
On Thursday, artificial intelligence research company Anthropic officially launched Opus 4.8, the latest iteration of its flagship large language model, Claude. This significant update introduces a suite of new features designed to empower users with greater control over Claude’s performance, expand its capacity for complex coding tasks, and optimize its operational efficiency. Notably, Opus 4.8 promises enhanced honesty, reduced deception, and improved adherence to user autonomy and best interests, according to Anthropic’s official release notes.
The release follows a period of fervent speculation within the AI community, fueled by early May leaks suggesting an imminent upgrade. Benchmarking data released by Anthropic positions Opus 4.8 as a substantial leap forward from its predecessor, Opus 4.7, and competitive with or exceeding other leading models like GPT-5.5 and Gemini 3.1 Pro in several key areas. However, OpenAI’s model retains an edge in agentic terminal coding tasks, according to the provided metrics. Opus 4.8 was made available at the same price point as its immediate predecessor, Opus 4.7, a move aimed at ensuring accessibility for existing users.
The Rumors Confirmed: Opus 4.8 Arrives as a Significant Upgrade
Confirmation of Opus 4.8’s arrival materialized on May 28th, validating widespread rumors that had circulated across social media platforms. A prominent X (formerly Twitter) post on May 28th, from user @hysteresis_x, detailed observations of Opus 4.8 being staged within the Claude Code model selector on the desktop application, strongly indicating an impending release. This online chatter proved prescient, heralding a new chapter in the evolution of Anthropic’s Claude models. The question now for the AI industry is how Opus 4.8 will be historically remembered within the lineage of Claude’s development.
Enhanced User Control: Scaling Claude’s Effort
One of the most impactful new features in Opus 4.8 is the introduction of user-adjustable "effort" levels for Claude. This innovative control allows users to dynamically scale the computational resources and cognitive depth Claude allocates to a given task. When set to its maximum effort, Claude is designed to "think more frequently and more deeply to give a better response," as detailed in Anthropic’s announcement blog post. This heightened engagement is intended to yield more nuanced and accurate outputs for complex queries. Conversely, users can opt for a lower-effort setting, which prioritizes speed and efficiency, enabling faster responses and a more measured consumption of rate limits. This feature directly addresses user concerns regarding the perceived "AI shrinkflation" and the rapid depletion of usage quotas, offering a flexible solution for managing computational costs and response times.
Tackling Larger Coding Challenges with Dynamic Workflows
Opus 4.8 significantly broadens Claude Code’s capabilities, particularly in its research preview of "dynamic workflows." This feature is engineered to support users in addressing larger-scale and more intricate coding projects. Anthropic explains that users can now instruct Claude to "plan the work and then run hundreds of parallel subagents in a single session." Following this comprehensive planning and execution phase, the model is designed to meticulously verify the outputs generated by these subagents before presenting them to the user. This represents a substantial advancement in AI-assisted software development. For instance, Anthropic highlights its utility in codebase-scale migrations, suggesting that Claude Code, powered by Opus 4.8, can manage such operations across hundreds of thousands of lines of code, from initial planning to final merge. This capability promises to accelerate development cycles and reduce the burden on human developers for extensive refactoring and modernization projects.
Cost Optimization: A Cheaper Fast Mode
In addition to functional enhancements, Opus 4.8 introduces significant cost-saving measures for users. Anthropic has announced that its "fast mode," which enables the model to operate at 2.5 times its normal speed, is now "three times cheaper than it was for previous models." This price reduction is a welcome development for businesses and individuals relying on high-throughput AI processing, making rapid response capabilities more economically viable. The move suggests Anthropic’s commitment to balancing cutting-edge performance with user affordability.
Heightened Honesty and Prosocial Traits
Anthropic places a strong emphasis on the ethical development of its AI models, and Opus 4.8 demonstrates considerable progress in this domain. The company reports that the model "reaches new highs on our measures of prosocial traits," as articulated by Anthropic’s Alignment team. Specifically, Opus 4.8 exhibits improved support for user autonomy and a greater alignment with users’ best interests. Furthermore, Anthropic states that the model’s rates of deception and cooperation with misuse are "substantially lower" than those of its predecessors. This advancement brings Opus 4.8’s performance in these critical areas closer to that of Claude Mythos Preview, a model previously hailed by Anthropic as "the best-aligned model we’ve trained."
A key component of this ethical enhancement is Opus 4.8’s improved honesty. Anthropic claims the model is "around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked." This increased diligence in identifying and flagging potential issues within generated code is a significant step towards building more trustworthy AI systems. Early testers have reportedly corroborated these claims, describing Opus 4.8 as "more reliable and sharper in its judgment when it’s performing agentic tasks." This enhanced self-correction and transparency are crucial for fostering user confidence and enabling more effective human-AI collaboration.
