
Amazon Web Services (AWS) has announced a significant enhancement to its Amazon Elastic Container Service (ECS) service auto scaling capabilities, introducing support for high-resolution 20-second metrics and optimized metric publishing. This update dramatically accelerates the detection and response to load changes, with internal AWS benchmarking tests demonstrating a 76% improvement in scale-out trigger time and a 72% reduction in total task provisioning time. This leap forward promises to deliver unparalleled responsiveness for containerized applications, translating into enhanced user experience, greater cost efficiency, and improved operational resilience for cloud-native workloads.
The Technical Leap Forward: Precision and Performance in Auto Scaling
The core of this transformative update lies in the granular 20-second resolution for Amazon CloudWatch metrics, a substantial improvement over the standard 60-second resolution previously available for ECS service auto scaling. While the 60-second metrics have served as a reliable foundation for many applications, the increasing dynamism and transient nature of modern cloud workloads demand even finer-grained monitoring and response. Applications handling rapid traffic bursts, microservices architectures with highly fluctuating inter-service communication, or real-time data processing pipelines often experience significant load changes within a minute. In such scenarios, a 60-second delay in detecting a surge could lead to noticeable performance degradation, increased latency, or even service unavailability before scaling mechanisms could effectively react.
With the new 20-second metric resolution, Amazon ECS service auto scaling can now ingest and analyze performance data at a much higher frequency. This accelerated data stream, combined with optimized metric publishing, allows the auto scaling system to identify demand surges or lulls nearly three times faster than before. The impact of this enhanced precision is starkly illustrated by AWS’s own internal testing:
- Time to trigger scale-out: Improved from an average of 363 seconds to a mere 86 seconds. This represents a remarkable 76% reduction in response time, or a 4.2x acceleration. This means that from the moment an application begins experiencing increased load, ECS auto scaling can initiate the process of adding new tasks significantly quicker.
- Total time to scale and provision new tasks: Reduced from 386 seconds to an impressive 109 seconds. This 72% faster total provisioning time, or a 3.5x acceleration, encompasses the entire cycle from metric detection to new container instances being fully operational and serving traffic.
These improvements are not merely incremental; they represent a paradigm shift in how quickly containerized applications on ECS can adapt to fluctuating demand. For applications where every second counts—such as e-commerce platforms during flash sales, live streaming services during peak viewership, online gaming with sudden player influxes, or financial trading applications requiring low-latency processing—this faster scaling capability directly translates into sustained performance, reduced user frustration, and the ability to maintain stringent Service Level Agreements (SLAs).
Understanding Amazon ECS and the Imperative of Auto Scaling
Amazon Elastic Container Service (ECS) is a fully managed container orchestration service that enables customers to easily run, stop, and manage Docker containers on a cluster. As a foundational component of AWS’s container strategy, ECS abstracts away much of the complexity of infrastructure management, allowing developers to focus on building and deploying applications. It supports various compute options, including AWS Fargate (serverless containers), Amazon EC2 instances (customer-managed servers), and ECS Managed Instances, offering flexibility to meet diverse workload requirements.
At the heart of any robust cloud-native architecture is auto scaling, a critical capability that automatically adjusts computing resources in response to demand. Without effective auto scaling, applications risk either over-provisioning resources (leading to unnecessary costs) or under-provisioning (resulting in performance bottlenecks and poor user experience). For containerized applications, where microservices might experience highly independent and variable loads, efficient auto scaling is paramount.
AWS has continuously evolved ECS auto scaling to address complex workload patterns. Its comprehensive scaling policies include:
- Predictive Scaling: Leverages machine learning algorithms to forecast future traffic patterns based on historical data, enabling proactive scaling before demand spikes occur. This is ideal for applications with recurring, predictable load variations.
- Scheduled Scaling: Allows users to define specific scaling actions at predetermined times, perfect for planned events like marketing campaigns or batch processing windows.
- Target Tracking Scaling: The most common reactive scaling policy, which adjusts task counts to maintain a target value for a specified metric (e.g., average CPU utilization, request count per target). This policy dynamically scales resources up or down in response to real-time workload changes.
The current update directly enhances Target Tracking Scaling by feeding it higher-resolution metrics. While predictive and scheduled scaling address known or anticipated events, target tracking is crucial for handling unforeseen or sudden changes in demand. By providing 20-second metric resolution to target tracking policies, AWS is empowering ECS services to react with unprecedented speed to these unpredictable fluctuations, filling a critical gap in responsiveness for highly dynamic applications. This refined granularity means the auto scaling engine can detect the onset of a load spike or the dissipation of demand much earlier, initiating scale-out or scale-in actions before the situation significantly impacts performance or unnecessarily consumes resources.
