Augmented Generation (RAG) pipelines, enabling organizations to deliver accurate, fast, and trustworthy outcomes from their agentic AI applications without the burden of extensive infrastructure management.
The Genesis of Enterprise AI Challenges
The advent of generative AI has ushered in a new era of possibilities for enterprises, promising enhanced automation, intelligent customer interactions, and novel data insights. However, harnessing the full potential of large language models (LLMs) often requires grounding them in an organization’s unique and constantly evolving proprietary data. This is where Retrieval-Augmented Generation (RAG) has emerged as a critical architectural pattern. RAG allows LLMs to retrieve relevant information from a knowledge base before generating a response, thereby improving accuracy, reducing hallucinations, and ensuring responses are based on up-to-date, factual internal data.
Despite its benefits, implementing RAG effectively has presented significant hurdles for developers. Traditionally, building a robust RAG pipeline involves a series of intricate and often undifferentiated tasks. These include establishing secure data connectors to various enterprise sources, ingesting and preprocessing diverse data types, performing complex data chunking and embedding, managing vector databases for efficient retrieval, implementing re-ranking algorithms to optimize relevance, and orchestrating the entire workflow with foundation models. Each of these steps demands specialized knowledge, considerable development effort, and ongoing maintenance, diverting developer focus from core application logic to infrastructure plumbing.
Moreover, developers have grappled with three primary challenges: the sheer complexity of preparing heterogeneous data for accurate retrieval, the difficulty in handling complex, multi-step user queries that require sophisticated reasoning, and the constant need to manage and scale the underlying infrastructure components. These challenges collectively contribute to extended development cycles and increased operational overhead, hindering the rapid deployment and iteration of enterprise generative AI solutions.

Introducing the Managed Knowledge Base: A Paradigm Shift
Amazon Bedrock Managed Knowledge Base directly addresses these entrenched challenges by abstracting away the multiple infrastructure components developers have traditionally been forced to assemble and maintain themselves. It consolidates storage, retrieval mechanisms, embedding models, re-ranking capabilities, and foundation model selection into a single, cohesive, and fully managed primitive. This integrated approach allows developers to significantly accelerate their time-to-market for RAG-powered applications.
By default, the service intelligently selects and manages a default embeddings model, re-ranker model, and foundational model on behalf of the user. This intelligent automation ensures that developers can initiate their projects quickly, bypassing the often-tedious process of selecting and maintaining individual components. This abstraction is built upon three core innovations designed to further enhance ease of use and improve the accuracy of generative AI applications: Smart Parsing for optimized data ingestion, Agentic Retriever for sophisticated query handling, and seamless integration with Amazon Bedrock AgentCore Gateway for streamlined agent deployment and management.
The promise of the Managed Knowledge Base is profound: with just a few lines of code, enterprises can deploy scalable, end-to-end RAG pipelines that power their internal knowledge agents. For agent builders already leveraging Amazon Bedrock AgentCore Gateway, the Managed Knowledge Base is available as a pre-built target type, further reducing integration effort to minimal code, automatically generating role-based permissions, and providing comprehensive observability and evaluation metrics within the AgentCore Observability dashboard.
