How to Build a Local, Privacy-First Tool-Calling Agent Using the Gemma 4 Model Family and Ollama
Amir Mahmud,
The landscape of artificial intelligence is undergoing a significant transformation, marked by a growing emphasis on local, privacy-centric deployments of advanced language models. A recent development poised to accelerate this shift is the successful implementation of a local, privacy-first tool-calling agent, leveraging the capabilities of Google’s Gemma 4 model family in conjunction with the Ollama inference runner. This innovative approach empowers machine learning practitioners and developers to build sophisticated AI systems that can interact with the real world through external tools, all while maintaining complete control over their data and infrastructure, operating entirely offline.
The Dawn of Agentic AI: A Paradigm Shift with Gemma 4
The open-weights model ecosystem experienced a pivotal moment with the recent unveiling of the Gemma 4 model family by Google. Designed with a clear intention to democratize access to cutting-edge AI, Gemma 4 variants offer "frontier-level capabilities" under a permissive Apache 2.0 license. This licensing choice is critical, as it grants developers unparalleled control over their AI infrastructure and ensures robust data privacy, addressing a primary concern in an era dominated by cloud-based AI services.
The Gemma 4 release is notable for its diverse range of models, catering to various computational needs and use cases. This includes the parameter-dense 31B model, offering extensive reasoning capabilities, and the structurally complex 26B Mixture of Experts (MoE) variant, optimized for efficiency and specialized tasks. Crucially, the family also features lightweight, edge-focused variants, extending advanced AI functionalities to devices with limited resources.
For AI engineers, a standout feature of the Gemma 4 family is its native support for agentic workflows. These models have been meticulously fine-tuned to reliably generate structured JSON outputs and natively invoke function calls based on system instructions. This refinement transcends the limitations of earlier language models, which often relied on "fingers crossed" reasoning, where the model might attempt to generate responses without external verification. Instead, Gemma 4 models can now act as practical systems, capable of executing workflows and conversing with external APIs locally, fundamentally changing how developers can integrate AI into applications. This capability transforms them from mere conversationalists into proactive agents that can fetch information, perform calculations, or trigger actions in the real world.
Democratizing AI: The Role of Ollama and Edge Computing
To achieve a genuinely local, privacy-first tool-calling system, the choice of inference runner is as crucial as the language model itself. This project utilizes Ollama as the local inference runner, seamlessly paired with the gemma4:e2b (Edge 2 billion parameter) model. Ollama has rapidly gained traction within the AI community for its ease of use, enabling developers to run large language models on their local machines with minimal setup. Its open-source nature and active community contribute to its growing adoption as a preferred platform for local AI experimentation and deployment.
The gemma4:e2b model is a testament to the advancements in efficient AI design. Specifically engineered for mobile devices and Internet of Things (IoT) applications, it represents a significant paradigm shift in what is achievable on consumer-grade hardware. During inference, this model activates an effective 2 billion parameter footprint, a remarkable optimization that preserves system memory while delivering near-zero latency execution. This efficiency is critical for responsive applications and user experiences, especially in environments where network latency is a concern or connectivity is intermittent.
Beyond performance, the gemma4:e2b model’s ability to execute entirely offline offers substantial benefits. It eliminates reliance on external servers, thereby removing rate limits and API costs that often plague cloud-based solutions. More importantly, it ensures strict data privacy, as all processing occurs locally, and sensitive user data never leaves the device. This inherent privacy is a major draw for applications in healthcare, finance, or any domain where data confidentiality is paramount.
Despite its incredibly compact size, Google’s engineering has ensured that gemma4:e2b inherits the multimodal properties and native function-calling capabilities of its larger sibling, the 31B model. This makes it an ideal foundation for building fast, responsive desktop agents without demanding high-end GPUs, thus lowering the barrier to entry for developers and researchers. Its robust performance at such a small scale underscores the ongoing trend of making powerful AI more accessible and ubiquitous.
Understanding Tool Calling: Bridging the LLM-World Gap
The concept of tool calling, also known as function calling, represents a fundamental architectural shift that addresses a critical limitation of early language models. Initially, LLMs were largely confined to being "closed-loop conversationalists." If a user inquired about real-world sensor readings, live market rates, or current weather conditions, the model could, at best, apologize for its inability to access such data or, at worst, fabricate an answer (a phenomenon known as hallucination). This intrinsic disconnect from real-time, external information severely limited their practical utility.
