
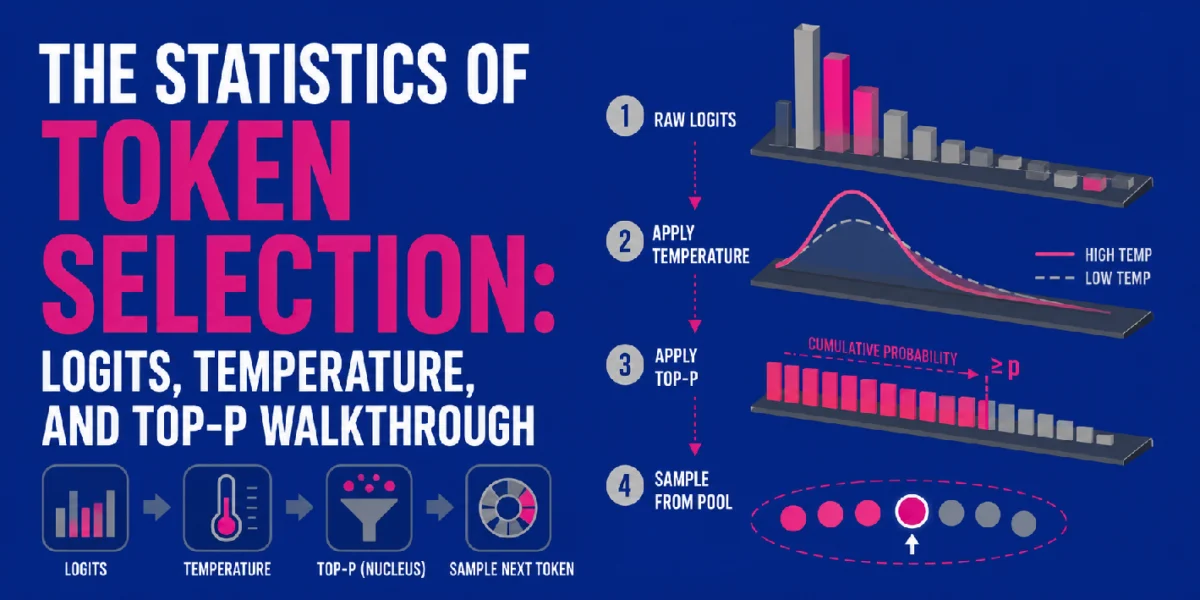
In the rapidly evolving landscape of artificial intelligence, understanding the intricate mechanisms that govern the output of large language models (LLMs) is paramount. This article delves into the sophisticated interplay of logits, temperature, and top-p sampling, three fundamental parameters that orchestrate next-token prediction, dictating an LLM’s coherence, relevance, and even its creative flair. As LLMs become increasingly integrated into daily operations and creative endeavors, a clear comprehension of these statistical controls is essential for both developers seeking to fine-tune model behavior and users aiming to optimize their interactions with AI.
The Rise of Generative AI and the Challenge of Controlled Output
The past decade has witnessed an unprecedented surge in the capabilities of large language models, driven by advancements in transformer architectures and the availability of vast datasets. From generating human-quality text to translating languages and writing code, LLMs have redefined the boundaries of what AI can achieve. However, the sheer scale and complexity of these models present a unique challenge: how to reliably guide their output to meet specific user needs. Unlike deterministic algorithms, LLMs operate on probabilistic principles, generating text token by token. Ensuring that each successive token contributes to a coherent, contextually appropriate, and desired outcome requires sophisticated control mechanisms at the very final stages of their internal processing.
Initially, early generative models often relied on simple "greedy" decoding, selecting the token with the highest probability at each step. While straightforward, this approach frequently led to repetitive, bland, or locally optimal but globally suboptimal outputs. The necessity for more nuanced control soon became apparent, paving the way for the development and refinement of probabilistic sampling techniques. These techniques move beyond merely picking the most probable word, introducing elements of controlled randomness and strategic selection from a distribution of possibilities, thereby enabling the nuanced behaviors we now associate with advanced LLMs. This evolution from rigid, deterministic generation to flexible, probabilistic sampling marks a significant milestone in AI’s journey towards more human-like and versatile communication.