Operationalizing Enhanced Responsiveness: A Guide for Developers
Enabling the faster service auto scaling with high-resolution metrics is designed to be straightforward for both new and existing ECS services. The feature works seamlessly across all ECS compute options: AWS Fargate, ECS Managed Instances, and Amazon EC2.

For New ECS Services:
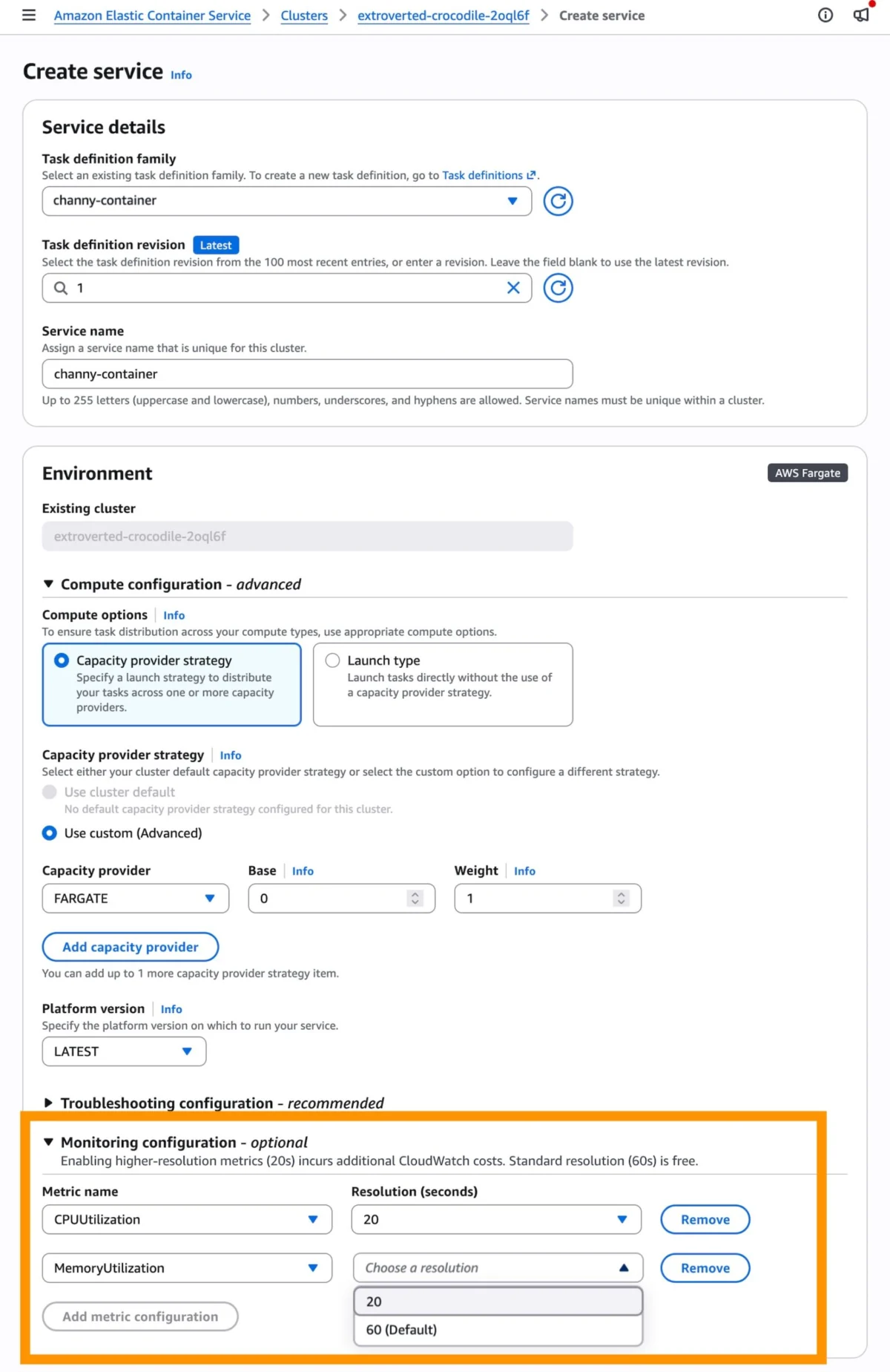
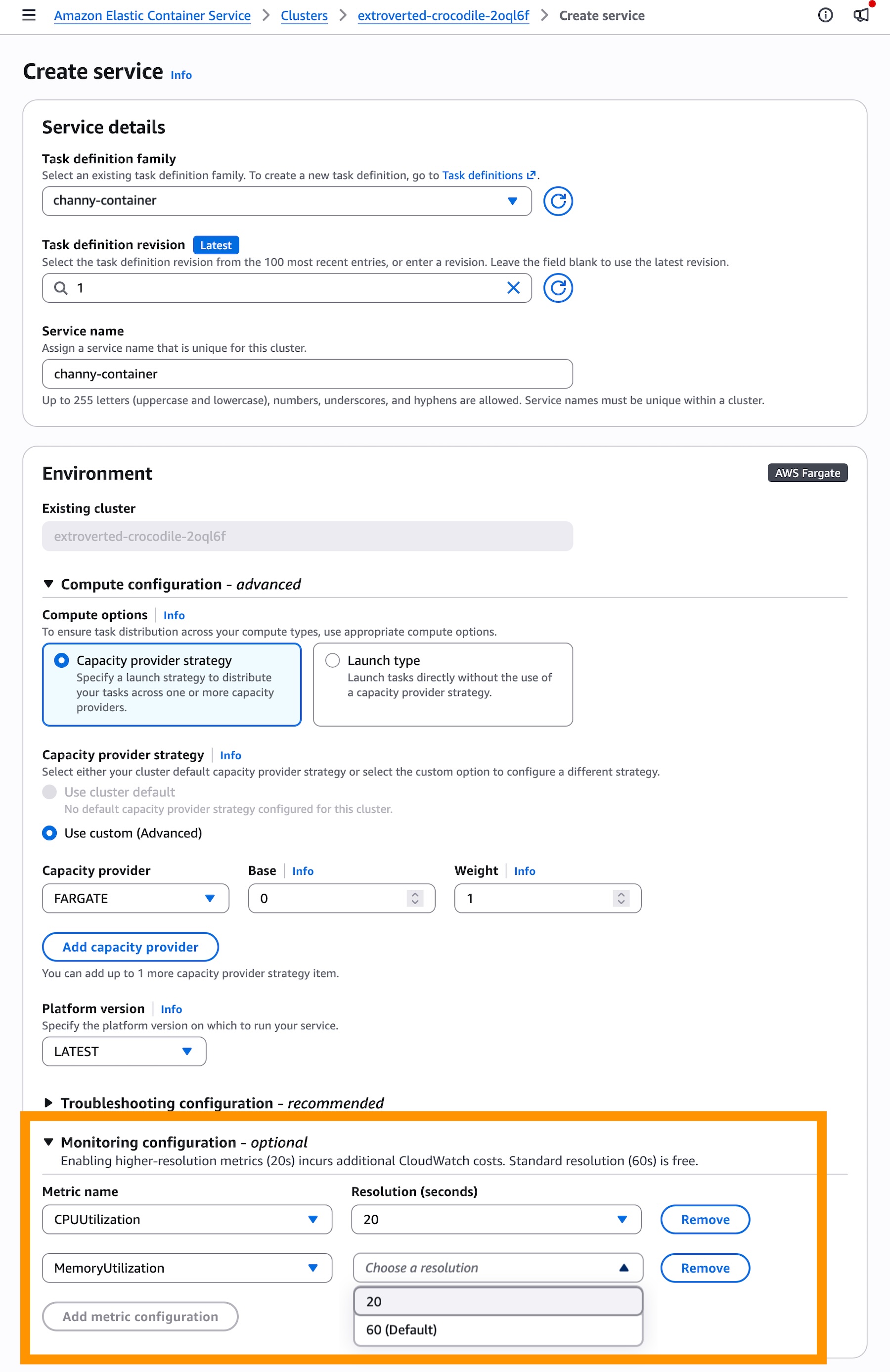
When creating a new ECS service through the Amazon ECS console, developers will find a new option within the Monitoring configuration section. Here, they can opt to add 20-second resolution metrics. It’s important to note that while standard 60-second resolution CloudWatch metrics are typically included without additional cost, these high-resolution metrics will incur additional CloudWatch costs due to the increased data ingestion and storage.
