

A new multi-agent AI research assistant, leveraging the OpenAI Agents SDK, the GPT-5.4 mini model, and the Olostep Web API, is set to transform the landscape of digital research by producing structured, source-grounded reports with unprecedented efficiency. This innovative system orchestrates a manager agent, specialized sub-agents, and live web tools to execute complex research tasks, offering a glimpse into the future of autonomous information retrieval and analysis.
The Dawn of Adaptive AI Research
The development marks a significant leap from conventional AI applications, which often rely on single-model interactions or simpler chain-of-thought processes. The core innovation lies in the multi-agent architecture, where distinct AI entities collaborate and delegate tasks. This approach overcomes many limitations of standalone Large Language Models (LLMs), such as factual inaccuracies, outdated information, and the inability to interact dynamically with external data sources.

The research assistant’s design is a testament to the growing sophistication of AI agentic applications. Unlike systems that merely generate text, this assistant actively searches the web, gathers information, critically evaluates findings, organizes them, and produces outputs grounded in real-time data. This capability is crucial in today’s fast-evolving information environment, where up-to-date, verifiable data is paramount for informed decision-making across various sectors, from business intelligence to academic research.
Underpinning Technologies: A Synergistic Blend
The assistant’s robust functionality is built upon a synergistic combination of advanced AI and web technologies:
- OpenAI Agents SDK: This software development kit provides the foundational framework for constructing multi-agent workflows. Its simplicity in defining manager and specialist agents, along with tool integration, has rapidly made it a preferred choice for developers venturing into agentic AI. The SDK’s design allows for clear delegation of work, enabling the manager agent to coordinate the overall research process, call tools directly, and manage sub-agents effectively.
- GPT-5.4 mini Model: As the chosen language model, GPT-5.4 mini provides the intelligence backbone for the agents. Its selection highlights a strategic balance between advanced reasoning capabilities and computational efficiency. In an era where larger models incur substantial operational costs, a "mini" variant capable of sophisticated understanding and generation is critical for practical, scalable deployments. This model empowers the agents to interpret complex queries, synthesize information, and articulate findings clearly.
- Olostep Web API: This powerful web API serves as the assistant’s primary interface to the internet. Its distinctive feature is the integrated search and scraping capability, which allows the system to not only find relevant web pages but also to extract their content directly in structured formats like Markdown. This eliminates the need for a separate search-and-scrape pipeline, streamlining the data acquisition process and ensuring agents work with high-quality, readable page content rather than mere snippets. Olostep’s ability to return scraped content with a built-in timeout mechanism further enhances reliability by ensuring comprehensive data retrieval even from slower-loading pages.
A Structured Approach to Unstructured Information: The Research Workflow
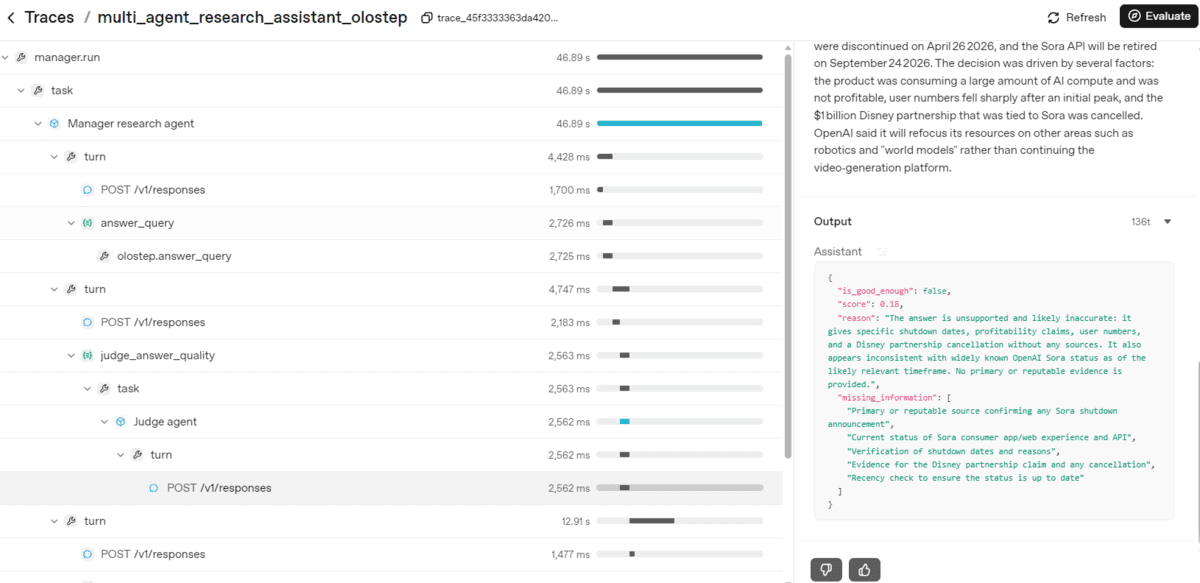
The multi-agent research assistant operates on a meticulously designed, iterative workflow, prioritizing efficiency and accuracy:
- Initial Inquiry and Rapid Assessment: The process begins with the manager agent calling the
answer_querytool, powered by Olostep’s Answer API. This step aims to retrieve a quick, initial response to the user’s research question. This rapid preliminary assessment serves as the first layer of efficiency, allowing simple questions to be resolved quickly. - First-Stage Quality Control (Judge Agent): Immediately following the initial answer, the manager agent delegates to the