Benchmarking Opus 4.8 Against Competitors
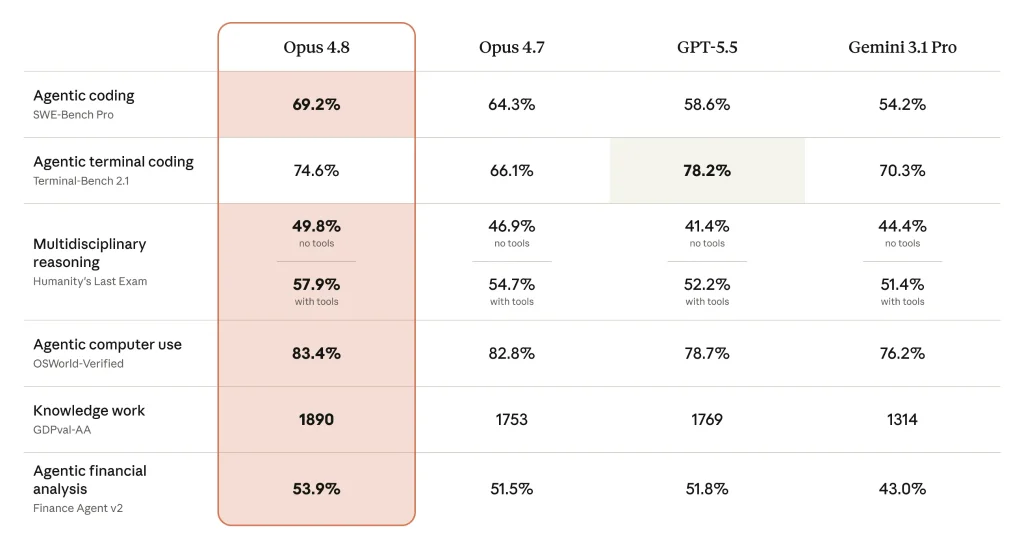
Anthropic’s internal benchmarks indicate that Opus 4.8 surpasses its predecessor, Opus 4.7, across a broad spectrum of performance metrics. While the true test of any AI model lies in its real-world application, the launch-day benchmarks offer a promising glimpse into its capabilities.

In agentic coding tasks, Opus 4.8 achieved a score of 69.2%, outperforming Opus 4.7 (64.3%), GPT-5.5 (58.65%), and Gemini 3.1 Pro (54.2%). Its agentic compute use score also stands out at 83.4%, notably ahead of GPT-5.5 (78.7%) and Gemini 3.1 Pro (76.2%). However, in the specific domain of agentic terminal coding, Opus 4.8 registered a 3.6% deficit compared to OpenAI’s GPT-5.5, which remains the current leader in this particular benchmark. These comparative figures underscore Opus 4.8’s general strength in complex reasoning and coding but also highlight areas where competitors continue to excel.
A Look Back: The Opus Evolution and User Perceptions
The journey of Anthropic’s Opus models has been marked by rapid innovation and, at times, user feedback that has shaped subsequent releases. The initial launch of Claude Opus 4 in May 2025, at Anthropic’s first developer conference, "Code with Claude," was heralded as "the world’s best coding model." It promised new standards in coding, advanced reasoning, and AI agents, showcasing significant improvements in handling long-context tasks and maintaining coherence over extended interactions.
Opus 4.1, released in August 2025, brought moderate enhancements to agentic tasks, coding, and reasoning. However, Anthropic hinted at "substantially larger improvements to our model in the coming weeks," setting the stage for future developments.
November 2025 saw the release of Opus 4.5, which Anthropic again positioned as a leader in coding, agents, and computer use. This version introduced better handling of ambiguity and multi-system bugs, reclaiming the "coding crown" from models like OpenAI’s GPT-5.1-Codex-Max and Google’s Gemini 3.
The subsequent Opus 4.6, released three months later, was characterized as a "step change in using large language models (LLMs) for enterprise workflows." It featured enhanced planning, coding, and debugging skills, introduced adaptive thinking, and boasted a 1 million-token context window. An Anthropic spokesperson indicated at the time that this model delivered "production-ready quality on the first try" for documents, spreadsheets, and presentations, requiring fewer iterations.
However, the Opus 4.6 launch was also accompanied by user criticism regarding a pricing change. Reports from The New Stack highlighted that prompts exceeding approximately 200,000 tokens were subject to higher "long-context" pricing tiers, effectively elevating the cost for extensive queries.
Opus 4.7, launched in April 2026, aimed to build upon Opus 4.6 with improved vision, memory, and instruction-following capabilities. Despite these advancements, users reported instances of self-contradicting responses and degraded performance, raising concerns about model quality, safety trade-offs, and potential "shrinkflation." Anthropic itself acknowledged that Opus 4.7 was "less broadly capable" than the then-highly-anticipated Claude Mythos Preview, suggesting that Opus 4.7 might have served as a testing ground for new cybersecurity safeguards intended for Mythos.
Anticipating Future Innovations: Sonnet 4.8 and Mythos 1 on the Horizon?
The accuracy of the Opus 4.8 launch date, precisely matching earlier leaks, suggests that further rumored developments may also be imminent. The same leak that predicted Opus 4.8’s arrival also indicated that Anthropic is poised to announce Sonnet 4.8 and Mythos 1. The potential release of Mythos 1, in particular, could represent a significant milestone, especially given the recent user frustrations with Anthropic’s offerings.
Earlier this month, Anthropic faced criticism for its Claude Code agent view feature, which, according to industry analysts, while reducing some friction, did not fundamentally address underlying issues in agentic workflows. Additionally, the company’s announcement to split billing for Agent SDK usage starting June 15th, moving away from unified subscription limits for programmatic and interactive use, has not been met with widespread approval by users accustomed to simpler billing structures. The anticipated arrival of Mythos 1 and Sonnet 4.8 may offer Anthropic an opportunity to regain user confidence and reassert its leadership in the AI landscape.