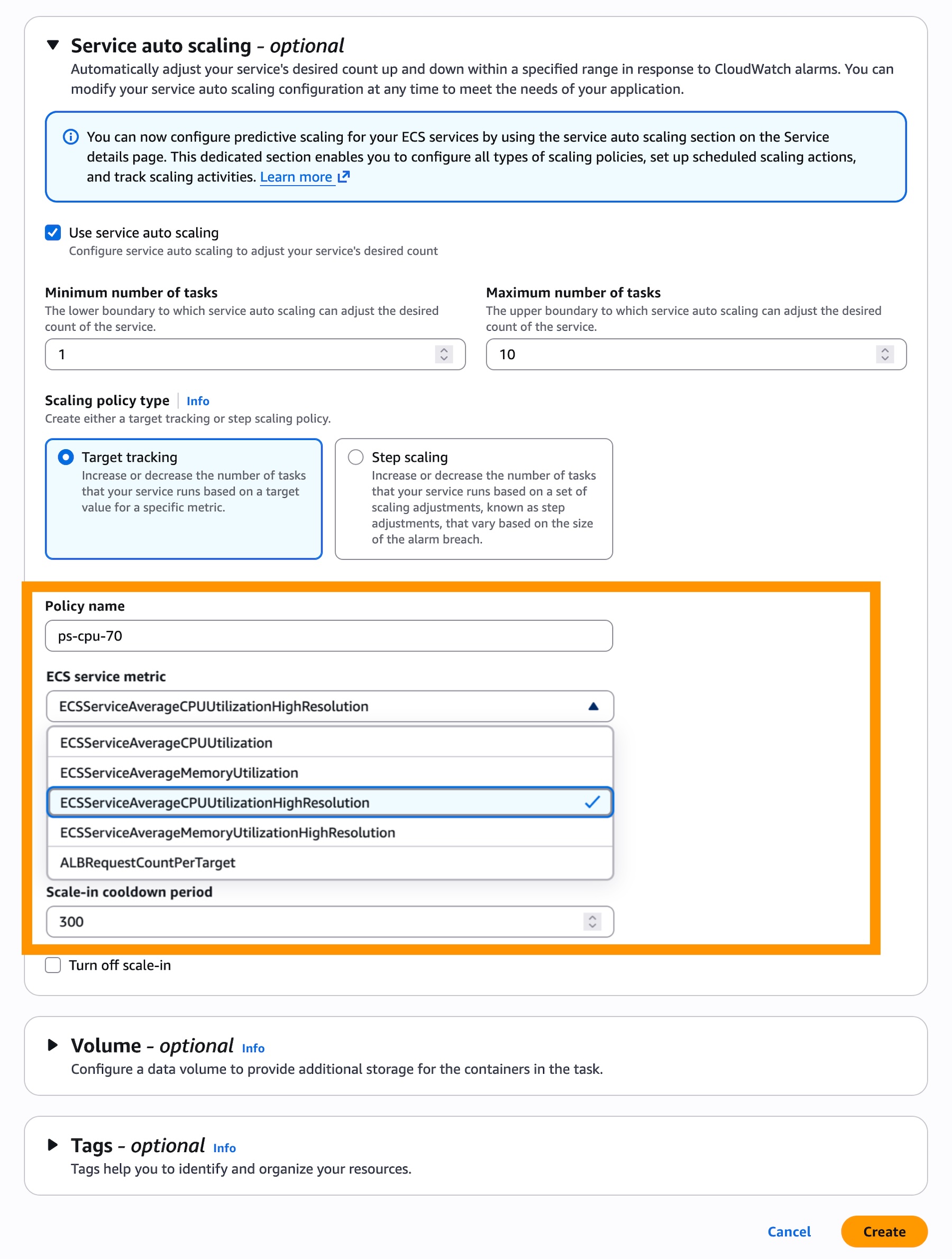
Once high-resolution metrics are enabled, the next step is to configure the auto scaling policy. In the Service auto scaling section, users should select Use service auto scaling and choose Target Tracking as the scaling policy type. Within the target tracking configuration, new metric options will be available: ECSServiceAverageCPUUtilizationHighResolution and ECSServiceAverageMemoryUtilizationHighResolution. Selecting one of these high-resolution metrics ensures that the auto scaling policy will evaluate scaling decisions based on the more frequent 20-second data points.
For Existing ECS Services:
Updating an existing service to leverage faster auto scaling involves a two-step process. First, users need to configure high-resolution metrics via the Update Service workflow in the ECS console or through AWS SDKs/tools or AWS CloudFormation. After the deployment completes and the service begins generating high-resolution metrics, users can then navigate to the Service and auto scaling tab from their service details page. From there, they can update their existing target tracking scaling policy to utilize the newly available high-resolution metrics.
Developers can also integrate these changes programmatically using the AWS Command Line Interface (AWS CLI) or through Infrastructure as Code (IaC) tools like AWS CloudFormation. This allows for automated deployment and management of services with faster auto scaling, aligning with modern DevOps practices. The AWS documentation provides detailed instructions and examples for enabling these metrics and configuring policies across various interfaces.