Logits: The Unnormalized Foundation of Prediction
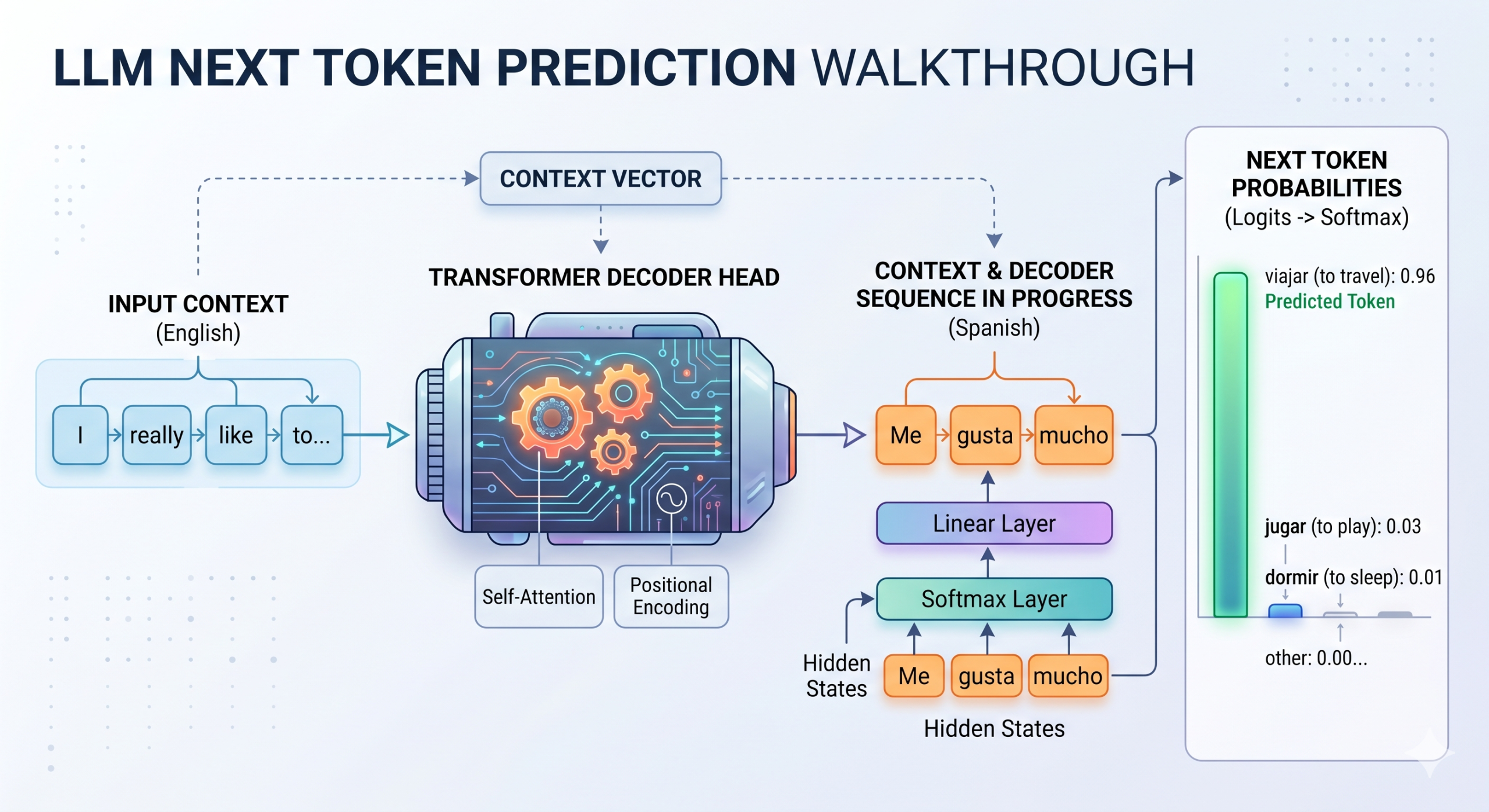
At the heart of an LLM’s predictive engine are logits. In the context of neural networks, and specifically within the final layers of transformer models, logits represent the raw, unnormalized scores assigned to each possible token in the model’s vocabulary. Before any probability calculations occur, these scores provide a numerical indication of how likely the model considers each token to be the next in a sequence, based on the accumulated linguistic knowledge and contextual understanding derived from the input text.