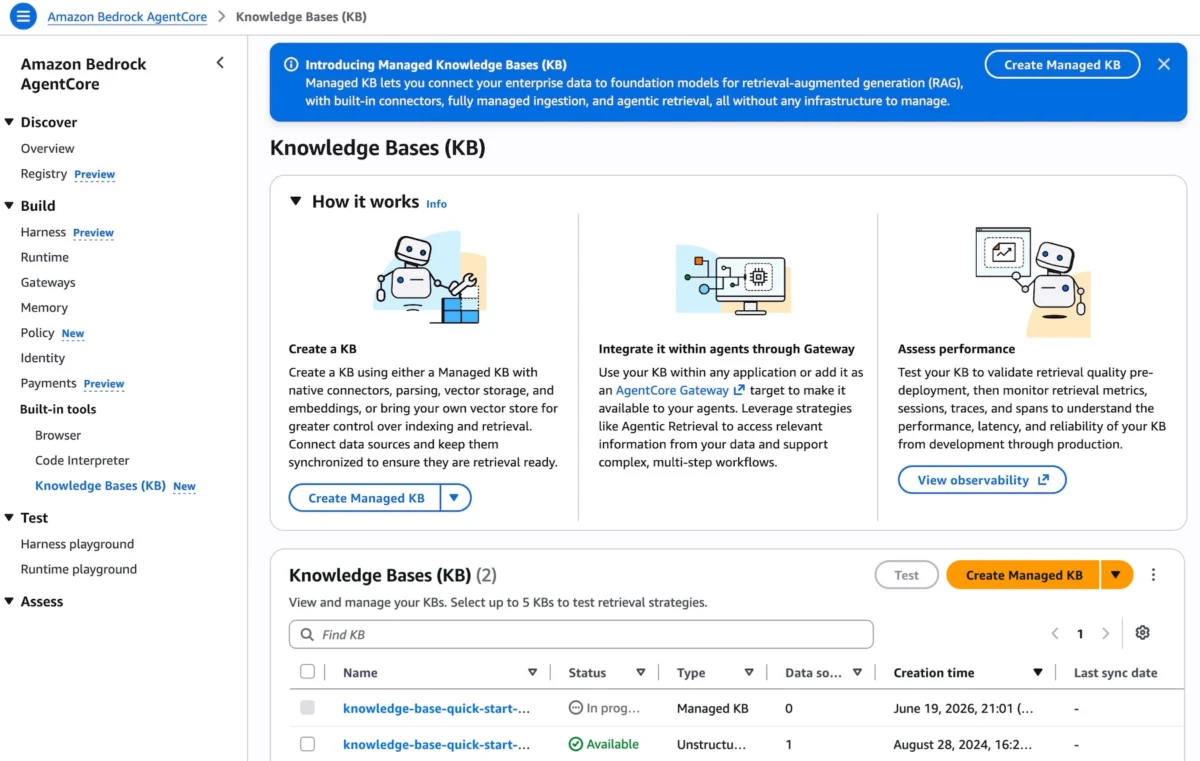
Getting Started: Simplified Deployment
Creating a Managed Knowledge Base is designed to be a straightforward process, accessible through either the Amazon Bedrock AgentCore console or the main Amazon Bedrock console. Users navigate to the "Knowledge Bases" page and select "Create Managed KB." This unified experience ensures consistency and ease of access regardless of the entry point.
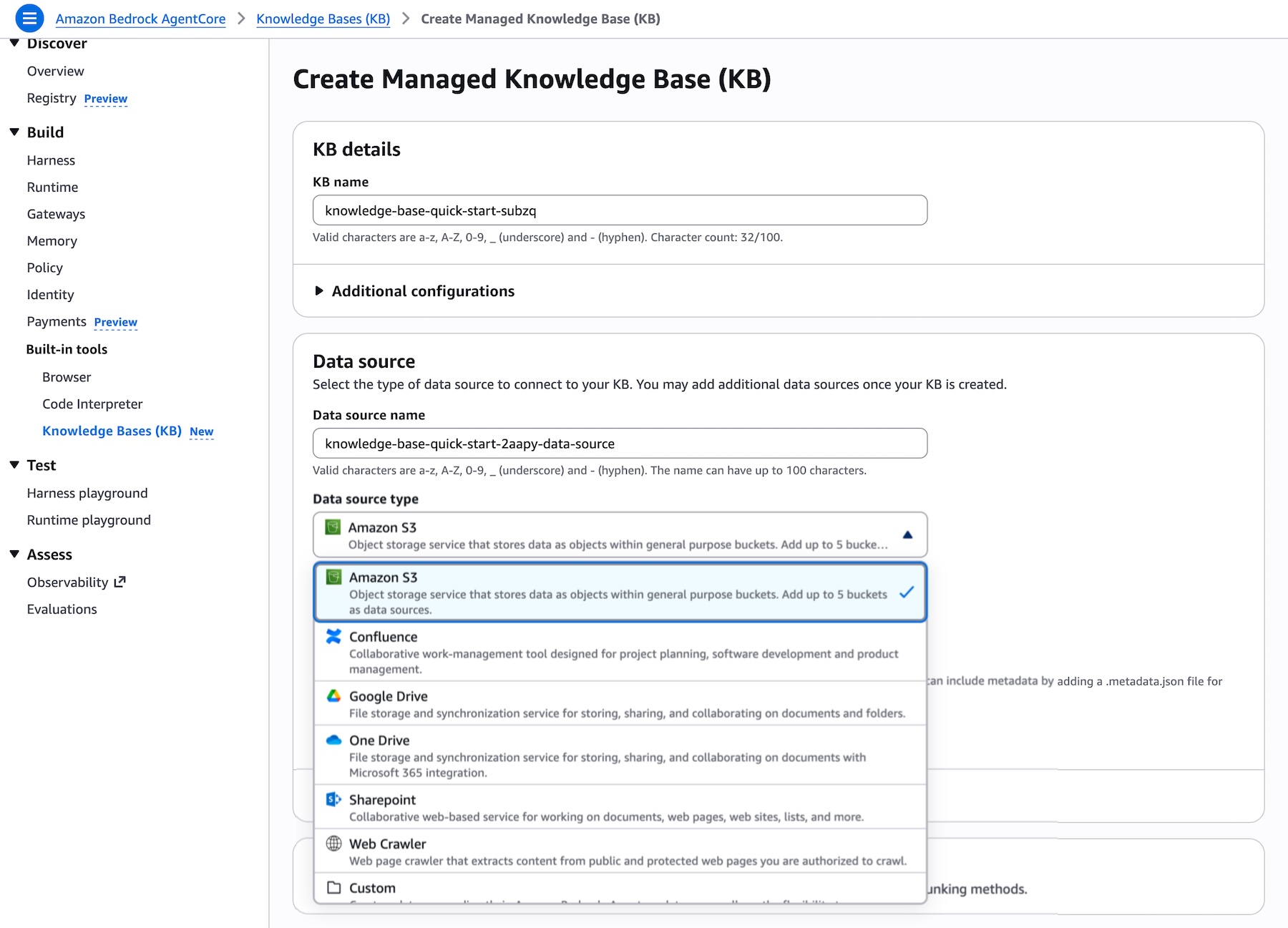
A crucial aspect of enterprise AI is connecting to diverse data sources. The Managed Knowledge Base simplifies this by offering a direct dropdown list of supported connectors, which currently include Amazon S3, Confluence, Custom, Google Drive, OneDrive, SharePoint, and Web Crawler. This broad compatibility ensures that organizations can readily integrate their existing data repositories without complex custom integrations. Furthermore, AWS Identity and Access Management (IAM) roles are automatically configured, providing secure data access while offering flexibility for users to customize permissions as needed, adhering to strict enterprise security policies.

Once a data source is selected and an optimized set of default configurations is presented, a knowledge base can be created in just a few clicks. Following data synchronization, the knowledge base becomes immediately available for integration with agents or as a powerful tool for foundation models, ready to answer complex queries.
Smart Parsing: Revolutionizing Data Ingestion
One of the most significant and often underestimated challenges in building effective knowledge bases is the preparation of diverse data types for accurate retrieval. Enterprise data exists in myriad formats, from structured databases and spreadsheets to unstructured documents like PDFs, internal wikis, presentations, and emails. Each format presents unique parsing and ingestion complexities. Manually developing and maintaining parsing strategies for this heterogeneity can consume weeks or even months of development time, often requiring iterative experimentation to achieve production-quality retrieval accuracy.
