
The rapid evolution of artificial intelligence and distributed computing has ushered in an era where multi-agent orchestration systems (MAOS) are becoming central to complex enterprise operations, autonomous systems, and advanced AI applications. However, as these systems gain autonomy and scale, they confront a long-standing challenge in computer science: race conditions. These elusive bugs, characterized by their timing-dependent nature, pose a significant threat to data integrity, system reliability, and operational consistency, often manifesting silently before causing catastrophic failures in production environments.
The Ascendance of Multi-Agent Systems and Concurrency Imperatives
The concept of multi-agent systems, where multiple autonomous entities collaborate to achieve a common goal, has moved from theoretical research to practical implementation, particularly with advancements in large language models (LLMs) and reinforcement learning. Industries from finance to logistics, healthcare, and manufacturing are exploring MAOS for tasks such as automated customer support, supply chain optimization, fraud detection, and even scientific discovery. Tools and frameworks like LangChain, AutoGen, and CrewAI have democratized the development of these systems, leading to a surge in their adoption. Market analysis indicates a robust growth trajectory for AI-powered automation solutions, with projections suggesting multi-agent architectures will play an increasingly critical role in scaling AI capabilities across diverse sectors.
Historically, concurrency challenges have been a cornerstone of computer science since the advent of multi-threaded processors and distributed systems in the mid-20th century. Operating systems, databases, and network protocols have long grappled with ensuring data consistency when multiple processes or threads access shared resources simultaneously. Early solutions involved hardware-level atomic operations, software locks, and semaphores. The current wave of MAOS, however, introduces new layers of complexity. Unlike traditional concurrent programs, which often operate within a single process or tightly controlled distributed environment, LLM-based agents are inherently non-deterministic, communicate asynchronously, and often interact with diverse external services and mutable shared states (e.g., vector databases, shared memory stores, API caches). This dynamic, unpredictable interplay makes race conditions not merely an edge case, but an expected and critical design consideration.
Unpacking Race Conditions in Distributed AI Architectures
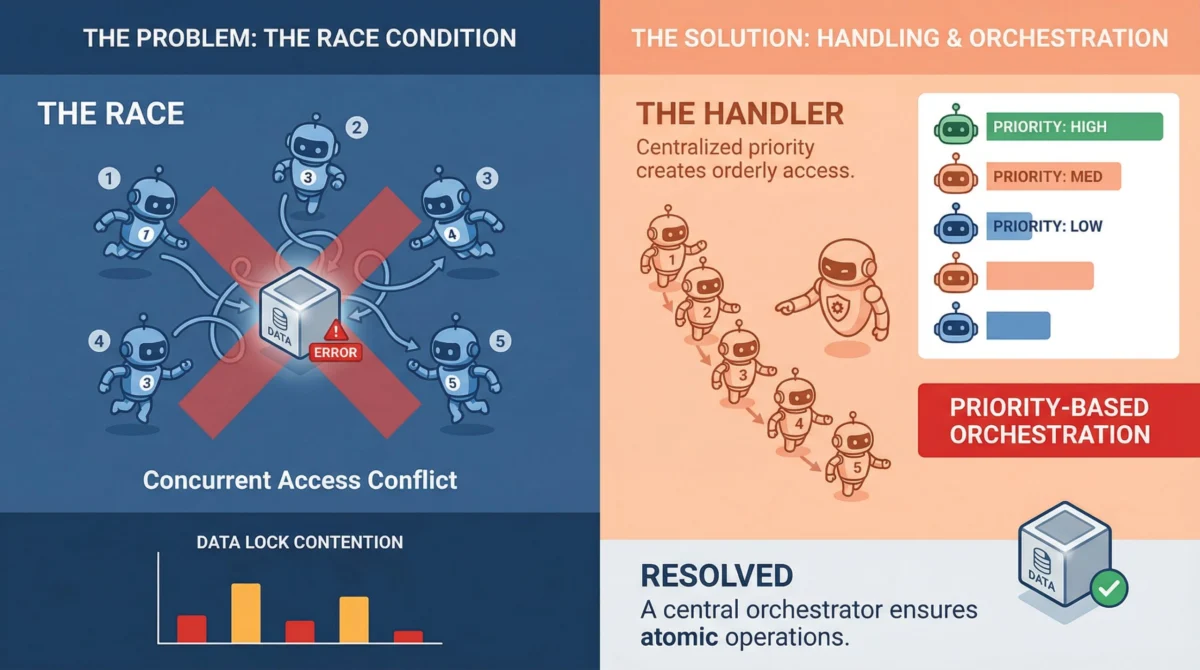
At its core, a race condition occurs when two or more agents attempt to read, modify, or write to a shared resource concurrently, and the final outcome is dependent on the precise, unpredictable timing of their execution. While a single-threaded process guarantees sequential execution, MAOS thrive on parallelism. This parallel execution, while efficient, opens numerous windows for data corruption.
