

The rapid ascent of artificial intelligence agents from conceptual prototypes to essential enterprise tools has necessitated a profound understanding of their underlying technological architecture. Far from being monolithic entities, these sophisticated agents are built upon a complex interplay of seven distinct layers, each critical to their functionality, reliability, and ultimate success in production environments. This comprehensive guide delves into each layer, offering insights into their roles, current market leaders, and strategic considerations for deployment.
The Rise of Autonomous AI Agents: A New Era in Automation
The vision of an AI agent autonomously researching competitors, extracting pricing data, synthesizing reports, and delivering them to a Slack channel by a specified deadline, all within moments of a prompt, is no longer futuristic. This operational agility is driving a seismic shift in enterprise technology. Gartner, a leading research and advisory company, projected a near-vertical adoption curve, predicting that 40% of enterprise applications would integrate task-specific AI agents by the close of 2026, a dramatic increase from less than 5% in 2025. This aggressive timeline underscores the urgent need for engineers and technical leadership to grasp the intricacies of the entire AI agent stack, extending beyond individual components. The success of these deployments hinges not merely on the advanced capabilities of the AI model itself, but on the robust orchestration and support provided by the six layers beneath it.
Layer 1: The Foundation Model – The Agent’s Cognitive Core
At the pinnacle of the AI agent stack lies the Foundation Model, serving as the agent’s cognitive engine. This is where complex reasoning, natural language comprehension, and crucial decision-making processes occur. All other layers in the stack either supply essential context to this core or execute actions based on its outputs.
The competitive landscape for foundation models is dominated by a few key players. As of 2026, OpenAI’s GPT-5.5, Anthropic’s Claude Sonnet 4.6 (with Claude Opus 4.8 preferred for more demanding reasoning tasks), and Google’s Gemini 3.1 Pro represent the leading proprietary options. Open-weight models such as Meta’s Llama 4 and Mistral Large 3 offer compelling alternatives, providing greater control over deployment and data residency, albeit with increased infrastructure overhead for self-hosting.
Each model presents unique advantages. GPT-5.5 is lauded for its speed in routine tasks and its reliable tool-calling capabilities, benefiting from a mature ecosystem and a vast developer community that has collectively addressed numerous edge cases. Claude Sonnet 4.6 excels in processing extensive documents and adhering to nuanced instructions, offering a cost-effective solution for data-intensive workflows. For tasks demanding deeper, longer-horizon reasoning, Claude Opus 4.8 is the preferred choice. Google’s Gemini 3.1 Pro distinguishes itself with an impressive 1 million token context window, a significant asset for agents tasked with analyzing large codebases or expansive knowledge repositories in a single pass. The distinction between "standard" and "reasoning" model families, prominent in 2025, has largely dissolved, with major providers integrating adjustable reasoning effort levels directly into their models (e.g., GPT-5.5’s ‘xhigh’ setting, Claude’s ‘effort’ parameter, Gemini’s ‘thinking levels’). For most agentic workflows, default or low-effort settings strike an optimal balance between speed and cost, while higher effort levels are justified for critical planning or mathematical precision.
Layer 2: The Orchestration Framework – The Agent’s Nervous System
If the foundation model is the brain, the orchestration framework functions as the agent’s nervous system, managing the intricate flow of control. It dictates the agent’s subsequent actions, when to invoke specific tools, how to process their outputs, and how to maintain coherence throughout multi-step reasoning loops.
Most frameworks adopt the ReAct (Reasoning and Acting) pattern. This iterative loop involves the agent generating a thought, selecting an action, executing that action via a tool, observing the result, and then re-evaluating its next step. While seemingly straightforward, this layer is frequently the source of production failures, manifesting as incorrect tool calls, infinite loops, or the agent’s inability to determine when a task is complete.
