

The burgeoning field of artificial intelligence has seen a significant evolution, moving from static models to dynamic, autonomous agents capable of complex decision-making and tool utilization. However, a critical challenge has emerged alongside this progress: how to rigorously evaluate these sophisticated AI agents. Many development teams continue to assess AI agents using methodologies designed for large language models (LLMs), focusing primarily on final outputs. This approach, experts warn, is fundamentally insufficient, often obscuring critical failures that could undermine agent reliability, efficiency, and overall performance in real-world applications. A more comprehensive strategy is urgently needed, one that scrutinizes the agent’s entire execution process, from initial reasoning to tool interaction and adaptive behavior.
The Evolving Landscape of AI Agents and the Evaluation Gap
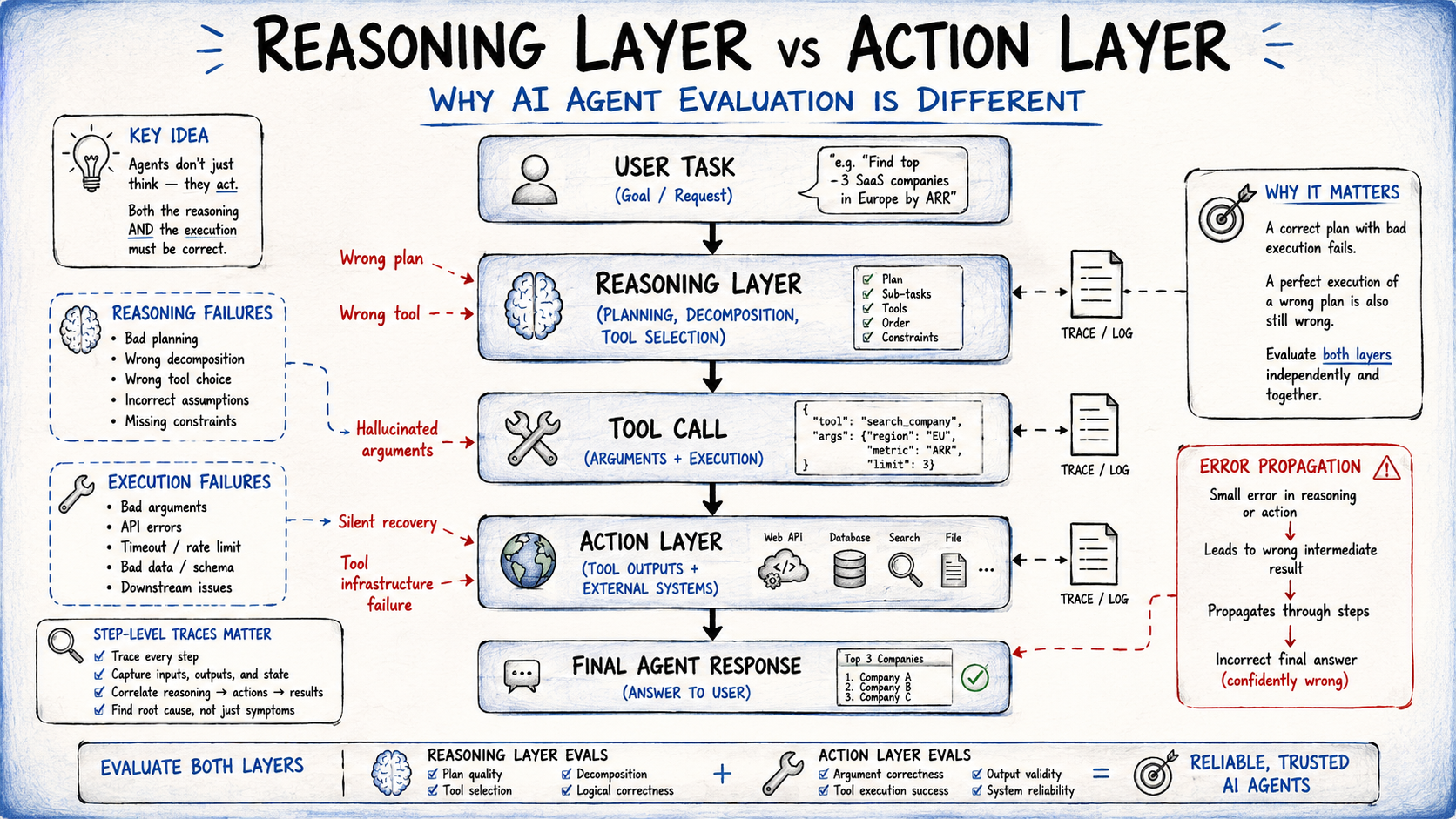
The proliferation of AI agents across diverse sectors—from automated customer support and financial analysis to scientific research and software development—underscores the urgent need for robust evaluation frameworks. Unlike traditional LLMs, which primarily generate text based on prompts, AI agents are designed to perceive their environment, reason, plan, and execute actions, often interacting with external tools and systems. This operational complexity introduces multiple layers where failures can occur, making a simple "pass/fail" based on the final outcome dangerously misleading.