Smart Parsing within Amazon Bedrock Managed Knowledge Base fundamentally transforms this process. Once pointed at an organization’s data sources, Smart Parsing automatically determines the optimal parsing strategy for each data type and connector. This intelligent automation eliminates the need for manual configuration, significantly reducing developer effort and accelerating deployment.
Smart Parsing combines multiple advanced techniques to achieve this efficiency and accuracy:
- Multimodal Document Understanding: This capability allows the system to comprehend and extract information from documents that combine text, images, and tables, ensuring no valuable context is lost. Traditional parsers often struggle with mixed-media documents, leading to incomplete or inaccurate data ingestion.
- Semantic Chunking: Instead of arbitrary fixed-size chunks, semantic chunking intelligently divides documents into meaningful, contextually coherent segments. This ensures that relevant information is grouped together, improving the quality of embeddings and subsequent retrieval.
- Metadata Extraction and Enrichment: Beyond content, Smart Parsing automatically identifies and extracts critical metadata such as author, date, document type, and associated tags. This metadata can then be used to enrich the retrieved context, enabling more precise filtering and improving the overall relevance of responses.
- Layout and Structure Awareness: The parser understands the inherent structure of documents, differentiating between headings, paragraphs, lists, and other elements. This layout awareness helps in preserving the logical flow and hierarchy of information, which is crucial for accurate contextual understanding by LLMs.
This automated, intelligent approach to data preparation not only eliminates weeks of undifferentiated experimentation but also preserves the flexibility for developers to customize parsing strategies when highly specific requirements or unique data formats necessitate bespoke configurations.
Agentic Retriever: Mastering Complex Queries
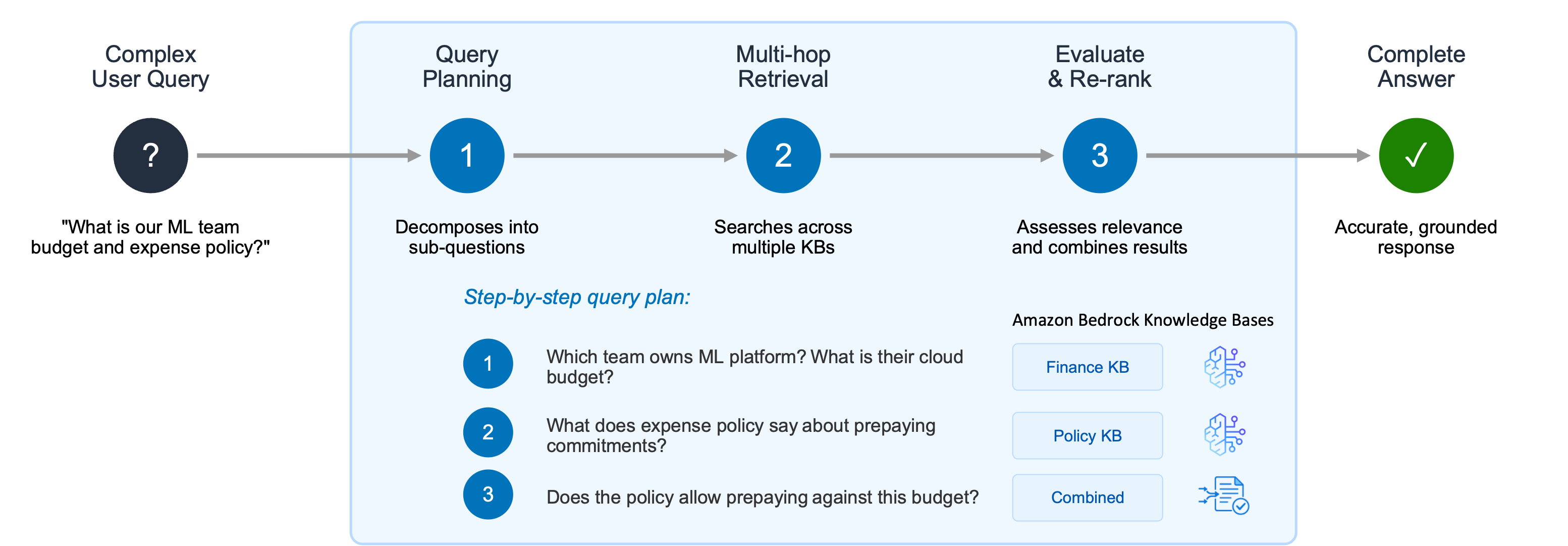
After data ingestion, the ability to query the knowledge base effectively is paramount. However, generative AI applications frequently encounter complex user queries that demand more than simple keyword matching or single-step retrieval. Such queries often require multi-hop reasoning, recursive retrieval across various data points, and intermediate evaluations of results to formulate a comprehensive answer.