When an LLM processes an input, its internal layers – comprising self-attention mechanisms and feed-forward networks – transform the initial token embeddings into increasingly rich "hidden states." These hidden states encapsulate the semantic and syntactic information gleaned from the preceding text. The final linear layer of the transformer then projects these hidden states onto a vector whose dimension equals the size of the model’s vocabulary. Each element in this vector is a logit, corresponding to a specific token. For instance, if an LLM is tasked with continuing the sentence "The capital of France is…", it might output a high positive logit for "Paris," a moderate positive logit for "London" (if the model has some uncertainty or potential for error), and a strong negative logit for "banana." These raw logit values are unbounded, ranging from negative infinity to positive infinity, making them difficult to interpret directly as probabilities.
Historically, the concept of logits has roots in classical machine learning, particularly in models like logistic regression and softmax regression, where they served as the input to activation functions that normalized scores into probabilities. In LLMs, this principle remains fundamental. The magnitude of a logit directly correlates with the model’s "confidence" or "preference" for a particular token; higher logits indicate stronger candidacy. The subsequent step, typically involving a softmax function, is crucial for transforming these raw scores into a coherent probability distribution where all token probabilities sum to one, thereby providing a clear, interpretable likelihood for each vocabulary item.
Temperature: Modulating Determinism and Creativity
Once logits are generated, the first parameter to influence their transformation into probabilities is temperature. Introduced as a hyperparameter in statistical physics (specifically in the Boltzmann distribution context) and later adapted for neural networks, temperature scales the logits before they are fed into the softmax function. This scaling has a profound effect on the shape of the resulting probability distribution and, consequently, on the determinism or randomness of the next token selection.
A higher temperature value (e.g., 1.0 or greater) makes the probability distribution flatter and more uniform. By increasing the relative "spread" of the logit values, it lessens the difference between high-logit tokens and lower-logit tokens. This means that tokens with slightly lower raw scores become relatively more probable, increasing the likelihood of sampling a less obvious, more "creative" or "surprising" token. For example, if the top logits are 12.5, 8.2, and 5.0, a high temperature might make their corresponding probabilities (after softmax) 0.3, 0.25, and 0.2, respectively, allowing for a wider range of viable options. This behavior is highly desirable in applications like creative writing, brainstorming, or generating diverse conversational responses, where a degree of unpredictability is valued.
Conversely, a lower temperature value (e.g., 0.1 to 0.5) sharpens the probability distribution. It accentuates the differences between logits, making high-logit tokens significantly more probable and dramatically reducing the probabilities of lower-logit tokens. As temperature approaches zero, the sampling process becomes increasingly deterministic, effectively converging towards greedy decoding where only the token with the absolute highest logit is chosen. This characteristic is crucial for applications requiring factual accuracy, consistency, and predictability, such as code generation, legal document drafting, or structured data extraction. For instance, in a medical diagnostic tool powered by an LLM, a low temperature would ensure that the model sticks to the most probable and clinically relevant terms, minimizing the risk of generating speculative or misleading information. The careful selection of temperature thus becomes a critical tuning knob for balancing an LLM’s output between strict adherence to the most likely path and exploration of alternative, potentially more novel, continuations.
