
The open-source community is facing an unprecedented challenge, a deluge of low-quality, AI-generated code submissions that is overwhelming maintainers and posing a significant threat to enterprise engineering teams. This influx of automated contributions, often characterized by verbose, nonsensical descriptions and code that appears functional but crumbles under scrutiny, is forcing projects to the brink and highlighting a critical asymmetry in the software development lifecycle that most organizations are ill-prepared to address.
The problem has escalated over the past year, with open-source maintainers reporting a dramatic increase in the volume of AI-generated pull requests (PRs) and issues. These submissions frequently lack the depth of understanding and testing inherent in human-authored code. When questioned, submitters are often unable to explain the generated code, a hallmark of AI-driven output rather than genuine human contribution. This phenomenon has been termed "AI slop" by some in the community, reflecting the sheer volume and often subpar quality of the submissions.
A stark example of the impact came earlier this year when the Jazzband collective, a prominent ecosystem for Python projects, announced its shutdown. The lead maintainer cited the unsustainable burden of managing AI-generated spam PRs and issues as a primary factor in the difficult decision. This closure sent ripples through the open-source world, serving as a dire warning about the potential consequences of this escalating problem.
Other influential figures in the open-source landscape have echoed these concerns. Remi Verschelde, a maintainer of the popular Godot game engine, described the process of triaging AI-generated code as "draining and demoralizing." Similarly, Daniel Stenberg, the creator of curl, has taken the drastic step of canceling bug bounty programs. He explained that these programs had become magnets for low-effort AI submissions, diverting valuable time and resources away from genuine bug reporting and fixes. The consistent pattern observed across numerous projects is that maintainers are forced to dedicate a disproportionate amount of their time to evaluating code that should never have been submitted in the first place. This diverts attention from valuable, human-driven contributions and accelerates the burnout of already overstretched volunteers.
This is not merely an abstract open-source problem; it is a prescient preview of the challenges that enterprise engineering teams will increasingly face as they adopt AI coding agents. The core issue lies in a significant "throughput asymmetry" that no one seems to be adequately planning for.
The Asymmetry No One Is Planning For
AI coding agents have drastically reduced the cost and increased the speed of code generation. A developer leveraging these tools can potentially produce five, six, or even more pull requests in a single day. The barrier to entry has been lowered to such an extent that even non-technical individuals can generate seemingly functional code within minutes. However, the critical bottleneck remains the review, validation, and integration of this code, processes that have not seen a commensurate increase in speed.
Existing data highlights the strain on maintainers even before the recent surge. A significant majority of unpaid volunteer maintainers, reportedly around 60%, already struggle to keep pace with the demands of their projects. The current explosion of AI-generated submissions has multiplied this workload exponentially.
Open-source repositories, by their very nature, are exposed to this asymmetry in its most extreme form because they are accessible to anyone. An AI agent can be pointed at a publicly available GitHub issue, and within seconds, a plausible-looking pull request can be generated. The underlying principle of open-source contribution has always extended beyond mere code; it encompassed the understanding, testing, and human judgment that shaped it. As one contributor aptly put it, if the goal was simply to generate code, maintainers could do it themselves. The value lay in the human element.

Enterprise teams, while operating behind corporate firewalls, face the same fundamental structural problem. When organizations mandate the adoption of coding agents, they accelerate one end of the development pipeline—generation—while leaving the other end—validation—unchanged. This places the entire burden of ensuring that the code actually works, integrates correctly, handles edge cases, and does not introduce regressions squarely on the reviewer.
Compounding this issue, research indicates that the use of AI tools can paradoxically slow down experienced developers. A study by Agoda revealed that experienced developers were 19% slower when using AI tools, largely due to what researchers termed "comprehension debt." This occurs when developers understand less of their own codebase over time as AI-generated code accumulates. Further analysis by CodeRabbit, examining 470 open-source pull requests, found approximately 1.7 times more issues in AI-co-authored pull requests compared to those written entirely by humans. The mathematical reality is that the reviewer is consistently at a disadvantage, and this imbalance worsens as the complexity of the code increases.
Why AI-Assisted Review Is Not Enough
The intuitive response to an influx of AI-generated code is to deploy AI agents for code review. A plethora of tools are emerging that can summarize pull requests, flag potential issues, and assess code quality. For simple, straightforward changes, these tools can indeed be effective, catching style violations, anti-patterns, and obvious bugs more quickly than a human reviewer.
However, for complex, cloud-native distributed systems with numerous interdependent services, AI-assisted review encounters the same limitations as traditional CI pipelines. These tools often cannot determine whether a change truly functions correctly within its broader context. A modification in one service, while appearing correct in isolation, might silently break a contract with a downstream dependency. Similarly, an AI-generated refactor could introduce a race condition that only surfaces under realistic traffic loads.
These intricate problems necessitate running the code in an environment that closely mimics production. Static analysis, whether performed by humans or AI, cannot fully substitute for this level of contextual validation. The critical bottleneck in the validation process resides much earlier than many teams realize: in the gap between when code is written and when a reviewer can confidently assess its functionality. If a developer generates six pull requests in a day, and each requires over 30 minutes of manual validation, the developer spends more time managing a deployment queue than actively developing software. The agent accelerates writing, and AI review speeds up triage, but everything downstream remains sluggish.
What the Open-Source Crisis Is Actually Telling Us
Open-source repositories are currently experiencing the full, unmitigated force of AI-accelerated code generation due to their inherent lack of contribution control. Maintainers have responded with a range of strategies, including implementing stricter contributor policies, developing reputation systems, utilizing platform tools to gate or filter pull requests, and, in some extreme cases, shutting down projects altogether.