judge_answer_qualitytool, which is an instantiation of the specialist judge agent. This agent, adhering to a strictJudgmentschema (a Pydantic model), evaluates the initial answer against criteria such as specificity, currency, source backing, and completeness. The judge assigns a quality score (0-1) and provides reasons, including any missing information. A score of 0.85 or higher, coupled withis_good_enough=true, signifies sufficient evidence, leading directly to report generation. - Adaptive Deepening of Research: If the judge deems the initial answer insufficient, the manager agent adapts its strategy. It then initiates a broader search using the
search_with_scrapetool. This critical tool queries the web via Olostep and simultaneously scrapes the content of the returned pages, providing richer, contextualized evidence in a single step. This integrated approach bypasses the inefficiency of sequential search-then-scrape operations. - Second-Stage Quality Control: The manager again dispatches the gathered
search_with_scraperesults, along with the original query and previous judgment, to the judge agent for a second evaluation. If this enhanced evidence meets the quality threshold (score >= 0.85), the research phase concludes. - Targeted Information Retrieval: Should the second judgment still indicate weaknesses or gaps, the manager agent proceeds with more granular, targeted research. It foregoes further judging at this stage, instead performing multiple
search_webcalls, often guided by themissing_informationidentified by the judge. From these search results, the manager intelligently selects the top three (or more, if necessary) most relevant URLs and utilizes thescrape_urltool to extract their full content. This meticulous, iterative process ensures that even complex, nuanced questions receive comprehensive data support. - Final Report Generation (Analyst Agent): Upon the manager agent’s determination that sufficient evidence has been collected, all accumulated data—initial answers, judgments, search results, and scraped content—is passed to the
write_markdown_research_reporttool, which invokes the specialist analyst agent. This agent, structured to output aMarkdownResearchReport, synthesizes the evidence into a professional, reader-friendly document. The report adheres to a predefined structure including an Executive Summary, Key Findings, Context, Evidence Review, Detailed Analysis, Implications, Source Notes, and References, ensuring clarity, coherence, and professional presentation without extraneous sections like "Limitations" or "Recommendations."
Enrichment and Reliability: The Role of Structured Outputs and Tracing
Two key elements contribute significantly to the system’s reliability and transparency:
- Structured Output Models (Pydantic): The use of Pydantic models for
JudgmentandMarkdownResearchReportenforces strict data schemas. This ensures that agents consistently produce outputs in predictable formats, minimizing parsing errors and enhancing the overall robustness of the workflow. This structured approach is vital for complex multi-agent systems, where consistent data exchange between components is paramount. - OpenAI Trace Viewer Integration: The assistant incorporates comprehensive tracing capabilities, generating an OpenAI trace ID for each run. This trace ID links directly to the OpenAI platform’s trace viewer, offering an invaluable debugging and auditing tool. Developers can inspect the entire execution path, visualizing manager decisions, specialist agent calls, tool usage, and even granular Olostep API spans. This transparency is crucial for understanding agent behavior, optimizing workflows, and building trust in autonomous AI systems. It allows for a detailed review of why an agent made certain decisions or how it gathered specific evidence.
