
Amazon Web Services (AWS) has announced a significant enhancement to its Elastic Container Service (ECS) service auto scaling capabilities, dramatically improving the responsiveness of applications to fluctuating demand. The update introduces support for high-resolution 20-second metrics and advanced metric publishing optimizations, enabling ECS to detect and react to load changes with unprecedented speed. This pivotal advancement translates into a 76% faster trigger for scale-out events and a 72% reduction in the total time required to provision new tasks, underscoring AWS’s commitment to optimizing performance and efficiency for containerized workloads.
Unpacking the Enhancement: A Deeper Dive into High-Resolution Metrics
The core of this acceleration lies in the shift from standard 60-second metric resolution to a finer-grained 20-second interval for Amazon CloudWatch metrics, which serve as the data backbone for ECS auto scaling. Previously, ECS auto scaling policies, whether predictive, scheduled, or target tracking, relied on metrics sampled every minute. While effective for gradual changes, this interval could introduce latency in responding to sudden spikes in traffic or resource utilization, potentially leading to temporary performance degradation or over-provisioning.
With the new 20-second resolution, CloudWatch now captures and publishes data points three times more frequently. This granular data provides the ECS auto scaling engine with a much clearer, real-time picture of an application’s resource consumption and demand patterns. The system can now detect deviations from desired targets or predict upcoming surges with greater precision and immediacy. This improvement is particularly critical for applications characterized by highly volatile workloads, such as e-commerce platforms during flash sales, live streaming events, gaming services, or real-time data processing pipelines where every second of latency can impact user experience and business outcomes.
Performance Benchmarks and Real-World Impact
AWS’s internal benchmarking tests vividly illustrate the impact of this enhancement. The time taken for a scale-out event to be triggered – the crucial initial response to increased load – improved from an average of 363 seconds (over six minutes) to a mere 86 seconds (under a minute and a half). This represents a remarkable 4.2x speed increase, or 76% faster reaction time. Furthermore, the total time required for the entire scaling process, from trigger detection to the successful provisioning and readiness of new tasks, saw an improvement from 386 seconds to 109 seconds. This 3.5x acceleration, or 72% faster turnaround, means applications can absorb sudden surges in demand much more gracefully, maintaining optimal performance and availability.
These numbers are not merely technical statistics; they translate directly into tangible business benefits. For an e-commerce site experiencing a viral product launch, faster scaling means fewer abandoned shopping carts due to slow page loads. For a media streaming service, it ensures uninterrupted playback quality during peak viewership. For a SaaS provider, it guarantees consistent application responsiveness, crucial for customer satisfaction and service level agreements (SLAs). The ability to scale out rapidly minimizes the duration of any potential resource contention, enhancing the overall resilience and elasticity of containerized applications running on ECS.
The Broader Context of Amazon ECS and Auto Scaling
Amazon ECS stands as a fully managed container orchestration service, enabling customers to run Docker containers on AWS without the complexity of managing the underlying control plane. It integrates seamlessly with other AWS services like Amazon EC2, AWS Fargate (a serverless compute engine for containers), and Amazon CloudWatch. The power of ECS lies in its ability to abstract away infrastructure management, allowing developers to focus on building and deploying applications.
Auto scaling, a fundamental pillar of cloud computing, is critical for achieving both cost efficiency and high availability. Traditional on-premises deployments often involved significant over-provisioning to handle peak loads, leading to wasted resources during off-peak times. Cloud auto scaling mechanisms, pioneered by services like AWS, dynamically adjust compute capacity based on actual demand. ECS service auto scaling extends this principle to containerized workloads, ensuring that the number of running tasks aligns perfectly with the current operational requirements.
Before this update, ECS auto scaling offered various policies:

- Predictive Scaling: Utilizes machine learning to forecast future traffic patterns and provision capacity proactively. Ideal for recurring, predictable loads.
- Scheduled Scaling: Allows users to define specific times for scaling events, useful for planned promotional events or known batch processes.
- Target Tracking Scaling: The most common reactive scaling method, it dynamically adjusts task counts to maintain a specified target value for a chosen metric (e.g., average CPU utilization, request count per target).
The new high-resolution metrics primarily enhance the responsiveness of target tracking and, by extension, the accuracy of predictive scaling, allowing for more precise and timely adjustments across the board. This evolution signifies AWS’s continuous effort to refine its core services, making them more adaptive and efficient for the dynamic demands of modern cloud-native applications.