For instance, an agent might produce a superficially correct final answer despite having selected an inappropriate tool, generated malformed arguments for a tool, or poorly handled a tool’s failure during its execution path. Evaluating only the endpoint makes it exceedingly difficult to pinpoint the root cause of such breakdowns. This gap between the agent’s internal workings and its external manifestation necessitates a paradigm shift in evaluation, moving from outcome-centric to process-centric assessments.
The Crucial Imperative: Understanding Multi-Layered Failures
The conventional wisdom that agent failures are merely "prompting problems" needing clearer instructions often overlooks deeper systemic issues. AI agents operate across distinct yet interconnected layers—primarily the reasoning layer and the action layer—each susceptible to independent failures. The reasoning layer encompasses the agent’s ability to interpret tasks, formulate plans, and make strategic decisions. The action layer involves the agent’s execution of these plans, including selecting and using tools, interacting with APIs, and processing feedback.
An agent might flawlessly reason about the correct course of action but then fail in the execution, perhaps by calling the right tool with incorrect parameters or by mishandling the tool’s response. Conversely, an agent might correctly interact with tools but exhibit flawed reasoning that leads to an inefficient or suboptimal path. Treating agent evaluation as a singular, end-to-end accuracy check inherently blinds developers to these distinct failure surfaces. Comprehensive evaluation demands detailed step-level traces—logs that capture every tool call, its arguments, the result, and the subsequent model decision. Without such granular tracing, debugging production failures becomes an exercise in costly guesswork, prolonging development cycles and increasing deployment risks.
Establishing the Foundation: Defining Success Metrics

Effective evaluation is inextricably linked to clearly defined success criteria. Ambiguity in what constitutes a "successful" agent interaction can render evaluation metrics meaningless. Industry best practices advocate for crafting eval tasks where two independent domain experts would consistently arrive at the same pass/fail verdict. This starts with unambiguous task specifications, ideally paired with reference solutions—known-correct outputs that satisfy all grading criteria. These reference solutions not only prove the task’s solvability but also serve to verify the accuracy and configuration of the grading logic itself.
Before any evaluation runs commence, a clear definition of the task, its specific instructions, and the expected success criteria (including edge cases) is paramount. Furthermore, outlining failure conditions—what unequivocally constitutes an incorrect or unacceptable response—is equally vital. A well-specified task, derived from real-world usage failures rather than abstract scenarios, provides a more robust starting point for evaluation than waiting for a hypothetically "perfect" dataset. The longer teams delay in building these foundational evaluations, the more complex and resource-intensive the process becomes.
Precision in Assessment: Code-Based Graders for Action Layers
For evaluating the action layer of an AI agent, deterministic graders offer the most efficient, cost-effective, and reproducible solution. These are code-based checks that assess specific conditions without requiring subjective model-in-the-loop judgment. Such graders are ideal for verifying concrete aspects of an agent’s performance, including:
- Tool Usage: Confirming that the agent invoked the correct tool for a given sub-task.