Top-P Sampling: Nucleus Filtering for Focused Diversity
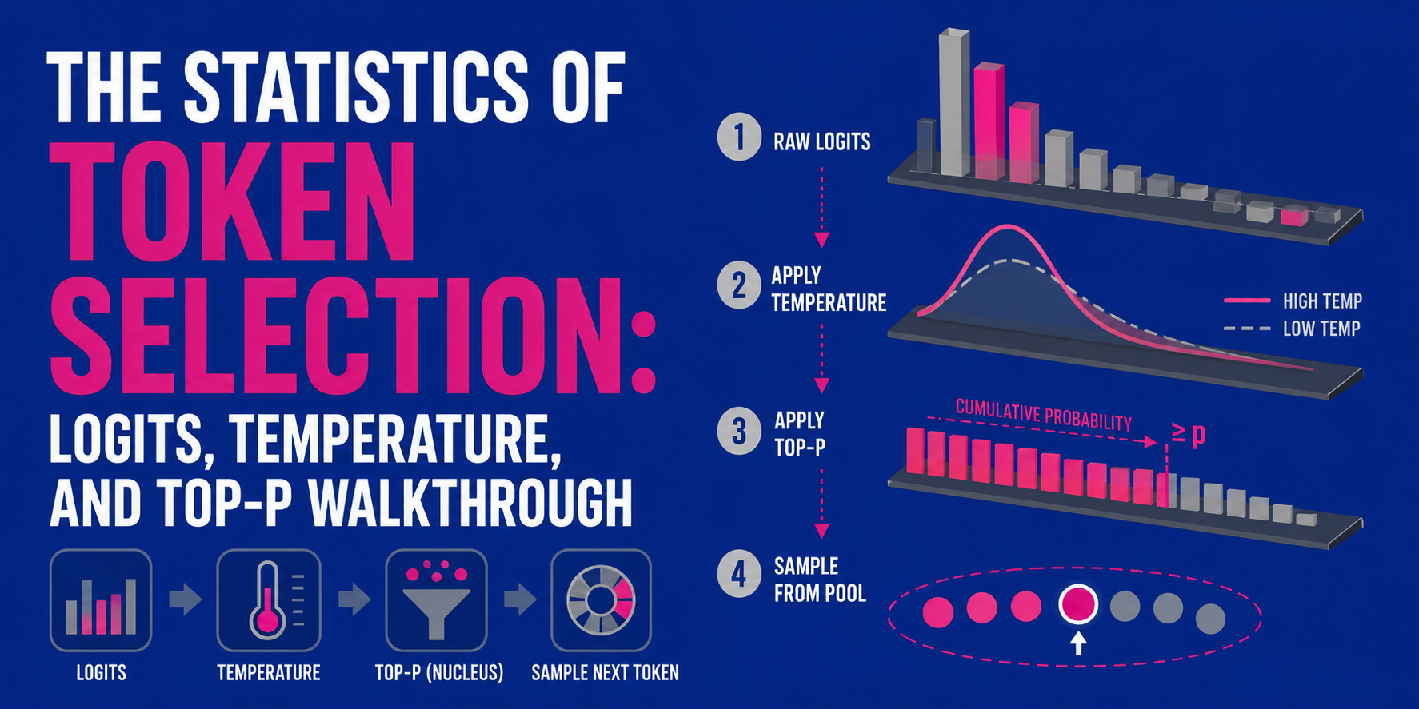
While temperature influences the shape of the entire probability distribution, top-p sampling (also known as nucleus sampling) provides a more direct mechanism for controlling the set of tokens from which the next word is chosen. Introduced to address some of the limitations of older methods like top-k sampling (which selects from the ‘k’ most probable tokens regardless of their cumulative probability), top-p sampling dynamically prunes the vocabulary to a "nucleus" of the most probable tokens whose cumulative probability exceeds a predefined threshold, ‘p’.
After logits have been scaled by temperature and converted into a probability distribution via softmax, the top-p mechanism comes into play. The model sorts all possible tokens by their probability in descending order. It then iteratively sums these probabilities, starting from the most probable token, until the cumulative sum reaches or exceeds the specified ‘p’ value. All tokens included in this cumulative sum constitute the "nucleus pool." Any tokens outside this pool, regardless of their individual probability, are discarded for the current sampling step. The final next token is then randomly sampled from this reduced nucleus pool.
For example, if ‘p’ is set to 0.9, the model will select the smallest set of most probable tokens whose combined probability is at least 90%. If the probabilities for "travel," "play," "sleep," "eat," and "read" are 0.4, 0.3, 0.15, 0.1, and 0.05 respectively, and p=0.9:
- "travel" (0.4)
- "play" (0.3) -> Cumulative 0.7
- "sleep" (0.15) -> Cumulative 0.85
- "eat" (0.1) -> Cumulative 0.95 (exceeds 0.9)
The nucleus pool would then consist of "travel," "play," "sleep," and "eat." "Read" would be excluded. The final token would be randomly sampled from these four.