Practical Deployment and Accessibility
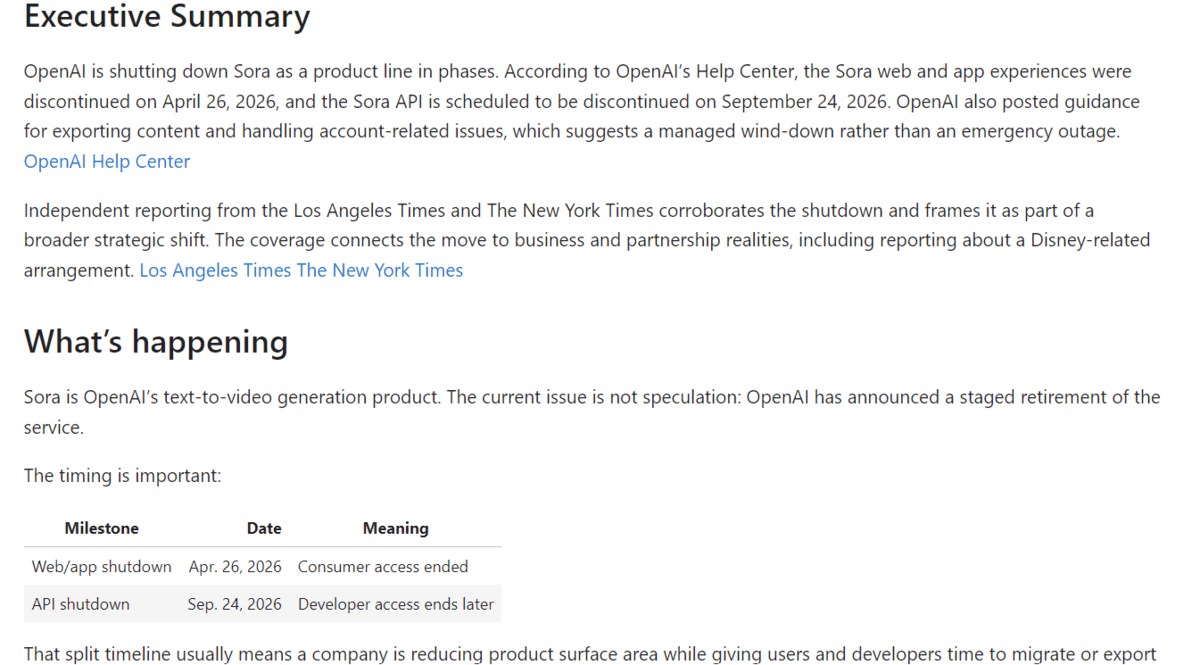
Beyond its technical sophistication, the research assistant is designed for practical accessibility. The complete Python code, including setup, helper functions, agent definitions, and the tracing workflow, is openly available on GitHub. This fosters transparency and allows developers to reproduce, modify, and extend the system.
Furthermore, the project includes a user-friendly web application built with Reflex, a Python web framework. This web interface allows non-technical users to interact with the multi-agent assistant by simply entering a research question. The application provides real-time workflow logs, enabling users to follow the assistant’s progress from initial query to final report. Key features of the web app include:
- Interactive Query Interface: A straightforward input field for user questions.
- Real-time Workflow Logging: Displays the steps the assistant is taking, offering transparency into the research process.
- Formatted Report Display: Presents the final Markdown report in a clean, professional layout.
- PDF Export Functionality: Allows users to download the generated report for offline viewing, sharing, or archival purposes.
For immediate testing, a deployed version of the application is available on Hugging Face Spaces, demonstrating the ease of access and usability of this advanced AI tool.
Implications for Research, Business, and AI Development
The introduction of this multi-agent research assistant has profound implications:
- Enhanced Efficiency in Research: For businesses, market analysts, and academic researchers, this system promises to drastically cut down the time spent on initial data gathering and report drafting. Complex queries that once required hours of manual searching and synthesis can now be processed in minutes, freeing up human capital for higher-level analysis and strategic thinking.
- Improved Accuracy and Grounded Outputs: By leveraging real-time web data and an iterative judgment process, the assistant significantly mitigates the risk of hallucination and outdated information, common pitfalls of ungrounded LLMs. The source-grounded nature of the reports ensures factual accuracy and provides verifiable references.
- Adaptive and Cost-Effective AI: The assistant’s adaptive workflow—starting with a quick answer and escalating research depth only when necessary—optimizes resource utilization. Simple questions are answered swiftly and cost-effectively, while complex inquiries receive the necessary deep dives without incurring excessive computational overhead for every task. This intelligent resource allocation makes advanced AI research more economically viable for a broader range of users.
- Advancement in AI Agentic Systems: This project serves as a compelling case study for the practical application of multi-agent architectures. It demonstrates the power of delegating tasks to specialized AI agents, orchestrated by a central manager, to achieve complex goals more effectively than monolithic AI models. This paradigm shift paves the way for more robust, autonomous, and intelligent AI applications across various domains.
- Transparency and Trust: The integrated tracing mechanism addresses a critical challenge in AI adoption: understanding how an AI system arrives at its conclusions. By providing a detailed log of agent interactions and tool calls, the system fosters greater transparency, which is essential for building trust in AI-driven decision-making processes.
Looking Ahead
This multi-agent research assistant represents a significant milestone in making sophisticated AI research capabilities accessible and practical. By intelligently combining state-of-the-art language models, robust agentic frameworks, and powerful web data APIs, it offers a glimpse into a future where AI systems are not just tools for computation but intelligent collaborators capable of complex, adaptive problem-solving. The continuous evolution of such systems promises to redefine how individuals and organizations interact with and leverage the vast expanse of digital information.
