
Twenty years ago today, on March 14, 2006, Amazon Web Services (AWS) quietly unveiled Amazon Simple Storage Service (Amazon S3), a product whose unassuming launch belied its transformative impact on the nascent cloud computing industry and the broader digital landscape. What began with a modest one-paragraph announcement on the AWS What’s New page, followed by a brief blog post from AWS evangelist Jeff Barr, would soon become the cornerstone of modern data infrastructure, fundamentally altering how businesses and developers store, manage, and leverage information at scale.
The Genesis: A Quiet Revolution in Data Storage
In the early 2000s, before the widespread adoption of cloud computing, storing and managing data presented significant hurdles for businesses. Companies typically had to invest heavily in on-premise hardware, data centers, and specialized IT staff to maintain storage infrastructure. This often led to over-provisioning (buying more storage than immediately needed, leading to wasted resources) or under-provisioning (running out of storage, causing operational disruptions). Scaling storage up or down was a complex, time-consuming, and expensive endeavor, particularly for startups and small businesses aiming for web-scale operations. Developers grappled with the "undifferentiated heavy lifting" of infrastructure management, diverting valuable time and resources away from innovation and core product development.
It was against this backdrop that AWS introduced S3, offering "storage for the Internet." The initial announcement highlighted its design to "make web-scale computing easier for developers," providing a "simple web services interface" to store and retrieve "any amount of data, at any time, from anywhere on the web." Crucially, it promised developers access to "the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites." This proposition was revolutionary: democratizing access to enterprise-grade, elastic storage capabilities previously reserved for tech giants. The early vision was clear: abstract away the complexities of storage, allowing developers to focus on building applications and services.
Foundational Principles: The Pillars of S3’s Enduring Success
From its inception, S3 was guided by a set of five fundamental principles that have remained central to its design and operation over two decades. These principles are not merely features but deeply ingrained architectural philosophies that underpin its reliability and utility:
- Security: Data protection by default was paramount. S3 was designed with robust security features from day one, allowing users granular control over data access, encryption, and network configurations. This ensures that sensitive information remains safeguarded against unauthorized access, a critical concern for any organization leveraging cloud services.
- Durability: S3 is engineered for "11 nines" (99.999999999%) of data durability. This extraordinary level of durability means that, on average, a customer could expect to lose only one object out of 10 billion stored over a period of one year. This is achieved through automatic replication of data across multiple devices and facilities within an AWS Region, combined with continuous data integrity checks and self-healing mechanisms that proactively detect and repair any signs of degradation. The goal is to be "lossless," ensuring that stored objects are never truly lost.
- Availability: Recognizing that hardware failures are inevitable in large-scale distributed systems, S3 was built with availability designed into every layer. Its architecture anticipates and handles failures gracefully, ensuring that data remains accessible even during component outages. This multi-Availability Zone design and redundant infrastructure are key to its high uptime, making it a reliable backbone for critical applications.
- Performance: S3 is optimized to store virtually any amount of data without degradation in retrieval speeds. Its massively parallel architecture allows for high throughput and low latency, essential for supporting diverse workloads ranging from web content delivery to large-scale data analytics and machine learning.
- Elasticity: Perhaps one of S3’s most defining characteristics is its automatic scalability. The system is designed to grow and shrink dynamically as data is added or removed, requiring no manual intervention from the user. This "pay-as-you-go" elasticity eliminated the need for upfront capital expenditure and the complexities of capacity planning, democratizing access to scalable infrastructure.
These principles, often taken for granted today, were groundbreaking at the time and set a new standard for cloud services. By handling the "undifferentiated heavy lifting" of storage infrastructure, S3 allowed developers to innovate at an unprecedented pace, focusing on their core business logic rather than storage plumbing.
Unprecedented Scale and Continuous Evolution
The journey of S3 over the past 20 years is a testament to continuous innovation driven by these core fundamentals, resulting in a scale that is truly difficult to comprehend.
At its launch in 2006, S3 offered a modest total storage capacity of approximately one petabyte across about 400 storage nodes housed in 15 racks spanning three data centers. Its total bandwidth was 15 gigabits per second (Gbps), designed to store tens of billions of objects, with an initial maximum object size of 5 GB. The price point was 15 cents per gigabyte per month.