The advantage of top-p over top-k is its adaptability. In contexts where the probability distribution is sharp (i.e., a few tokens are highly probable), top-p will select a small, focused nucleus. In contexts where the distribution is flat (many tokens have similar probabilities), top-p will select a larger, more diverse nucleus. This dynamic sizing of the sampling pool allows for more robust and context-aware control over diversity, preventing the generation of nonsensical tokens that might be included in a fixed top-k list in a flat distribution, while still allowing for variety when the distribution calls for it. A higher ‘p’ value (e.g., 0.95 or 0.99) leads to a larger nucleus and more diverse outputs, while a lower ‘p’ value (e.g., 0.5 or 0.7) creates a smaller, more concentrated nucleus, yielding more predictable and focused results.
The Algorithmic Dance: A Step-by-Step Breakdown
The process of next-token prediction in LLMs is a precisely orchestrated sequence involving these three critical elements:
-
Logit Generation: Based on the input prompt and previously generated tokens, the LLM’s transformer architecture computes the raw, unnormalized logit scores for every token in its extensive vocabulary. This vector of logits is the foundational output of the model’s "thinking" process.
-
Temperature Scaling: Before conversion to probabilities, these raw logits are scaled by the temperature parameter. This step is crucial for modulating the "sharpness" or "flatness" of the eventual probability distribution, influencing the degree of determinism or randomness in the subsequent sampling. A temperature of 1.0 applies no scaling, while values below 1.0 amplify differences and values above 1.0 flatten them.
-
Softmax Normalization: The scaled logits are then passed through a softmax function. This mathematical operation transforms the unbounded logit values into a discrete probability distribution over the entire vocabulary, ensuring that all probabilities are positive and sum to 1. This normalized distribution now clearly indicates the likelihood of each token being the next in the sequence.
-
Top-P Filtering (Nucleus Selection): With the probability distribution in hand, top-p sampling is applied. Tokens are sorted by their probability in descending order, and a nucleus pool is formed by cumulatively summing probabilities until the threshold ‘p’ is met. Tokens outside this nucleus are effectively excluded from consideration for the current step.
-
Stochastic Sampling: Finally, the next token is randomly sampled from the refined nucleus pool. This stochastic step introduces the element of controlled randomness, preventing the model from always choosing the absolute most probable token and allowing for a richer, more varied output. The specific token chosen is then appended to the generated sequence, and the entire process repeats for the next token prediction until a stop condition (e.g., maximum length, end-of-sequence token) is met.
This multi-step pipeline ensures that LLMs can generate text that is not only statistically plausible but also adheres to desired characteristics of creativity, coherence, and relevance, striking a delicate balance between predictability and novelty.
Industry Perspectives and Expert Insights
The meticulous control offered by logits, temperature, and top-p sampling is frequently highlighted by AI researchers and developers as a cornerstone of practical LLM deployment. Dr. Anya Sharma, a lead researcher at a prominent AI lab, states, "Without these decoding parameters, LLMs would either be painfully repetitive or wildly incoherent. They are the essential levers we pull to align model behavior with human expectations, whether it’s generating precise code or imaginative poetry."
Developers routinely spend considerable effort tuning these parameters to optimize user experience. "For a customer support chatbot, a low temperature and tight top-p are non-negotiable," explains Mark Jenkins, an AI product manager. "We need consistent, factual, and on-brand responses. Conversely, for our creative writing assistant, we push temperature and top-p higher to encourage unique phrasing and unexpected narrative twists. It’s a continuous calibration." This sentiment underscores the strategic importance of these controls in tailoring LLM performance to diverse applications, impacting everything from enterprise solutions to consumer-facing AI tools. The choice of these parameters can significantly influence user satisfaction and the overall utility of an LLM in a given context.