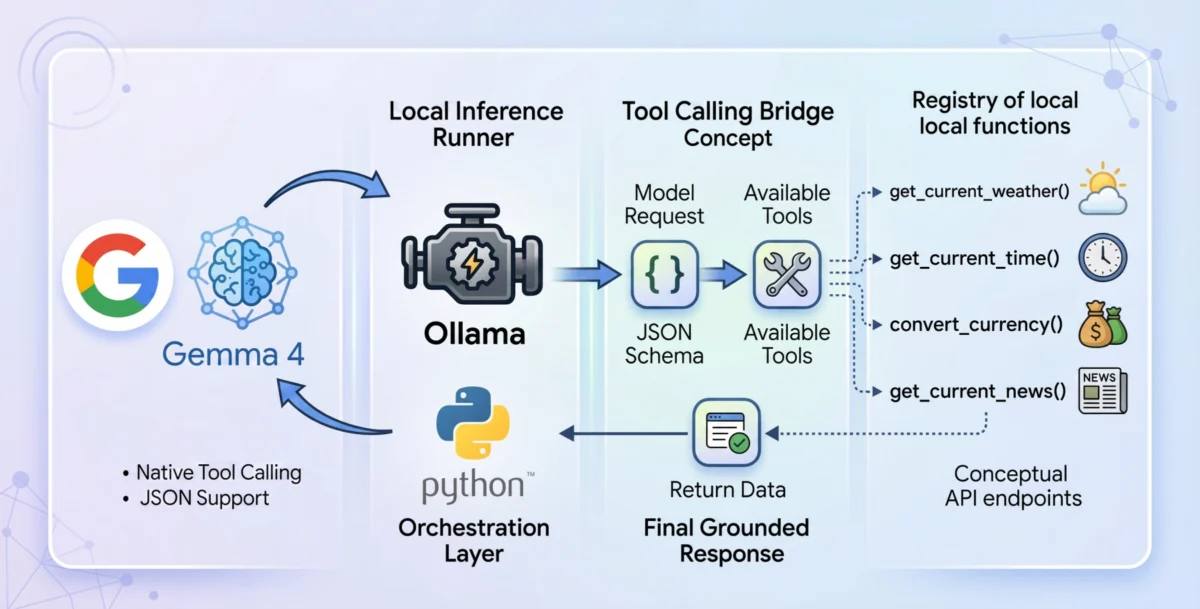
Tool calling serves as the essential bridge that transforms static, knowledge-bound models into dynamic, autonomous agents capable of interacting with the external world. When this capability is activated, the language model doesn’t attempt to guess the answer from its internal training data. Instead, it evaluates a user’s prompt against a predefined registry of available programmatic tools, typically supplied via a JSON schema. This schema acts as a contract, detailing the function’s name, its purpose, and the parameters it expects.
Upon identifying a need to use an external tool, the model intelligently pauses its internal inference process. It then formats a structured request, specifically designed to trigger the appropriate external function, and awaits the result. This request adheres strictly to the JSON schema, ensuring proper data types and parameter requirements are met. Once the host application processes this request, executes the external function, and returns the result, that live context is injected back into the model’s ongoing conversational thread. The model then synthesizes this newly acquired, grounded information to formulate a precise and accurate final response, effectively eliminating hallucination and expanding its utility dramatically. This iterative process of calling, executing, and integrating external data is what makes agentic AI truly powerful.
Building the Agent: A Zero-Dependency Approach
The practical implementation of such an agent requires a robust yet flexible architectural foundation. For this particular project, a "zero-dependency philosophy" was adopted, leveraging only standard Python libraries such as urllib for handling URL requests and json for parsing data. This deliberate choice ensures maximum portability, transparency, and avoids the "bloat" often associated with complex third-party frameworks, making the agent easy to deploy and understand. The complete codebase for this tutorial is readily available for examination and use at the provided GitHub repository, fostering open collaboration and learning.
The architectural flow of the application operates on a clear, sequential logic:
User Query: The process begins when a user submits a query to the agent.
Initial Model Inference Request: The agent packages the user query along with the defined tools (as JSON schemas) and sends it to the local Gemma 4 model via Ollama.
Model Decision (Tool Call or Direct Response): The Gemma 4 model analyzes the query. It either directly generates a text response if no external information is needed, or it identifies the appropriate tool to call based on the query and outputs a structured JSON tool_call object.