Fast forward to today, and the metrics paint a picture of exponential growth:
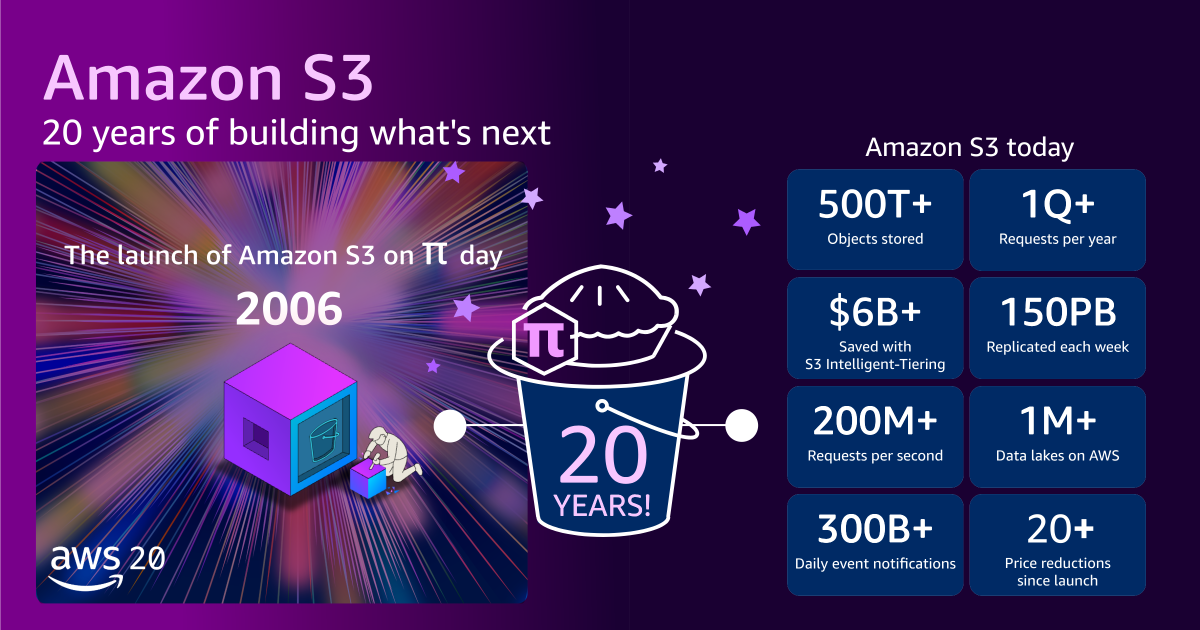
- Objects Stored: S3 now stores more than 500 trillion objects, a staggering number that underscores its role as a global data repository.
- Requests Per Second: It serves over 200 million requests per second globally, reflecting its constant utilization across millions of applications and services.
- Data Volume: The service manages hundreds of exabytes of data, a scale that dwarfs its initial capacity by several orders of magnitude. To put this into perspective, one exabyte is equivalent to one billion gigabytes.
- Infrastructure Footprint: S3 operates across 123 Availability Zones within 39 AWS Regions, ensuring global reach and resilience.
- Object Size: The maximum object size has dramatically increased from 5 GB to 50 TB, a 10,000-fold expansion that accommodates ever-larger datasets for advanced workloads like scientific simulations, media production, and big data analytics.
- Physical Scale: The sheer physical infrastructure required to support this scale is immense; if one were to stack all the tens of millions of hard drives comprising S3’s storage fleet, they would reportedly reach the International Space Station and almost back.
Despite this explosive growth in scale and capability, the cost of S3 has consistently decreased. Today, AWS charges slightly over 2 cents per gigabyte for standard storage, representing an approximate 85% price reduction since its 2006 launch. This consistent downward pressure on pricing, combined with the introduction of various storage classes like S3 Standard-IA (Infrequent Access), S3 One Zone-IA, and S3 Glacier (for archival storage), has allowed customers to further optimize their storage spend. A notable innovation, Amazon S3 Intelligent-Tiering, automatically moves data between access tiers based on usage patterns, saving customers collectively more than $6 billion in storage costs compared to using only S3 Standard.
Industry-Wide Impact and Standardization
Beyond its impressive internal growth, S3 has profoundly influenced the broader storage industry. Its simple yet powerful API has been adopted as a de facto standard, influencing how cloud storage is designed and consumed globally. Numerous vendors now offer "S3 compatible" storage tools and systems, implementing the same API patterns and conventions. This standardization has significant implications: it fosters a vibrant ecosystem of interoperable tools and applications, reduces vendor lock-in, and ensures that skills and operational knowledge gained with S3 are transferable across different storage environments. This widespread adoption has solidified S3’s position not just as a leading cloud service but as a fundamental building block of the internet’s infrastructure.
Perhaps one of S3’s most remarkable achievements is its unwavering commitment to backward compatibility. The code written by developers for S3 in 2006 still functions seamlessly today, without requiring any changes. This continuity is a testament to AWS’s dedication to stability and reliability. Over two decades, the underlying infrastructure has undergone multiple generations of upgrades—disks, storage systems, and the request-handling code itself have been entirely rewritten—yet the original data remains accessible, and the API remains consistent. This commitment to "just working" allows customers to benefit from continuous innovation without the burden of constant refactoring or data migration.