- Argument Validation: Checking if the arguments passed to a tool adhere to the expected format and values.
- Result Interpretation: Ensuring the agent correctly processed and utilized the output from a tool.
- API Interactions: Validating successful communication with external APIs.
These deterministic checks are often fast, objective, and straightforward to debug. However, their primary limitation lies in their brittleness; a grader specifically looking for "confirmation_code: CONF-789" will fail to recognize an otherwise correct response that formats the same information differently. Despite this, they form the essential first line of defense for the action layer, quickly flagging explicit technical errors.
Nuance and Judgment: Model-Based Evaluation for Reasoning
While code-based graders excel at objective checks, certain aspects of agent performance resist deterministic assessment. These include the quality of the agent’s reasoning, the tone and empathy of its output, its faithfulness to retrieved context, or the overall coherence and helpfulness of its responses. For these nuanced dimensions, leveraging a language model as a judge (LLM-as-a-Judge) becomes an invaluable tool. LLM-based graders offer flexibility and the capacity to handle open-ended outputs but introduce non-determinism and potential calibration drift that requires careful management.
To maintain the reliability of model-based graders, several best practices are critical. Firstly, structured rubrics are indispensable. Vague instructions like "Evaluate whether the response is helpful" yield noisy results. Instead, rubrics should explicitly define criteria, such as "the response must directly address the user’s question, ground all claims in retrieved context, and avoid out-of-scope suggestions." Each dimension should be graded with a separate, isolated judgment to improve signal quality.
Secondly, regular calibration against human judgment is crucial. The accuracy of LLM-as-a-Judge outputs must be routinely validated against a sample graded by human domain experts. Divergences typically indicate issues with the rubric itself, prompting refinement. Providing the grader with an explicit "Cannot determine" option prevents forced judgments on ambiguous cases, preserving the integrity of the evaluation. Finally, for multi-component tasks, incorporating partial credit is essential. An agent that correctly identifies a problem and verifies a customer but fails to process a refund is meaningfully more effective than one that fails at the initial diagnostic step. Binary pass/fail metrics obscure these critical distinctions, hiding where the agent genuinely breaks down.