Mechanics of Implementation: How Developers Can Leverage the New Feature
Adopting faster service auto scaling with high-resolution metrics is a straightforward process for ECS users. It is applicable across all ECS compute options: AWS Fargate, ECS Managed Instances, and Amazon Elastic Compute Cloud (EC2).
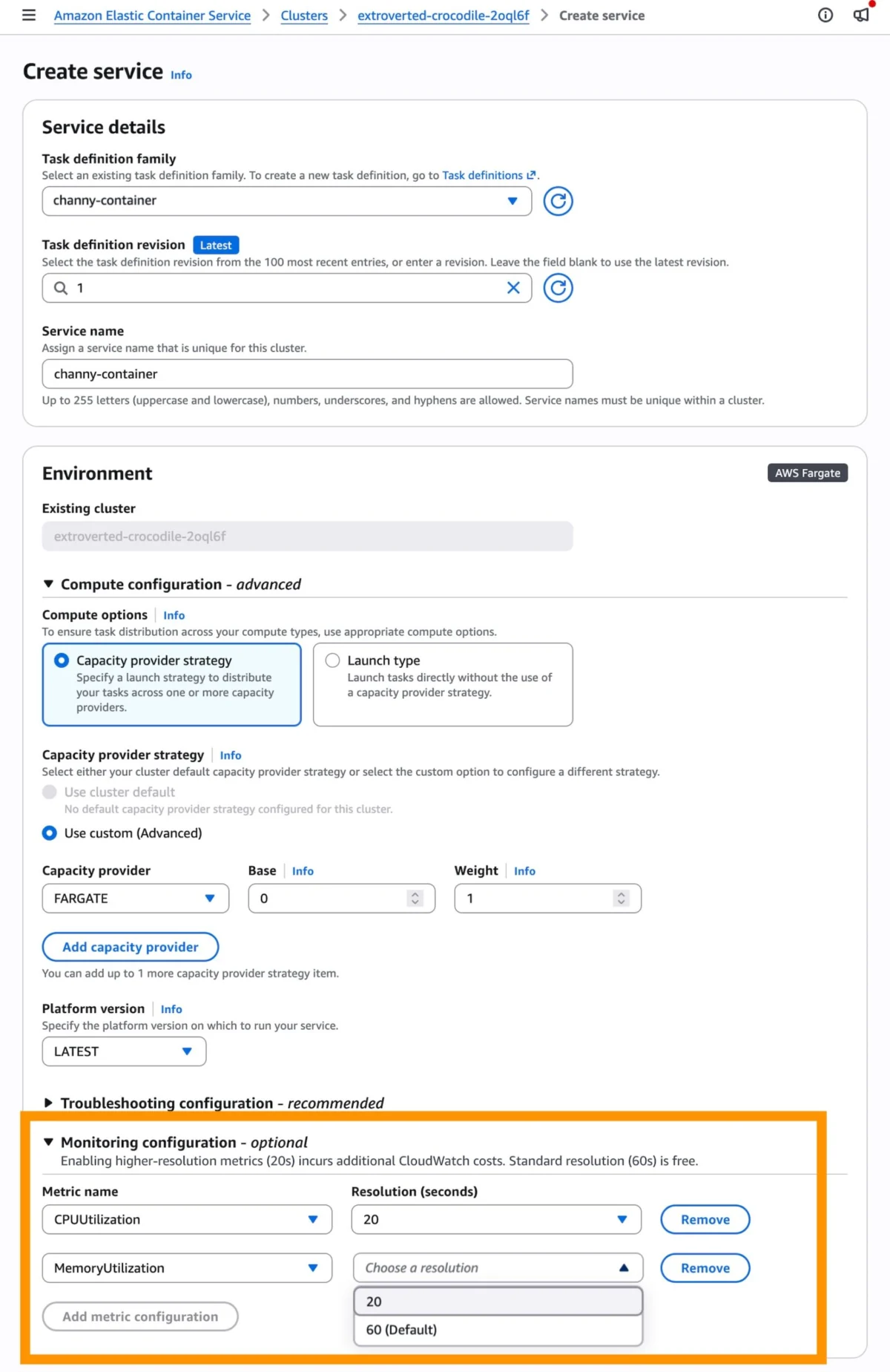
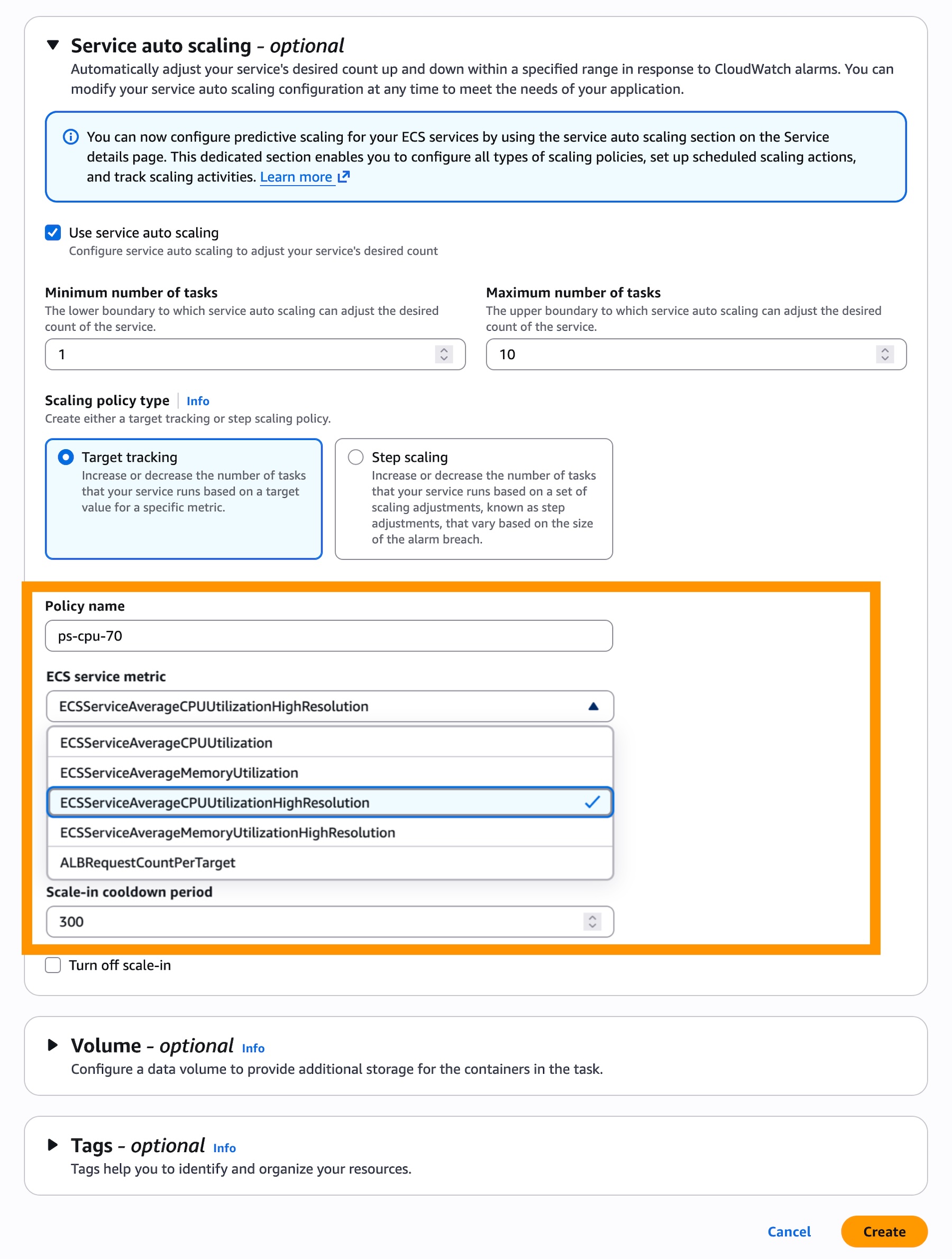
For new ECS services, developers can enable high-resolution metrics directly during the service creation workflow within the Amazon ECS console. In the "Monitoring configuration" section, users will find the option to add 20-second resolution metrics. Once these metrics are enabled, the next step involves configuring a target tracking scaling policy. Within the "Service auto scaling" section, after selecting "Use service auto scaling" and "Target Tracking" as the policy type, new high-resolution metrics such as ECSServiceAverageCPUUtilizationHighResolution or ECSServiceAverageMemoryUtilizationHighResolution become available for selection.