Consider an AI-powered financial trading platform where multiple agents are responsible for executing trades and updating an account balance. If Agent A reads a balance of $100, and simultaneously Agent B also reads $100, then Agent A processes a deposit of $50 (resulting in $150) and Agent B processes a withdrawal of $20 (resulting in $80), the final balance will incorrectly reflect either $150 or $80, depending on which agent writes last. The expected outcome of $130 is lost. This "lost update" problem is a classic race condition. Other forms include "dirty reads" (reading data that hasn’t been committed), "non-repeatable reads" (reading the same data twice and getting different values), and "phantom reads" (when a query executed twice returns different sets of rows).
What makes these issues particularly insidious in MAOS is their often silent nature. Unlike a hard crash, a race condition might simply lead to subtly incorrect data or an inconsistent system state. Agent A might read a document, Agent B updates it half a second later, and Agent A then writes back a stale version, overwriting Agent B’s changes without any error messages. The system appears operational, but the underlying data integrity is compromised, leading to incorrect decisions by subsequent agents, flawed analytics, or even regulatory non-compliance. These silent corruptions can propagate through complex pipelines, making root cause analysis exceptionally difficult, especially in production environments where high traffic and complex interactions obscure the precise sequence of events. The financial implications of such errors can be substantial, ranging from incorrect financial reporting to compromised customer data or flawed business intelligence, potentially costing enterprises millions in rectifications, lost revenue, and reputational damage.
Exacerbating Factors in LLM-Driven Multi-Agent Pipelines
Several characteristics inherent to modern multi-agent systems, particularly those leveraging LLMs, amplify their vulnerability to race conditions:
- Asynchronous Frameworks and Message Brokers: Many MAOS are built atop asynchronous programming models (e.g.,
asyncioin Python) and rely heavily on message brokers (e.g., RabbitMQ, Kafka, Redis Streams) for inter-agent communication and task distribution. While these technologies are excellent for scalability and decoupling, they abstract away direct control over execution timing. Messages might be processed out of order if not explicitly guaranteed, and race conditions can arise from agents concurrently consuming from a queue or updating a shared state in response to messages. - Non-Determinism of LLM Inference: Unlike traditional computational tasks with predictable execution times, LLM inference can vary wildly in duration. Factors such as model size, complexity of the prompt, current server load, and network latency to external APIs can cause an agent’s processing time to fluctuate from milliseconds to several seconds. This non-determinism makes it incredibly challenging to predict when an agent will read or write to a shared resource, creating larger windows of vulnerability for race conditions.
- Distributed Shared State: MAOS frequently interact with various distributed data stores, including vector databases for contextual retrieval, object storage for large files, and shared memory caches for transient data. Each of these distributed resources can become a point of contention if multiple agents attempt to modify the same data concurrently without proper synchronization mechanisms. Managing consistency across these disparate, distributed states is a monumental task.
- Communication Patterns: The architectural choice for agent communication profoundly impacts race condition susceptibility. Systems relying on agents directly manipulating a central shared object or a specific database row are inherently more prone to write conflicts. Conversely, systems designed around immutable event streams or message passing, where agents communicate by sending copies of data rather than modifying shared originals, tend to mitigate certain classes of race conditions by design. This highlights that many race conditions are not just concurrency issues, but also symptoms of suboptimal architectural patterns.
Strategic Mitigation: Engineering Robustness into MAOS
Addressing race conditions in multi-agent systems requires a multifaceted approach, blending established concurrency control techniques with architectural patterns tailored for distributed, autonomous agents.
1. Locking Mechanisms: Controlled Access to Critical Sections
The most direct method to prevent concurrent access to shared resources is through locking.
- Pessimistic Locking: This strategy involves an agent acquiring an exclusive lock on a resource before it begins reading or modifying it, preventing any other agent from accessing it until the lock is released. While guaranteeing correctness, pessimistic locking can significantly reduce parallelism and introduce the risk of deadlocks if not managed carefully. It’s best suited for high-contention scenarios where data integrity is paramount and the overhead of blocking is acceptable. Databases typically offer row-level or table-level pessimistic locks.
- Optimistic Locking: In contrast, optimistic locking assumes that conflicts are rare. Agents read data along with a version identifier (e.g., a timestamp or version number). When an agent attempts to write back its modified data, it checks if the version identifier has changed since it last read. If it has, the write is rejected, and the agent must re-read the latest data and retry the operation. This approach maximizes parallelism but requires robust retry logic and is more suitable for low-contention scenarios. Many modern database systems and ORMs support optimistic locking through version columns.
- Distributed Locks: For shared resources across different processes or machines, distributed locking mechanisms are essential. Technologies like Apache ZooKeeper, Redis with Redlock, or cloud provider services (e.g., AWS DynamoDB with conditional writes) provide ways to coordinate exclusive access across a distributed system, ensuring only one agent holds a specific lock at a time.
2. Queuing and Event-Driven Architectures: Decoupling and Serialization
- Queuing: For task assignment and resource consumption, queues act as natural serialization points. Instead of multiple agents simultaneously polling and potentially grabbing the same task from a shared list, tasks are pushed into a queue, and agents consume them one at a time. Systems like RabbitMQ, Apache Kafka, or even a robust database table with advisory locks can manage this effectively. Queues ensure that tasks are processed in a defined order (or at least one at a time by different consumers), eliminating race conditions for that specific access pattern.