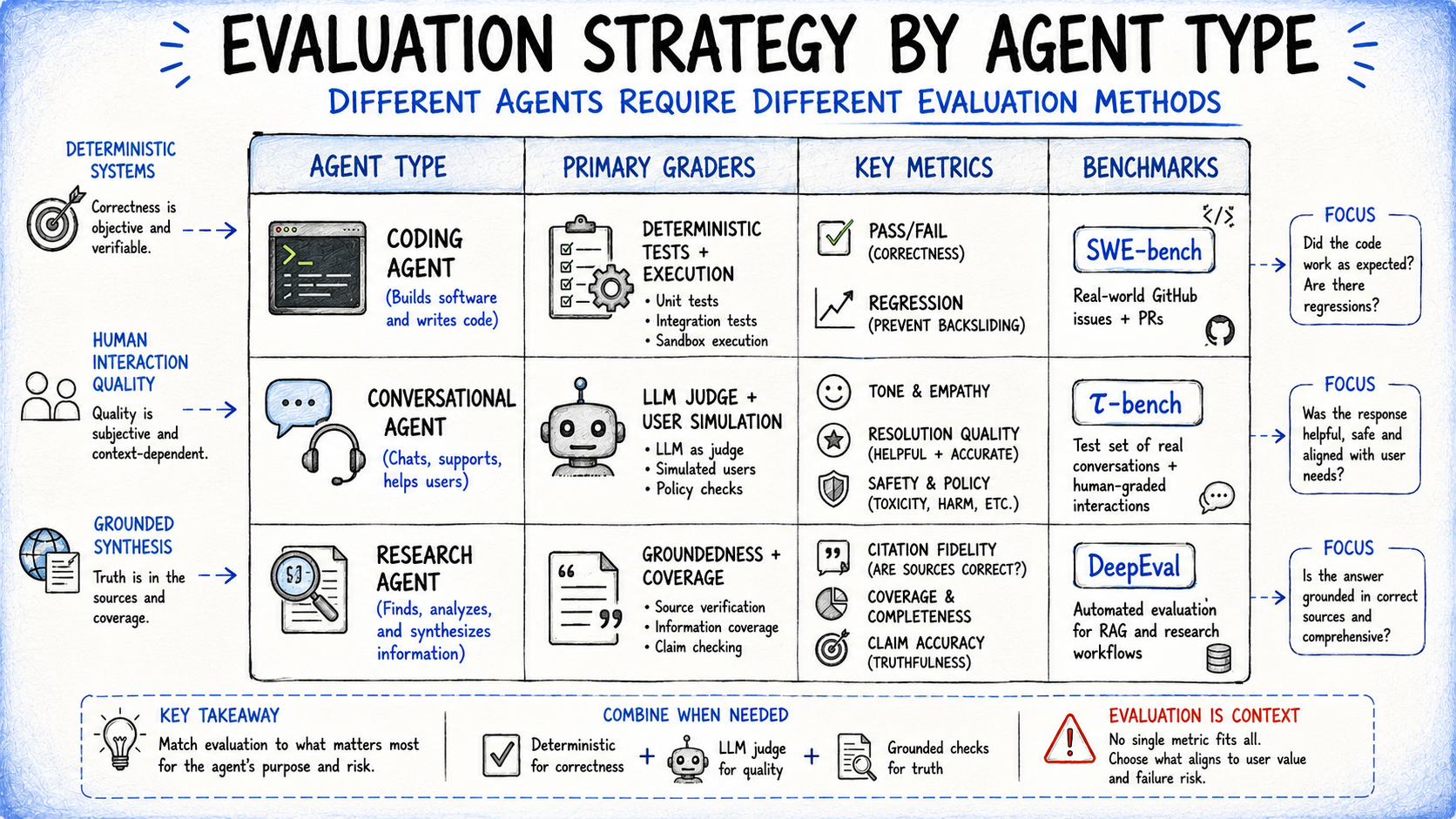
Tailored Evaluation Strategies for Diverse Agent Types
While the core principles of evaluation apply broadly, the specific strategies and the weighting of different graders must be tailored to the agent’s type and its intended application. Different agents exhibit distinct failure modes that demand prioritized attention.
- Coding Agents: These agents write, test, and debug code. Their evaluation largely hinges on deterministic outcomes: does the generated code run without errors, do existing tests pass, and does the proposed fix resolve the issue without introducing new regressions? Benchmarks like SWE-bench Verified and Terminal-Bench exemplify this pass/fail approach, often supplemented by rubric-based quality checks for aspects like security, readability, and robust handling of edge cases.
- Conversational Agents: Used in support, sales, and coaching, these agents interact directly with users. Evaluation extends beyond task completion to encompass the quality of the interaction itself. This includes assessing tone, clarity of explanation, and overall user experience. This often necessitates a second language model simulating a user to evaluate conversational flow and agent responsiveness across multiple turns, as demonstrated by frameworks like 𝜋-bench.
- Research Agents: Tasked with gathering and synthesizing information from various sources, research agents require rigorous checks for groundedness (verifying claims against retrieved sources), coverage (ensuring all essential information is included), and source quality (confirming the agent consulted authoritative and reliable material).
Navigating Non-Determinism: Accounting for Variability in Agent Behavior
A significant characteristic of AI agents, particularly those interacting with complex environments or relying on stochastic models, is their inherent non-determinism. The same task, with identical inputs, can yield varying tool selections, reasoning paths, and final outcomes across different runs. This variability, stemming from stochastic model outputs, tool latency, partial failures, and adaptive decision-making, renders single-trial evaluations potentially misleading. Robust agent evaluation must therefore reason over distributions of outcomes rather than relying on a single execution trace.