Consider a scenario where a user asks two interrelated questions: "What is the cloud infrastructure budget for the ML platform team?" and "Does our expense policy allow prepaying annual commitments?" A conventional RAG system might retrieve documents related to the ML platform team’s budget but fail to connect this information with the separate expense policy details, leading to an incomplete or fragmented answer.
The Agentic Retriever in Amazon Bedrock Managed Knowledge Base is specifically engineered to solve this challenge. It operates by dynamically creating a step-by-step query plan based on the complexity of the user’s request. For the example above, the Agentic Retriever would formulate a plan such as:
- Identify the team that owns the ML platform and ascertain their allocated cloud infrastructure budget.
- Consult the organization’s expense policy to determine guidelines regarding prepaying annual commitments.
- Synthesize the information to determine if the ML platform team is permitted to prepay against their budget under the existing policy.
This system performs multi-hop retrieval and reasoning at each stage of the plan. It gathers relevant passages iteratively, evaluating the results at each step to refine its search and ensure comprehensive coverage. Once sufficient relevant information has been aggregated, the search process concludes, and the top results are returned. By abstracting away the complexity of building a separate multi-hop reasoning pipeline, the Agentic Retriever dramatically improves accuracy for intricate queries, empowering developers to concentrate on their agentic search applications rather than complex orchestration logic.
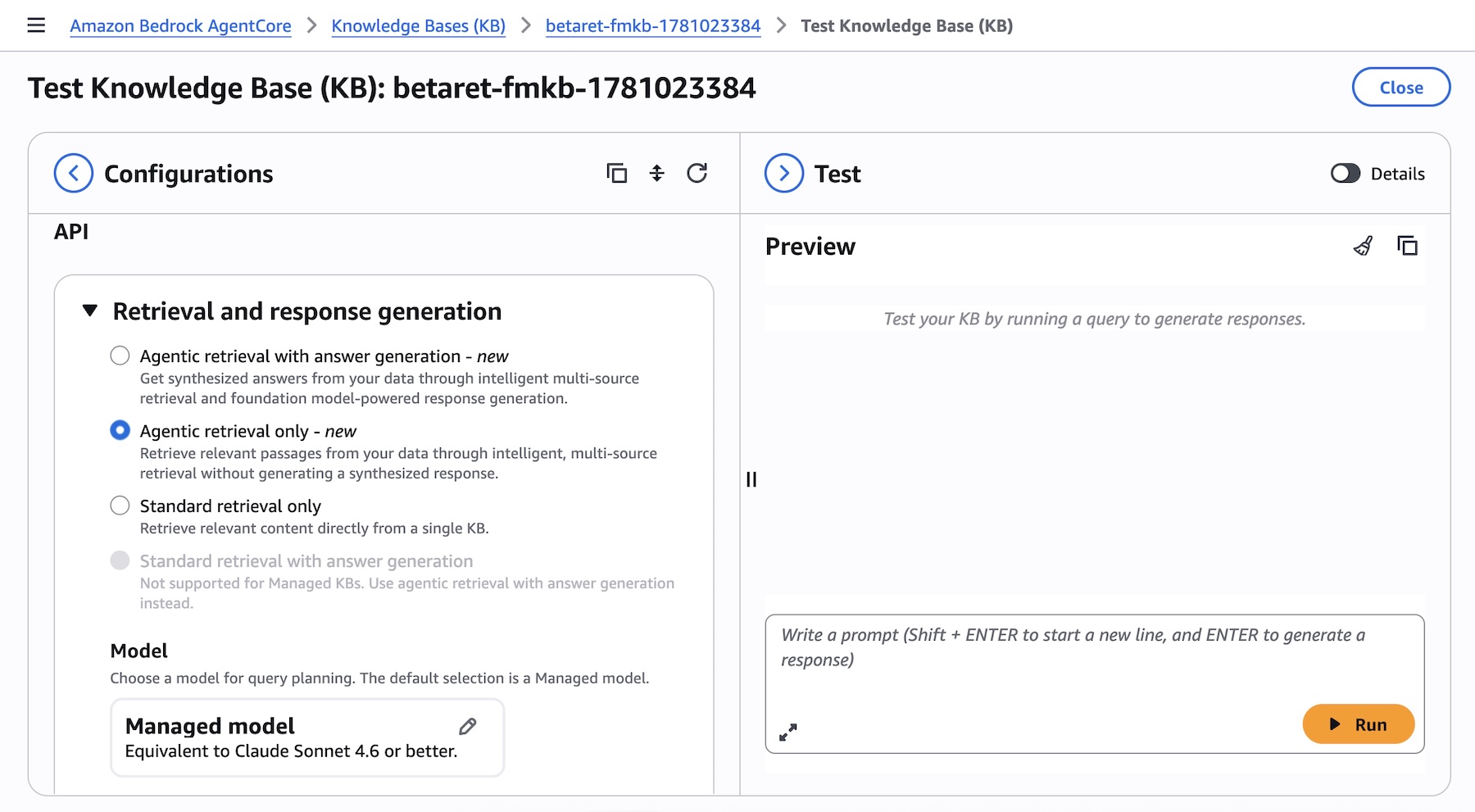