The selection of an orchestration framework is contingent on the agent’s intended purpose. For single-agent task execution, frameworks like LangGraph or LangChain are popular choices due to their streamlined approach. For complex scenarios involving coordinated teams of specialized agents, CrewAI or AutoGen offer robust multi-agent capabilities. Microsoft’s Semantic Kernel is tailored for enterprise environments, providing deep integration with Microsoft ecosystems. Meanwhile, LlamaIndex specializes in document-heavy retrieval workflows, enhancing the efficiency of information access.
Layer 3: Memory Systems – Beyond Statelessness
A fundamental characteristic of large language models (LLMs) is their statelessness; each interaction begins without recall of previous exchanges unless context is explicitly provided. While acceptable for one-off queries, this poses a significant challenge for agents requiring conversational continuity, user preference retention, or the ability to build upon past work.
Research by Atlan on AI agent memory revealed a critical insight: 95% of enterprise generative AI pilot programs in 2025 yielded zero measurable return on investment, primarily due to issues with context readiness rather than deficiencies in model quality. This highlights the indispensable role of a robust memory layer.

Production AI agents typically employ four types of memory:
- Working Memory: Short-term, in-context memory within the current session, managed by techniques like message trimming to fit within token limits.
- Episodic Memory: A longer-term log of past interactions, often summarized and injected into the system prompt to provide historical context without consuming excessive tokens.
- Semantic Memory: Leverages vector databases (discussed in Layer 4) to store and retrieve relevant information from vast knowledge bases.
- Procedural Memory: Encodes learned behaviors, tool usage patterns, and decision-making strategies, often implicitly through fine-tuning or explicit prompt engineering.
Implementing both working and episodic memory, as demonstrated by LangChain’s recommended patterns, involves maintaining a persistent log (e.g., in a database like SQLite or Postgres for production) and dynamically managing the in-session message history. This ensures that agents can recall past conversations and user preferences, preventing redundant queries and fostering a more personalized, efficient user experience.
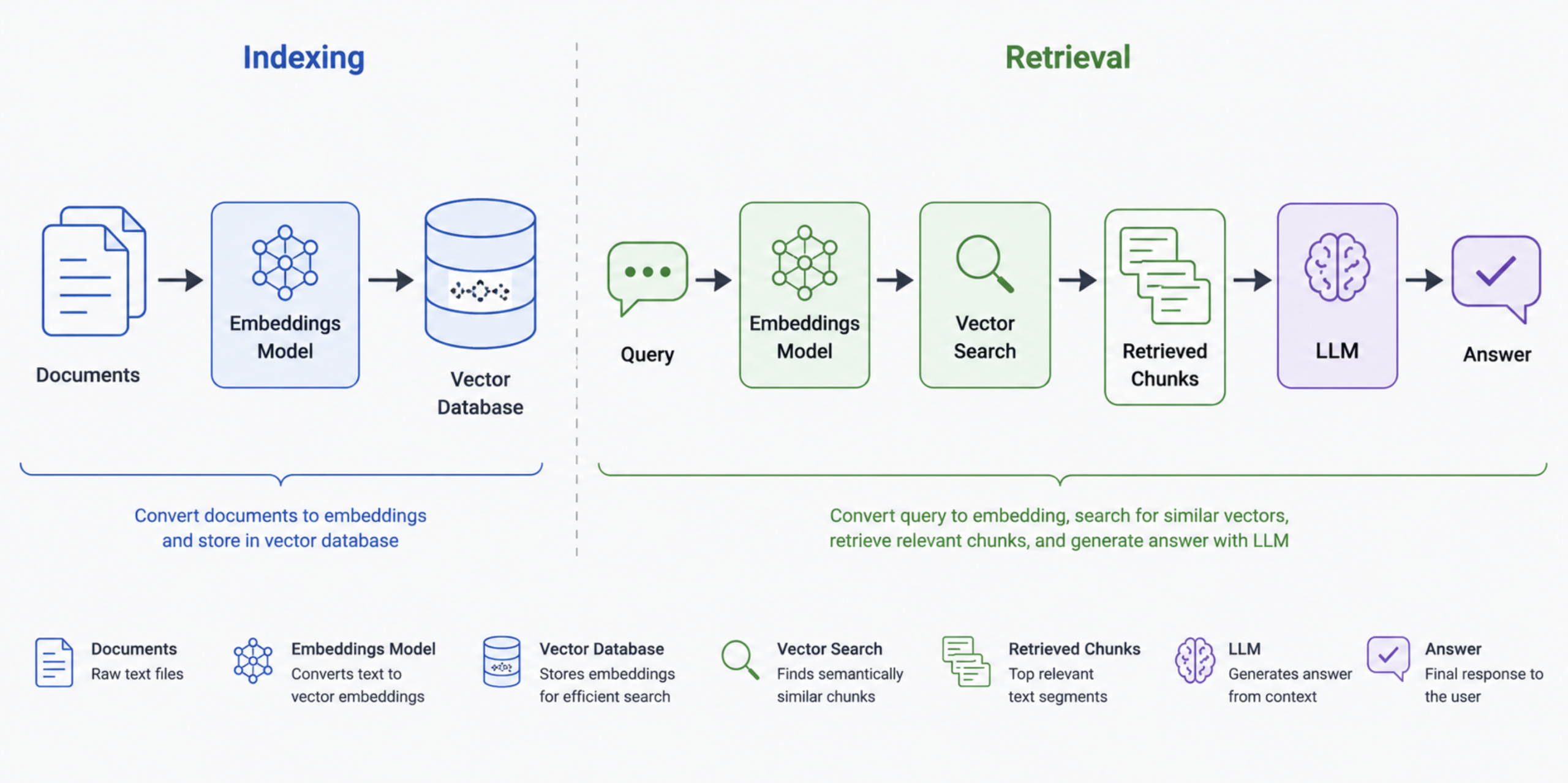
Layer 4: Vector Databases and Retrieval-Augmented Generation (RAG) – Bridging Knowledge Gaps