Tool Execution: If a tool_call is indicated, the agent intercepts this, dynamically parses the function name and arguments, and executes the corresponding Python function (e.g., fetching weather data).
Result Injection: The output from the executed tool (e.g., current weather information) is then re-packaged and injected back into the conversation history as a "tool" message.
Second Model Inference Request: The entire updated conversation history, now including the tool’s result, is sent back to the Gemma 4 model.
Final Response Generation: The model, with the new context from the tool, synthesizes a final, grounded natural language response to the user.
Constructing the Tools: The get_current_weather Function
Let’s delve into the construction of a foundational tool, get_current_weather, which demonstrates the agent’s capability to interact with external APIs. This Python function is designed to query the open-source Open-Meteo API to retrieve real-time weather data for a specified location.
def get_current_weather(city: str, unit: str = "celsius") -> str:
"""Gets the current temperature for a given city using open-meteo API."""
try:
# Geocode the city to get latitude and longitude
geo_url = f"https://geocoding-api.open-meteo.com/v1/search?name=urllib.parse.quote(city)&count=1"
geo_req = urllib.request.Request(geo_url, headers='User-Agent': 'Gemma4ToolCalling/1.0')
with urllib.request.urlopen(geo_req) as response:
geo_data = json.loads(response.read().decode('utf-8'))
if "results" not in geo_data or not geo_data["results"]:
return f"Could not find coordinates for city: city."
location = geo_data["results"][0]
lat = location["latitude"]
lon = location["longitude"]
country = location.get("country", "")
# Fetch the weather
temp_unit = "fahrenheit" if unit.lower() == "fahrenheit" else "celsius"
weather_url = f"https://api.open-meteo.com/v1/forecast?latitude=lat&longitude=lon¤t=temperature_2m,wind_speed_10m&temperature_unit=temp_unit"
weather_req = urllib.request.Request(weather_url, headers='User-Agent': 'Gemma4ToolCalling/1.0')
with urllib.request.urlopen(weather_req) as response:
weather_data = json.loads(response.read().decode('utf-8'))
if "current" in weather_data:
current = weather_data["current"]
temp = current["temperature_2m"]
wind = current["wind_speed_10m"]
temp_unit_str = weather_data["current_units"]["temperature_2m"]
wind_unit_str = weather_data["current_units"]["wind_speed_10m"]
return f"The current weather in city.title() (country) is temptemp_unit_str with wind speeds of windwind_unit_str."
else:
return f"Weather data for city is unavailable from the API."
except Exception as e:
return f"Error fetching weather for city: e"
This function employs a sophisticated two-stage API resolution pattern. Recognizing that many standard weather APIs require precise geographical coordinates, the function first transparently intercepts the city string provided by the model. It then performs a geocoding lookup using the Open-Meteo geocoding API to translate the city name into latitude and longitude coordinates. Once these coordinates are obtained and formatted, the function invokes the main weather forecast endpoint, using the derived coordinates to fetch the current temperature and wind speed. Finally, it constructs a concise, natural language string representing the telemetry point, which is then returned to the agent.
However, writing the Python function is only half the process. The language model itself needs to be explicitly informed about this tool’s existence and its operational parameters. This is achieved by mapping the Python function into an Ollama-compliant JSON schema dictionary:
"type": "function",
"function":
"name": "get_current_weather",
"description": "Gets the current temperature for a given city.",
"parameters":
"type": "object",
"properties":
"city":
"type": "string",
"description": "The city name, e.g. Tokyo"
,
"unit":
"type": "string",
"enum": ["celsius", "fahrenheit"]
,
"required": ["city"]
This rigid structural blueprint is absolutely critical for the agent’s reliable operation. It explicitly details variable expectations, strict string enums (like "celsius" or "fahrenheit" for the unit parameter), and required parameters. This precise definition guides the gemma4:e2b model’s weights to reliably generate syntax-perfect function calls, minimizing errors and ensuring consistent performance. Without this schema, the model would struggle to correctly format the arguments needed for the external function.
Tool Calling Under the Hood: Orchestration and Execution
The core of the autonomous workflow resides within the main loop orchestrator. Once a user initiates a prompt, the system establishes the initial JSON payload for the Ollama API. This payload explicitly specifies gemma4:e2b as the target model and crucially appends a global array containing all the parsed toolkit definitions (the JSON schemas).