To address this, metrics like pass@k and pass^k are commonly employed. Pass@k measures whether at least one out of ‘k’ attempts succeeds. For example, if an agent is run three times on a task, and it succeeds on any one of those attempts, it counts as a pass for pass@3. This is useful when a single correct outcome is sufficient, and retries are permissible. Pass^k, conversely, measures whether the agent succeeds on all ‘k’ attempts. If an agent has a 75% single-trial success rate, its pass^3 rate would be approximately 42% (0.75 0.75 0.75), highlighting how quickly perceived reliability degrades when consistent success is required. The choice between these metrics ultimately depends on the product’s requirements: pass@k for scenarios where a single success suffices, and pass^k for applications demanding consistent, repeated success.
Strategic Evaluation Cycles: Capability vs. Regression Testing
A mature evaluation strategy differentiates between capability evaluations and regression suites, each serving a distinct purpose in the agent’s development lifecycle.
- Capability Evaluations: These are forward-looking, designed to ascertain "what new capabilities has this agent acquired?" They typically begin with relatively low pass rates, focusing on tasks that currently challenge the system. As an agent improves, its scores on capability evals rise. Once a capability eval consistently achieves very high scores (e.g., 90% or more), it signals that the task is no longer measuring new capabilities but rather confirming existing reliability.
- Regression Evaluations: These serve as a critical safeguard, asking, "Can the agent still perform everything it could before?" Regression tests should ideally run close to 100% pass rates. Any significant drop in score acts as an immediate warning that a recent change has introduced a performance regression, necessitating investigation before deployment.
Over time, tasks from capability evals that have reached high performance can be promoted into the regression suite. However, it is vital to continuously introduce new, more challenging capability evaluations before existing suites become saturated. A saturated suite loses its sensitivity to genuine improvements, making meaningful progress appear as mere noise.
Beyond Development: Extending Evaluation into Production Monitoring
While development evaluations capture anticipated failure modes, production environments inevitably expose unforeseen challenges. Real users introduce novel inputs, edge cases, and contextual nuances that rarely surface in synthetic test suites. Therefore, robust production monitoring is not merely an adjunct but a necessary extension of the evaluation framework.
A holistic evaluation system integrates several complementary signals:
- Automated Evals: Run continuously (e.g., on every commit), these cover known failure modes at scale, preventing regressions before users are affected. Their limitation lies in potential divergence between test distributions and real-world usage.
- Production Monitoring: Tracks operational metrics such as latency, error rates, tool failures, and token usage in real-time. This surfaces issues that synthetic tests miss, though typically only after they have occurred.
- User Feedback: Directly highlights instances where an agent, despite appearing "correct" by internal metrics, fails to meet user intent or expectations. While sparse and self-selected, this qualitative feedback is often profoundly informative.
- Manual Transcript Review: Provides deep qualitative insights into an agent’s reasoning, tool use, and decision paths. This is crucial for validating whether automated graders are truly measuring the desired behaviors and for identifying emerging patterns of failure.
Together, these layers construct a comprehensive view of agent performance in practice. The foundational infrastructure enabling this integrated approach is step-level tracing—capturing every detail of the agent’s reasoning, tool calls, arguments, results, and decisions. Platforms like LangSmith, Arize Phoenix, Braintrust, and Langfuse provide robust tracing and evaluation frameworks, while tools such as Harbor and DeepEval handle the overarching evaluation harness.
The Broader Implications: Trust, Reliability, and Future of AI
The shift towards rigorous, process-oriented evaluation for AI agents is not merely a technical refinement; it is a strategic imperative for the broader adoption and trustworthiness of AI. As AI agents assume increasingly critical roles in business operations and daily life, their reliability and explainability become paramount. Superficial evaluation risks deploying brittle systems that erode user trust, incur significant operational costs due to failures, and hinder regulatory compliance.
By embracing a systematic approach that delves into the "how" rather than just the "what" of agent performance, developers can build more robust, efficient, and transparent AI systems. This commitment to deep evaluation will be a defining characteristic of successful AI implementations, fostering innovation while ensuring responsible and reliable deployment across the intelligent frontier.