Developers can experiment with the Agentic Retriever directly from the test panel of their knowledge base within the Amazon Bedrock AgentCore console. By selecting "Agentic retrieval only" as the retrieval type, the system automatically plans and executes multi-step queries across connected knowledge bases, offering a powerful tool for exploring the capabilities of this advanced feature.
Seamless Integration and Ecosystem Flexibility
Amazon Bedrock Managed Knowledge Base is not just a standalone service; it is deeply integrated into the broader AWS ecosystem, particularly with Amazon Bedrock AgentCore Gateway. This seamless integration means the Managed Knowledge Base functions as a native target type within AgentCore, eliminating the need for manual integration efforts. The benefits of this native integration are substantial, including built-in observability for monitoring performance, robust policy enforcement for governance, and automatic permission management to maintain security and compliance.
When adding targets to an AgentCore Gateway, "Knowledge Base" now appears as a pre-built target type alongside other options such as MCP server, Lambda ARN, and REST API. Users simply select their knowledge base ID to expose its capabilities through the gateway.
A key enabler of this interoperability is the Model Context Protocol (MCP). The AgentCore Gateway exposes the standard MCP, ensuring that knowledge base tools are automatically discovered by clients from any MCP-compatible framework. This includes popular open-source frameworks like Strands Agents, LangChain, CrewAI, LlamaIndex, and LangGraph. This adherence to an open protocol means that no custom integration code is required, significantly reducing developer friction and fostering a vibrant ecosystem of compatible tools and applications.