For existing ECS services, the update process is equally streamlined. Users first navigate to the "Update Service" option for their desired service to configure high-resolution metrics. After this deployment completes and the service begins generating the more granular data, developers can then proceed to the "Service and auto scaling" tab from their service details. Here, they can update their existing scaling policies to utilize the newly available higher-resolution metrics. This ensures a seamless transition without disrupting ongoing operations.
Beyond the console, AWS provides comprehensive support for programmatic configuration. Developers can leverage AWS SDKs and tools, the AWS Command Line Interface (AWS CLI), and AWS CloudFormation to automate the enablement of high-resolution metrics and the configuration of scaling policies. This flexibility caters to diverse development workflows and infrastructure-as-code practices.
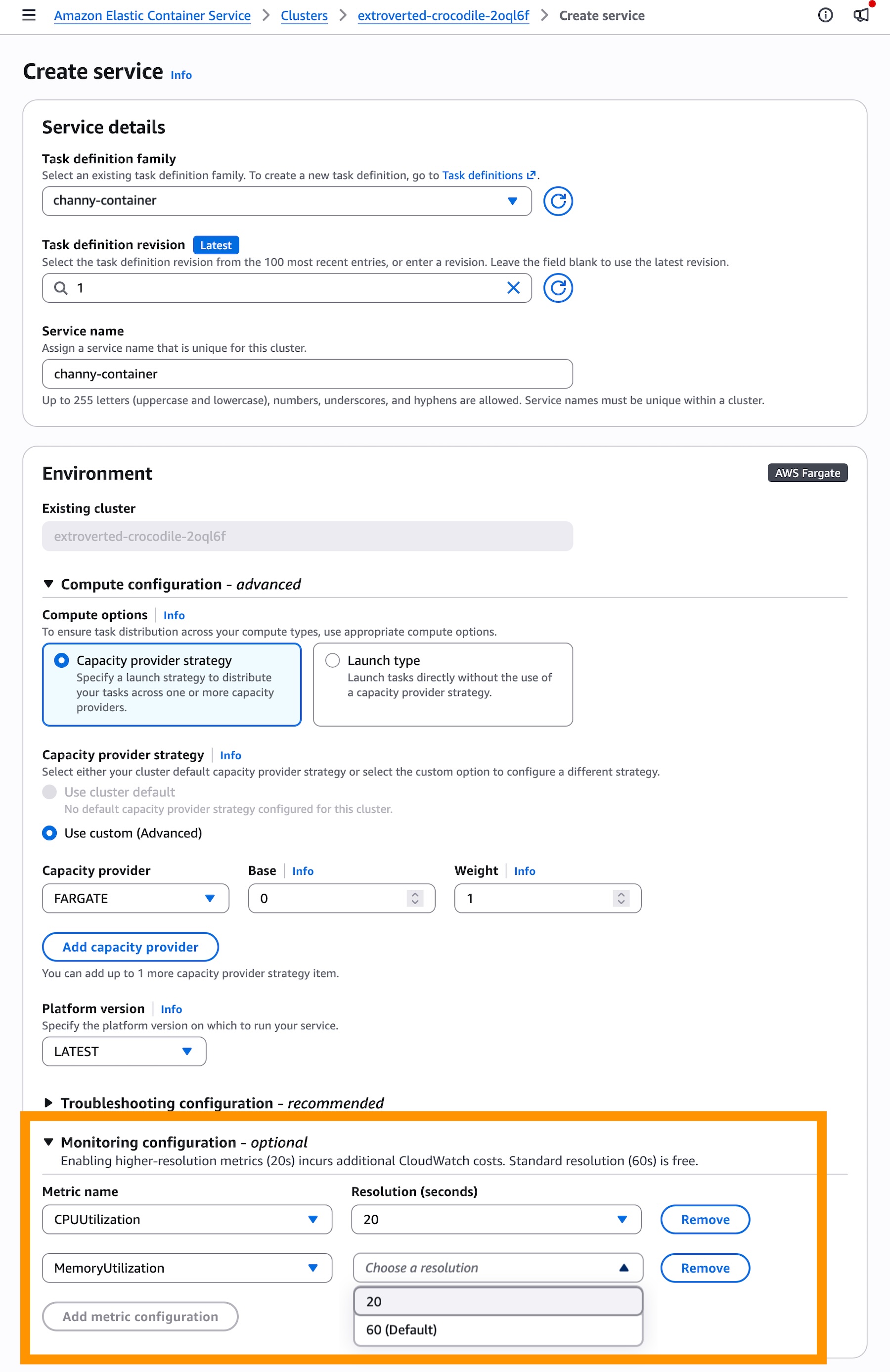
It is important for users to note the financial implications. While the faster service auto scaling feature itself incurs no additional cost, the high-resolution CloudWatch metrics introduce a new pricing dimension. Standard resolution (60-second) metrics remain free, but the more frequent 20-second data points will incur additional CloudWatch costs, detailed on the AWS CloudWatch pricing page. This cost is typically justified by the improved performance, enhanced user experience, and potentially optimized resource utilization that comes with more precise scaling.