While foundation models possess extensive general knowledge, they lack specific, proprietary, or real-time information. They are not trained on internal company documents, customer support histories, or recent events beyond their training cutoff dates. Retrieval-Augmented Generation (RAG) directly addresses this limitation by enabling agents to access and incorporate external, up-to-date knowledge.
The RAG mechanism is elegant: proprietary documents are transformed into numerical representations called embeddings, stored in a specialized vector database. Upon a query, the system retrieves only the most semantically relevant document chunks, which are then provided to the LLM as additional context. This ensures the agent’s responses are grounded in accurate, pertinent information, mitigating the risk of hallucination.
The global vector database market’s expansion to $3.2 billion in 2025, with an annual growth rate of 24%, underscores the integral role of retrieval in contemporary AI systems. Key players in this market cater to diverse needs:
- Chroma: A developer-friendly, local-first option ideal for prototyping and small-to-medium production workloads, especially following its significant performance improvements from a 2025 Rust rewrite.
- Pinecone: A fully managed vector database optimized for high-scale, low-latency similarity search, best suited for production RAG deployments where operational overhead is minimized.
- Weaviate: An open-source vector database offering native hybrid search (combining keyword and vector search), suitable for self-hosting or cloud deployment.
- pgvector: A PostgreSQL extension that integrates vector search capabilities directly into existing Postgres databases, making it an excellent choice for organizations already leveraging PostgreSQL in production.
A typical RAG pipeline involves chunking large documents, converting these chunks into high-dimensional vectors using an embedding model (e.g., OpenAI’s text-embedding-3-small), and storing them in a vector database. During query time, the user’s question is also embedded, and the most similar chunks are retrieved to inform the LLM’s response. This process ensures accuracy and relevance, preventing the model from generating plausible but incorrect information.
Layer 5: Tools and External Integrations – Enabling Action in the Real World
An AI agent confined solely to text generation is a costly predictor. Tools are the conduits through which agents interact with and act upon the external world, moving beyond mere conversational capabilities.