Furthermore, Amazon Bedrock Managed Knowledge Base upholds the core principle of flexibility that developers have come to expect from the Bedrock platform. It avoids vendor lock-in by separating infrastructure management from model selection. This means that while AWS manages the underlying connectors, parsing, storage, and retrieval orchestration, developers retain full control over the models powering their applications. Every foundation model available on Bedrock can be used for the generation step, and developers can choose from different embedding and re-ranking models to fine-tune retrieval for their specific use cases. This flexibility allows teams to optimize for accuracy, cost-performance, or specific model capabilities without necessitating changes to their underlying infrastructure.
This model-agnostic approach ensures that organizations can continuously adapt to evolving requirements, leverage the latest advancements in foundation models, and respond to new model capabilities without incurring significant re-architecting costs. It empowers developers to focus on the unique aspects of their generative AI application, confident that they can swap models as their needs dictate.
Accelerating Enterprise Adoption and Market Implications
The introduction of Amazon Bedrock Managed Knowledge Base represents a strategic move by AWS to lower the barrier to entry for enterprise-scale generative AI adoption. By abstracting away the significant engineering overhead associated with RAG pipelines, AWS is empowering a broader range of developers and organizations, from startups to large enterprises, to deploy sophisticated AI applications more rapidly and cost-effectively.
This offering positions AWS competitively within the rapidly expanding generative AI market, challenging other cloud providers like Azure AI Studio and Google Vertex AI, which also offer managed services for AI development. The emphasis on security, reliability, and enterprise-grade features underscores AWS’s commitment to supporting complex organizational needs, particularly in regulated industries where data governance and secure access to proprietary information are paramount.
The shift in developer focus from infrastructure management to business outcomes is a critical implication. With the Managed Knowledge Base handling the heavy lifting of RAG, developers can dedicate more time to crafting innovative prompts, designing intelligent agent behaviors, and integrating AI into core business processes. This promises to accelerate the realization of tangible business value from generative AI investments. Moreover, the robust integration with open-source frameworks and the Model Context Protocol fosters an open and collaborative AI ecosystem, encouraging innovation and broader adoption of Bedrock as a foundational platform.
Availability and Economic Model
Amazon Bedrock Managed Knowledge Base is available today in key AWS Regions, including US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney, Tokyo), Europe (Dublin, Frankfurt, London), and AWS GovCloud (US-West) Regions. AWS has also indicated plans for future regional expansions, which can be tracked via the AWS Capabilities by Region page.
The pricing model for Bedrock Managed Knowledge Base is designed to be transparent and flexible, based on a pay-as-you-go approach with no upfront commitments. Costs are primarily determined by two dimensions: the size of the indexed data stored within the knowledge base and the number of retrievals performed on-demand. This usage-based pricing ensures that organizations only pay for the resources they consume, making it accessible for projects of all sizes. Further detailed pricing information is available on the Amazon Bedrock pricing page. New AWS customers can also explore the capabilities of Bedrock through the AWS Free Tier, allowing them to get started at no cost.
These advanced capabilities are compatible with any open-source framework, including CrewAI, LangGraph, LlamaIndex, and Strands Agents, and work seamlessly with any foundation model supported on Bedrock. The modular design of Bedrock services allows them to be used together or independently, providing maximum flexibility. Developers can begin their journey using their preferred AI-assisted development environment with the AgentCore open-source MCP server.
A New Era for Enterprise Generative AI
The launch of Amazon Bedrock Managed Knowledge Base marks a significant milestone in the evolution of enterprise generative AI. By abstracting away the inherent complexities of RAG pipeline construction and maintenance, AWS is empowering organizations to rapidly build, deploy, and scale intelligent applications that leverage their unique data assets. With Smart Parsing, Agentic Retriever, and deep integration with AgentCore Gateway, developers are equipped with powerful tools to overcome long-standing challenges in data preparation and query complexity. This offering promises to accelerate innovation, drive efficiency, and unlock new possibilities for businesses embracing the transformative potential of artificial intelligence.
For developers eager to delve deeper and get started, comprehensive resources are available through the Bedrock Knowledge Bases Developer Guide.