Engineering Excellence: The Engine Behind the Scale
The ability to operate S3 at such an unprecedented scale, while maintaining its core fundamentals and backward compatibility, is a testament to continuous engineering innovation. Insights from AWS VP of Data and Analytics, Mai-Lan Tomsen Bukovec, highlight several key engineering practices:
- Lossless Durability through Auditing and Repair: At the heart of S3’s 11 nines durability is a sophisticated system of microservices dedicated to continuously inspecting every byte across the entire storage fleet. These "auditor" services proactively detect any signs of data degradation and automatically trigger repair systems. This ensures that data is not merely replicated but actively maintained and healed, guaranteeing that objects are never lost.
- Formal Methods and Automated Reasoning: To mathematically prove correctness and ensure consistency in a system of S3’s complexity, engineers employ formal methods and automated reasoning in production. This involves using rigorous mathematical techniques to verify system properties. For instance, when new code is checked into the index subsystem, automated proofs verify that consistency properties have not regressed. This same approach is used to ensure the correctness of critical features like cross-Region replication and complex access policies (e.g., using Zelkova for S3 access policy analysis). This level of mathematical verification is rare in commercial software development and underscores AWS’s commitment to absolute reliability.
- Rust for Performance and Safety: Over the past eight years, AWS has progressively rewritten performance-critical code in the S3 request path using Rust. Components responsible for blob movement and disk storage have been re-engineered in Rust, with ongoing work across other areas. Rust’s key advantages—its strong type system and memory safety guarantees—eliminate entire classes of bugs at compile time, a critical property for a system operating at S3’s scale and demanding correctness requirements. This shift not only boosts raw performance but also enhances the overall robustness and security of the service.
- "Scale is to Your Advantage" Philosophy: S3 engineers embrace a design philosophy where increased scale inherently improves attributes for all users. The larger S3 grows, the more "de-correlated" individual workloads become. This means that an issue affecting one small segment of the system is less likely to impact the overall service, thereby improving reliability and performance for everyone. This counter-intuitive approach leverages the vastness of the system to enhance its resilience.
Paving the Way for Data and AI
Looking ahead, the vision for S3 extends beyond being a premier storage service; it is increasingly positioned as the universal foundation for all data and artificial intelligence (AI) workloads. The core idea is simple: store any type of data once in S3 and work with it directly, eliminating the need to move data between specialized systems. This approach significantly reduces costs, streamlines complexity, and removes the inefficiencies associated with creating and managing multiple copies of the same data across different platforms.
This vision is being realized through a continuous stream of new capabilities and integrations, transforming S3 from passive storage into an active data lake and analytics hub:
- Data Lake Foundation: S3 has become the de facto standard for building data lakes, serving as the raw storage layer for vast quantities of structured and unstructured data. Services like Amazon Athena, Amazon Redshift Spectrum, and AWS Glue directly integrate with S3, allowing users to query, transform, and analyze data in place without moving it.
- AI/ML Training and Inference: S3 is the primary storage for training data in machine learning workflows. Large datasets for image recognition, natural language processing, and other AI models are stored in S3, which seamlessly integrates with services like Amazon SageMaker for model training and deployment.
- Serverless Computing: S3 often acts as the trigger and storage for serverless functions (AWS Lambda), enabling event-driven architectures where data arriving in S3 automatically initiates processing workflows.
- Data Archiving and Disaster Recovery: With its various storage classes, S3 provides cost-effective solutions for long-term data archiving (S3 Glacier, Glacier Deep Archive) and robust disaster recovery strategies.
Each of these capabilities operates within S3’s cost structure, making it economically feasible to handle diverse data types and complex workloads that traditionally required expensive databases or specialized systems. The continued evolution of S3 into a comprehensive data platform underscores its strategic importance for the future of cloud computing and AI.
A Legacy of Innovation and Reliability
From its humble beginnings as a 1-petabyte storage solution priced at 15 cents per gigabyte, to a global data behemoth storing hundreds of exabytes across 123 Availability Zones for a mere 2 cents per gigabyte, Amazon S3 has embarked on an extraordinary journey. It has evolved from a simple object storage service into the foundational layer for modern data analytics and AI. Throughout this remarkable transformation, its five core fundamentals—security, durability, availability, performance, and elasticity—have remained steadfast. Crucially, the commitment to backward compatibility ensures that applications developed in 2006 continue to function seamlessly today, a testament to AWS’s long-term vision and engineering discipline.
As Amazon S3 marks its 20th anniversary, its legacy is clear: it democratized web-scale computing, fostered an explosion of innovation, and set new industry benchmarks for reliability and scalability. Its future promises to be equally impactful, continuing to serve as the silent, robust backbone for the next generation of digital advancements. Here’s to the next 20 years of innovation on Amazon S3.