Technically, a tool is a function that the LLM can dynamically decide to call. The tool’s capabilities are described in natural language, and its input parameters are defined by a structured schema. The model uses this information to determine when and with what arguments to invoke the tool. Crucially, the model decides to call the function; the actual execution is handled by the underlying code.
Essential tool categories for production agents include:
- Web Search: For accessing real-time, current information.
- Code Execution: For performing calculations, data transformations, or logical operations.
- File I/O: For reading from and writing to documents and data stores.
- API Calls: For connecting to a vast array of external services, from CRM systems to payment gateways.
- Browser Use: For interacting with web interfaces when direct APIs are unavailable.
A notable development in this layer is the Model Context Protocol (MCP), introduced by Anthropic in late 2024. MCP provides a standardized method for models to interface with external tools and data sources, reducing the need for bespoke integration code for every tool. Amazon Bedrock Agents’ native MCP support in 2025 signals a growing industry trend towards unified protocols. The effectiveness of tools heavily relies on their schema design; precise natural language descriptions and well-typed parameter definitions are paramount for reliable tool selection and argument passing, preventing misfires and enhancing agent accuracy.
Layer 6: Observability and Evaluation – Ensuring Trust and Performance
A critical, yet often overlooked, aspect of production AI is that LLMs can fail silently. As observed by the team at Kanerika, a hallucinated answer might still return an HTTP 200 status, masking significant errors. Traditional monitoring systems, designed for binary correctness, are ill-equipped to detect semantic failures where a response is grammatically perfect but factually incorrect. This necessitates a specialized observability layer.
A robust LLM observability setup encompasses three key areas:
- Tracing: Tracks every step of the agent’s execution, including LLM calls, tool invocations, retrieval queries, intermediate reasoning steps, and latency for each component.
- Evaluation: Quantitatively scores agent outputs against crucial metrics like faithfulness (adherence to context), relevance (answering the prompt), and hallucination rate. This often involves research-backed metrics and human-in-the-loop feedback.
- Monitoring: Detects behavioral drift over time, assessing whether the agent’s performance for specific input classes degrades or improves as models and prompts evolve.
Leading observability platforms offer distinct strengths. LangSmith provides deep integration within the LangChain and LangGraph ecosystems, offering the quickest path to comprehensive traces for users of those frameworks. Langfuse, an open-source solution with a permissive MIT license and over 19,000 GitHub stars, is self-hostable and framework-agnostic. Arize Phoenix is recognized for its ML-grade evaluation rigor, offering over 50 research-backed metrics for faithfulness, relevance, safety, and hallucination detection. MLflow’s analysis suggests that framework choice often dictates the optimal observability platform: LangChain users typically benefit most from LangSmith, while those on LlamaIndex or raw API calls might find Phoenix or Langfuse more suitable. Integrating observability, such as Langfuse’s CallbackHandler, allows for automatic capture of every LLM call, tool invocation, token count, and latency, providing an invaluable debugging and quality assurance tool.
Layer 7: Deployment Infrastructure – The Operational Backbone
The transition from a perfectly functioning development agent to a reliable production system often falters at the infrastructure layer. Robust deployment practices are essential to ensure scalability, cost-effectiveness, and maintainability.
Containerization using Docker is a minimum requirement, providing consistent behavior across environments, simplifying dependency management, and streamlining cloud deployments. This approach prevents a class of "environment mismatch" bugs that can disproportionately consume engineering resources.
For the serving layer, two architectural patterns are common:
- Synchronous API (e.g., Flask, FastAPI): Suitable for agents completing tasks within a few seconds, allowing the HTTP connection to remain open.
- Asynchronous Queue (e.g., Celery, AWS SQS, Google Pub/Sub): Preferred for agents involving multiple tool calls, extensive retrieval pipelines, or document processing that may take 30-60 seconds. Clients receive an immediate task ID and poll for results, preventing timeouts and improving user experience.