Practical Applications and Strategic Tuning
The ability to manipulate these parameters offers powerful control over LLM output, enabling developers to tailor models for a vast array of applications:
-
Factual Recall and Precision (Low Temperature, Low Top-P): For tasks demanding high accuracy and consistency, such as answering specific questions, summarizing factual documents, or generating code snippets, a low temperature (e.g., 0.1-0.3) and a restrictive top-p (e.g., 0.5-0.7) are typically employed. This configuration prioritizes the most probable tokens, minimizing the introduction of speculative or erroneous information. In critical applications like medical diagnostics or legal research, this deterministic approach is vital to prevent "hallucinations" – the generation of factually incorrect but plausible-sounding text.
-
Creative Content Generation (High Temperature, High Top-P): When the goal is novelty, diversity, and imaginative output, such as writing fiction, generating marketing copy, or brainstorming ideas, higher temperature values (e.g., 0.7-1.0) and a more expansive top-p (e.g., 0.9-0.99) are preferred. This encourages the model to explore a wider range of linguistic possibilities, leading to more varied and less predictable results, which can spark creativity and overcome writer’s block. For instance, a generative art prompt might leverage higher settings to produce diverse interpretations of a theme.
-
Balanced Dialogue Systems (Moderate Temperature, Moderate Top-P): For interactive applications like chatbots or virtual assistants, a balanced approach is often sought. A moderate temperature (e.g., 0.5-0.7) and a mid-range top-p (e.g., 0.8-0.9) can strike a balance between generating engaging, natural-sounding responses and maintaining coherence and relevance to the conversation. This prevents overly repetitive responses while still keeping the dialogue on track.
The optimal values for temperature and top-p are not universal; they are context-dependent and often discovered through empirical testing and fine-tuning against specific performance metrics for each application. Developers often employ A/B testing or user feedback loops to determine the most effective parameter settings for their unique use cases.
Challenges, Ethical Considerations, and Future Directions
While logits, temperature, and top-p sampling provide powerful controls, they are not without their complexities and implications. One significant challenge lies in mitigating bias inherent in the training data. If the underlying logits reflect societal biases, even carefully tuned sampling parameters might still propagate them, albeit in a more diverse or deterministic fashion. Researchers are actively exploring methods to de-bias logit distributions before sampling or to introduce fairness constraints during the decoding process.
Another area of ongoing research involves developing more sophisticated decoding strategies that go beyond simple token-by-token sampling. Techniques like beam search, which explores multiple candidate sequences simultaneously, and contrastive search, which aims to maximize diversity while minimizing repetition, are being refined. These methods often integrate or build upon the principles of temperature and top-p but introduce additional layers of strategic decision-making to optimize for specific output qualities. The goal is to achieve even greater control over coherence, factuality, and stylistic nuances without sacrificing the computational efficiency required for real-time applications.
The ethical implications of these controls are also gaining prominence. As LLMs become more persuasive and autonomous, the ability to fine-tune their output for specific emotional tones, persuasive language, or even to generate misinformation, raises concerns. Responsible AI development demands that practitioners not only understand these parameters but also consider their potential for misuse and implement safeguards to promote beneficial and ethical AI interactions. The dialogue around these decoding parameters is thus expanding beyond technical optimization to encompass broader societal and ethical considerations.
Conclusion
The mechanics of logits, temperature, and top-p sampling represent a sophisticated statistical framework that underpins the generation of intelligent text by large language models. Logits provide the raw, unnormalized scores, acting as the model’s initial preference for the next token. Temperature then acts as a crucial scaling factor, modulating the resulting probability distribution to control the balance between predictable determinism and creative variability. Finally, top-p sampling dynamically filters this distribution, creating a "nucleus" of the most probable tokens from which the final selection is made, ensuring focused diversity.
Together, these three parameters form a powerful toolkit for developers and researchers, enabling them to precisely sculpt the behavior of LLMs to suit an ever-expanding range of applications. From ensuring factual accuracy in critical enterprise systems to fostering imaginative narratives in creative tools, the mastery of these statistical controls is indispensable. As LLM technology continues to advance, a deeper understanding and responsible application of these fundamental decoding strategies will remain central to unlocking the full potential of artificial intelligence and shaping its beneficial integration into our world.