Enterprise teams possess greater control over who submits code, but they often have less visibility into whether the submitter truly understands the code they are presenting. An AI-generated PR from an internal developer or a non-technical team member appears in a review queue identically to a meticulously crafted change from a senior engineer. Without additional context or verification mechanisms, the reviewer lacks the ability to distinguish between these submissions or quickly validate the claimed functionality.
The responses emerging from the open-source community offer valuable insights for enterprises. Projects that are successfully navigating this challenge are not merely adding policies; they are investing in mechanisms that shift the burden of proof back to the contributor. This means requiring demonstrable evidence that the code works, rather than expecting the reviewer to prove that it doesn’t.
How Enterprises Should Respond
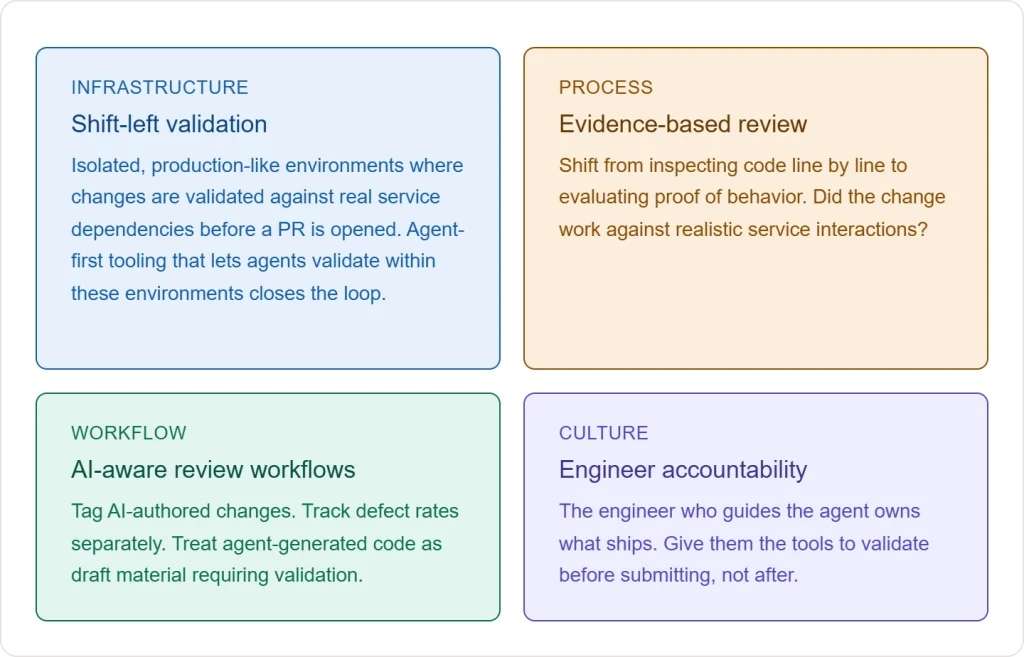
To effectively manage the integration of AI coding agents, enterprises must address the widening gap between code generation and code validation. Every pull request should ideally arrive with concrete evidence of its functionality, not just a declarative claim.

Firstly, validation must be integrated directly into the development loop. Developers and their AI agents need access to isolated, production-like environments where changes can be validated against real service dependencies before a pull request is even opened. This ensures that the review process begins with proof of working code.
Secondly, the review process itself needs to evolve. When AI agents can produce thousands of lines of code per hour, traditional line-by-line review becomes unsustainable. The focus must shift from inspecting code to evaluating evidence of behavior. Key questions should include: Did the change function correctly when interacting with realistic services? Does its behavior align with the specified requirements?
Thirdly, organizations should treat AI-generated code as draft material. This necessitates tagging AI-authored changes, tracking their defect rates separately, and building review workflows that explicitly account for code that the submitter may not fully comprehend.
Finally, accountability cannot be abdicated to AI. The engineer guiding the AI agent remains ultimately responsible for what is deployed. Therefore, these engineers must be equipped with tools that enable them to validate agent-generated code within the development loop. This allows them to submit PRs with confidence, rather than relying on reviewers to identify all potential problems.
The Warning Is Already Here
Open-source repositories serve as the canary in the coal mine for the software development industry. Their inherent openness means they absorb the externalities of cheap code generation first and most visibly. However, the underlying problem—the imbalance between the speed of producing code and the speed of validating it—is not unique to open source; it is a structural issue affecting all software development.
Enterprise organizations that invest heavily in coding agents without a commensurate investment in the infrastructure to validate the output of these agents are creating a pipeline that accelerates the creation of work but does not expedite its completion. This will inevitably lead to an accumulation of pending PRs, extended review times, and rising defect rates. Engineers tasked with reviewing agent output will face the same burnout experienced by open-source maintainers today.
The tooling necessary to bridge this gap exists in various forms. Isolated preview environments, automated end-to-end validation, more intelligent review workflows, and enhanced observability into agent-generated changes are all solvable problems. Companies like Signadot are already assisting teams in validating changes against real service dependencies before code reaches a reviewer.
The critical question is whether organizations will heed the lessons being so starkly demonstrated by the open-source community in real time. The alternative is to wait until they experience the pain firsthand, risking the loss of valuable engineers and compromising their competitive advantage. Investing in these validation capabilities before the backlog becomes unmanageable will be a defining differentiator between engineering teams that successfully leverage coding agents and those that find themselves in crisis.