- Event-Driven Architectures (EDA): Moving beyond simple task queues, EDAs promote loose coupling and reactive processing. Instead of agents directly modifying shared state, they emit immutable events when their work is done. Other agents listen for these events and react accordingly. For example, Agent A processes an input and emits a "DocumentProcessed" event, which Agent B then consumes to perform the next step. This paradigm naturally reduces the temporal overlap where two agents might be contending for the same resource, enhancing scalability and resilience. Technologies like Apache Kafka, AWS EventBridge, or Google Cloud Pub/Sub are central to implementing EDAs.
3. Idempotency: Resilience to Retries and Duplicates
Even with robust locking and queuing, transient network issues, timeouts, or agent failures can lead to retries. If these retries are not idempotent, they can result in duplicate operations, compounding errors, or inconsistent state. Idempotency means that performing an operation multiple times yields the same result as performing it once.
For MAOS, implementing idempotency often involves including a unique operation ID (e.g., a UUID) with every write or transaction. If the system receives an operation with an ID it has already processed, it simply skips the duplicate, ensuring that retries do not cause unintended side effects. This is particularly crucial for operations that modify data, trigger external workflows, or consume from queues. Building idempotency into agents from the outset, rather than attempting to retrofit it, is a critical design choice that significantly enhances system reliability and simplifies debugging. Many APIs and databases offer built-in support for idempotent operations or allow for their implementation via unique constraints.
4. Atomic Operations: Leveraging Underlying System Guarantees
For simple, fundamental operations, leveraging atomic operations provided by the underlying infrastructure is often the cleanest solution. Instead of breaking an operation into multiple read-modify-write steps, atomic operations guarantee that the entire sequence executes as a single, indivisible unit, precluding interference from other agents. For example, database systems provide atomic INCREMENT operations, and some key-value stores offer Compare-and-Swap (CAS) primitives. These operations offload the complexity of concurrency control to highly optimized, battle-tested systems, effectively eliminating the race for specific, simple updates.
Proactive Detection: Testing for the Elusive Bug
The most challenging aspect of race conditions is their non-deterministic nature, making them notoriously difficult to reproduce in controlled testing environments. They often emerge only under specific load conditions, precise timing sequences, or complex interactions that are hard to simulate.
- Stress and Load Testing: Intentionally subjecting MAOS to high concurrency and significant load is crucial. Tools like Locust, k6, or even custom scripts using
ThreadPoolExecutororasynciowith many concurrent tasks can simulate the kind of overlapping execution that exposes contention bugs. Monitoring key performance indicators (KPIs) and data consistency during these tests can reveal hidden issues before production deployment. - Chaos Engineering: Moving beyond traditional load testing, chaos engineering involves intentionally injecting faults into a system to test its resilience. This could include introducing network latency between agents, artificially delaying agent responses, or inducing resource contention (e.g., CPU, memory) to stress the concurrency mechanisms and expose race conditions that might only appear under degraded conditions.
- Property-Based Testing: This advanced testing technique involves defining "properties" or invariants that should always hold true, regardless of the order of operations or specific inputs. Randomized tests then attempt to violate these properties by generating a vast array of inputs and execution sequences. For MAOS, this could involve asserting data consistency properties across multiple concurrent agent interactions. While not a silver bullet, property-based testing can uncover subtle consistency issues that deterministic unit and integration tests often miss.
- Enhanced Monitoring and Observability: Even with rigorous testing, some race conditions may only surface in production. Comprehensive monitoring, detailed logging, and distributed tracing are indispensable. Tools like OpenTelemetry can provide end-to-end visibility across agent interactions, allowing developers to reconstruct the sequence of events leading to a data inconsistency. Alerting on unexpected state changes, data anomalies, or specific error patterns can help detect the symptoms of a race condition even if the root cause isn’t immediately apparent.
Implications for the Future of AI
Effectively handling race conditions is not just a technical necessity; it has profound implications for the broader adoption and reliability of AI systems. Trust in autonomous AI hinges on its ability to operate consistently and correctly, particularly when making critical decisions or managing sensitive data. Systems plagued by unpredictable data corruption will quickly erode user and enterprise confidence.
Moreover, the scalability of MAOS is directly tied to their ability to manage concurrency. As AI applications grow in complexity and user base, the underlying orchestration must scale without introducing new points of failure. Robust concurrency control enables MAOS to handle increasing workloads efficiently and reliably. The cost of failing to address these issues early can be astronomical, encompassing not only direct financial losses from errors but also significant reputational damage, lengthy debugging cycles, and delays in product development.
In conclusion, while multi-agent orchestration systems promise transformative capabilities, they also inherit the complex challenges of distributed computing. Race conditions, though often elusive, demand intentional design and rigorous engineering. By integrating idempotent operations, event-driven communication, intelligent locking strategies, and robust queuing mechanisms, coupled with proactive testing and comprehensive observability, developers can build MAOS that are not merely functional but truly reliable, scalable, and trustworthy. The future of AI, particularly in its autonomous and collaborative forms, depends on mastering these foundational principles of concurrency.