Broadening the Impact: Real-World Applications and Benefits
The introduction of 20-second resolution metrics for ECS service auto scaling carries significant implications across various industries and application types:
- Enhanced User Experience: For customer-facing applications like e-commerce websites, streaming platforms, or social media, maintaining responsiveness during sudden traffic spikes is paramount. Faster scaling means fewer users encounter slow loading times, timeouts, or errors, leading to higher satisfaction and retention rates. Imagine a major product launch or a viral event; the ability to scale up 4.2 times faster ensures the infrastructure can absorb the immediate surge without service degradation.
- Optimized Resource Utilization and Cost Efficiency: While scaling up quickly prevents performance issues, scaling down efficiently prevents unnecessary costs. The improved responsiveness also applies to scale-in events. When demand subsides, ECS can detect this more rapidly and reduce the number of running tasks, leading to faster decommissioning of unused resources. This dynamic optimization ensures that organizations pay only for the compute resources they actively consume, maximizing cost savings, particularly for workloads with highly variable demand patterns.
- Improved Operational Agility and Resilience: Automated and rapid responses reduce the need for manual intervention by operations teams. Instead of scrambling to add capacity during unexpected surges, DevOps personnel can trust the auto scaling mechanism to handle fluctuations autonomously. This frees up valuable engineering time to focus on innovation rather than firefighting. Furthermore, the ability to quickly adapt to load changes enhances the overall resilience of applications against unpredictable events.
- Support for Event-Driven Architectures and Microservices: In complex microservices environments, individual services might experience independent load variations. Faster auto scaling allows each service to adapt precisely to its unique demand profile, preventing bottlenecks in one service from cascading and impacting others. It also significantly benefits event-driven architectures where rapid processing of incoming events requires quick scaling of consumer services.
- Gaming and Interactive Applications: Online gaming platforms, which often experience highly unpredictable player surges and drops, can leverage this faster scaling to maintain low latency and a seamless experience for gamers worldwide. Interactive applications with real-time user engagement will similarly benefit from the instantaneous resource adjustments.
Strategic Implications and the Future of Cloud Native
This enhancement further solidifies Amazon ECS’s position as a leading container orchestration service, reinforcing AWS’s commitment to performance, automation, and operational excellence. In a competitive landscape that includes Kubernetes and other container platforms, the ease of use and now superior responsiveness of ECS for target tracking auto scaling offers a compelling advantage for organizations prioritizing managed services and rapid elasticity.
Industry analysts are expected to view this update as a strategic move that addresses the evolving needs of cloud-native development. As applications become increasingly distributed, ephemeral, and sensitive to latency, the demand for highly granular monitoring and ultra-fast automation will only grow. This ECS update is a testament to the ongoing innovation in cloud infrastructure, where the focus is shifting towards predictive and reactive capabilities that can anticipate and adapt to workload changes with minimal human intervention.
An AWS spokesperson, while not quoted directly in the announcement, would likely underscore that this development empowers customers to build more robust, cost-effective, and performant applications on ECS. It streamlines operations, reduces the cognitive load on developers and operators, and ensures that the underlying infrastructure can transparently scale to meet even the most demanding and unpredictable workloads. The future of cloud-native operations increasingly hinges on such intelligent automation, moving towards self-healing and self-optimizing systems.
Availability and Cost Considerations
Faster service auto scaling with high-resolution metrics for Amazon ECS is available immediately. While the feature itself incurs no additional cost, it’s crucial for customers to understand the pricing structure for high-resolution CloudWatch metrics. Unlike standard 60-second resolution metrics, which are typically free up to a certain threshold, high-resolution (1-second to 30-second) metrics introduce a new pricing dimension. These metrics are charged based on the number of metrics, API requests, and data storage.
Customers should consult the Amazon CloudWatch pricing page for detailed information on these costs. It’s a trade-off: the enhanced performance, improved resource utilization, and operational benefits derived from faster scaling will need to be weighed against the incremental monitoring costs. For many performance-critical or cost-sensitive applications, the benefits of avoiding performance degradation or over-provisioning will likely far outweigh the additional CloudWatch expenses.
AWS encourages users to experiment with this new capability and provide feedback through AWS re:Post for ECS or via their usual AWS Support contacts. This continuous feedback loop is vital for further refining and developing features that directly address customer needs in the dynamic cloud ecosystem. The accelerated responsiveness of ECS auto scaling marks a significant milestone in container management, promising a future of even more resilient and efficient cloud-native applications.