Strategic Implications for Cloud-Native Architectures
This enhancement carries significant strategic implications for organizations building and operating cloud-native applications.
- Improved User Experience: For customer-facing applications, faster scaling directly translates to reduced latency and higher availability, leading to greater customer satisfaction and retention.
- Cost Optimization: While high-resolution metrics have a cost, the ability to scale precisely and rapidly can prevent costly over-provisioning. Applications can run leaner, scaling up only when absolutely necessary and scaling down quickly when demand subsides, leading to more efficient resource utilization over time.
- Enhanced Resilience: The ability to react swiftly to unforeseen traffic spikes or resource contention scenarios significantly bolsters the resilience of applications, making them more robust against sudden demand fluctuations or even potential distributed denial-of-service (DDoS) attacks.
- Broader Industry Applicability: Industries with inherently bursty workloads, such as media and entertainment (live events), financial services (trading platforms), gaming, and IoT data processing, stand to benefit immensely from this capability. It enables them to deliver consistent performance even under extreme load variations.
- Competitive Edge: For businesses relying on rapid innovation and responsiveness, this feature provides a competitive advantage, allowing them to deliver superior application performance and reliability compared to solutions with slower scaling mechanisms.
- Enabling New Use Cases: The increased responsiveness might unlock new use cases for ECS where ultra-low latency scaling was previously a bottleneck, such as certain real-time analytics or machine learning inference workloads.
Statements from AWS
While specific quotes were not provided in the original article, the release of this feature aligns with AWS’s long-standing philosophy of continuous innovation and customer-centric development. An AWS spokesperson, if asked, would likely emphasize the company’s commitment to empowering customers with the tools needed to build highly performant, resilient, and cost-effective applications. They would highlight how this update directly addresses the evolving needs of modern cloud-native workloads, where agility and responsiveness are paramount. The focus on delivering tangible performance improvements, backed by clear benchmark data, underscores AWS’s dedication to operational excellence and providing measurable value to its extensive customer base. The inferred message is clear: AWS is constantly listening to customer feedback and investing in enhancements that directly impact the efficiency and reliability of their cloud infrastructure.
The Evolving Landscape of Container Orchestration
The container orchestration landscape is dynamic and highly competitive, with services like Kubernetes (managed by various cloud providers, including AWS EKS) and AWS ECS constantly evolving. Updates like this one demonstrate AWS’s continued investment in ECS, reinforcing its position as a strong contender for containerized workloads, particularly for users seeking a fully managed experience with deep integration into the broader AWS ecosystem. The trend towards finer-grained control and faster reaction times in auto scaling is not unique to ECS but is a general direction across the cloud industry, reflecting the increasing demand for hyper-elastic and efficient infrastructure. This update ensures that ECS remains at the forefront of this evolution, offering capabilities that are critical for the next generation of scalable applications.
Conclusion and Availability
The faster service auto scaling with high-resolution metrics for Amazon ECS is available immediately across all AWS regions where ECS is offered. This enhancement provides a robust solution for developers and organizations seeking to build highly responsive, resilient, and cost-effective containerized applications. AWS encourages users to explore the new capabilities and provide feedback through AWS re:Post for ECS or their usual AWS Support channels, ensuring a continuous cycle of improvement based on real-world usage. This release marks another significant step in AWS’s ongoing mission to provide cutting-edge cloud infrastructure that adapts seamlessly to the ever-changing demands of the digital world.