All major cloud providers now offer managed agent infrastructure. Amazon’s AgentCore, generally available since October 2025, provides dedicated agentic infrastructure for memory management, tool execution, and session handling on AWS. Google Vertex AI Agent Builder is a natural fit for GCP users, featuring native Gemini integration and built-in observability. Azure OpenAI Service, combined with Semantic Kernel, has become the default for Microsoft-centric enterprises, offering enterprise-grade compliance and security.
Cost management is a critical consideration, with three practices making a significant impact: caching (reusing stored responses for identical queries), request batching (grouping non-urgent tasks to reduce per-call overhead), and setting max_iterations in agent executors to prevent runaway loops from incurring excessive token consumption.
Strategic Implementation: Tailoring the Stack to Project Needs
The optimal configuration of the AI agent stack is highly dependent on the project’s lifecycle and specific requirements.
For Prototype stages, prioritizing speed and minimal infrastructure is key:
- Foundation Model: GPT-5.5 (reliable tool-calling, mature ecosystem).
- Orchestration: LangGraph (fast setup, good documentation).
- Memory: In-context only (zero infrastructure overhead).
- Vector DB: Chroma (local, no operations, excellent developer experience).
- Tools: DuckDuckGo and custom
@toolfunctions (no API keys required for basic functionality). - Observability: Langfuse (cloud free tier for one-line setup).
- Deployment: Local / Docker (for rapid iteration and development).
For a Production Startup scaling with control:
- Foundation Model: GPT-5.5 with Claude Sonnet 4.6 as a fallback (reliability with redundancy).
- Orchestration: LangGraph or CrewAI (robust state management and multi-agent support).
- Memory: Episodic (e.g., PostgreSQL for persistence) combined with Semantic (RAG) for comprehensive context.
- Vector DB: Weaviate or Pinecone (for scalable, hybrid search capabilities).
- Tools: A full suite of tools leveraging MCP for standardized integrations.
- Observability: Langfuse self-hosted or Arize Phoenix (for data control and ML-grade evaluations).
- Deployment: Docker with Kubernetes and an asynchronous queue (for production-grade, cost-controlled scaling).
For Enterprise deployments, compliance, security, and integration are paramount:
- Foundation Model: Azure OpenAI or AWS Bedrock (for compliance, data residency, and enterprise-level SLAs).
- Orchestration: Semantic Kernel or LangGraph (supporting enterprise languages and governance needs).
- Memory: Managed memory solutions with comprehensive audit trails (to meet stringent regulatory requirements).
- Vector DB: Weaviate or pgvector (for self-hostable, compliance-ready data management).
- Tools: MCP-based tools that have undergone internal security review and access control.
- Observability: Langfuse self-hosted or Datadog LLM module (for seamless integration with existing enterprise monitoring infrastructure).
- Deployment: AWS AgentCore or Google Vertex AI Agent Builder (for fully managed, governed, and auditable operations).
Conclusion: The Holistic View for Production Readiness
While the foundation model rightfully garners significant attention, the true measure of an AI agent’s production viability lies in the harmonious functioning of its entire seven-layer stack. An agent can stumble at any layer: orchestration failures can lead to stuck reasoning loops; inadequate memory systems can cause critical context loss; flawed retrieval mechanisms can result in confident but incorrect hallucinations. Poorly defined tool schemas can lead to erroneous actions, and a lack of proper observability means these failures remain undetected, potentially eroding trust and value. Finally, insufficient deployment infrastructure can cripple even the most brilliant agent with latency, cost overruns, or operational instability.
Gartner’s prediction that over 40% of agentic AI projects face cancellation by 2027 due to unclear value, escalating costs, and weak governance serves as a stark warning. The majority of these failures will not stem from a suboptimal model choice but from a piecemeal approach to stack construction, lacking a cohesive understanding of inter-layer dependencies. A holistic understanding of the full stack empowers developers and organizations to make informed decisions, navigating trade-offs effectively, and ultimately bridging the gap between a compelling demo and a robust, value-generating production AI agent.