# Initial payload to the model
messages = ["role": "user", "content": user_query]
payload =
"model": "gemma4:e2b",
"messages": messages,
"tools": available_tools, # available_tools contains the JSON schemas
"stream": False
try:
response_data = call_ollama(payload)
except Exception as e:
print(f"Error calling Ollama API: e")
return
message = response_data.get("message", )
Upon receiving the initial web request response from Ollama, a critical step is to carefully evaluate the architecture of the returned message block. The system does not blindly assume that text will be present. Instead, the model, being aware of the active tools, signals its desired outcome by attaching a tool_calls dictionary if it intends to invoke an external function.
If tool_calls are present within the message, the standard synthesis workflow is paused. The system then parses the requested function name and its corresponding arguments (kwargs) dynamically from the dictionary block. It proceeds to execute the appropriate Python tool using these parsed arguments. The live data returned by the tool’s execution is then meticulously injected back into the conversational array, appended as a message with the "tool" role.
# Check if the model decided to call tools
if "tool_calls" in message and message["tool_calls"]:
# Add the model's tool calls to the chat history
messages.append(message)
# Execute each tool call
num_tools = len(message["tool_calls"])
for i, tool_call in enumerate(message["tool_calls"]):
function_name = tool_call["function"]["name"]
arguments = tool_call["function"]["arguments"]
if function_name in TOOL_FUNCTIONS: # TOOL_FUNCTIONS is a mapping of names to Python functions
func = TOOL_FUNCTIONS[function_name]
try:
# Execute the underlying Python function
result = func(**arguments)
# Add the tool response to messages history
messages.append(
"role": "tool",
"content": str(result),
"name": function_name
)
except TypeError as e:
print(f"Error calling function: e")
else:
print(f"Unknown function: function_name")
# Send the tool results back to the model to get the final answer
payload["messages"] = messages
try:
final_response_data = call_ollama(payload)
print("[RESPONSE]")
print(final_response_data.get("message", ).get("content", "") + "n")
except Exception as e:
print(f"Error calling Ollama API for final response: e")
A particularly important secondary interaction occurs here: once the dynamic result from the tool is appended as a "tool" role message, the entire messages history is bundled up a second time and dispatched to the Ollama API again. This crucial second pass allows the gemma4:e2b reasoning engine to read and integrate the telemetry strings it previously initiated the request for. This iterative dialogue effectively bridges the final gap, enabling the model to logically process the external data and output a coherent, human-readable response, thereby completing the agentic workflow cycle. This two-step process—requesting tool use and then re-contextualizing the tool’s output—is fundamental to how these agents achieve grounded responses.
More Tools: Expanding the Tool Calling Capabilities
With the robust architectural foundation firmly established, expanding the agent’s capabilities becomes a straightforward modular process. Enriching its functionality requires nothing more than adding new Python functions that encapsulate specific real-world interactions and then defining their corresponding JSON schema representations. Using the identical methodology described above for get_current_weather, three additional live tools were incorporated, significantly broadening the agent’s utility:
convert_currency: This function accesses a real-time currency exchange API to provide accurate conversions between different global currencies. Its integration allows the agent to handle financial queries, such as calculating the value of a sum in a foreign currency, based on the latest market rates.
get_current_time: A simple yet effective tool that fetches the current time for any specified city or timezone. This enhances the agent’s ability to provide timely and geographically relevant information, useful for planning or general knowledge queries.
get_latest_news: This tool connects to a news API, enabling the agent to retrieve current headlines and summaries based on user-specified topics or locations. This capability transforms the agent into a dynamic news aggregator, providing up-to-the-minute information from various sources.
Each of these new capabilities is processed through the same JSON schema registry, ensuring that the gemma4:e2b model is fully aware of their existence, parameters, and expected outputs. This modularity allows for seamless expansion of the baseline model’s utility without demanding complex external orchestration or introducing heavy dependencies, adhering to the project’s zero-dependency philosophy. The ability to incrementally add tools makes this architecture highly scalable and adaptable to a wide array of future applications.
Rigorous Testing and Robust Performance
To validate the efficacy and reliability of the implemented tool-calling agent, a series of rigorous tests were conducted, starting with individual tool functionalities and progressing to complex, multi-tool queries. The consistency of the gemma4:e2b model’s reasoning engine, even at its optimized 2 billion parameter footprint, proved remarkable.
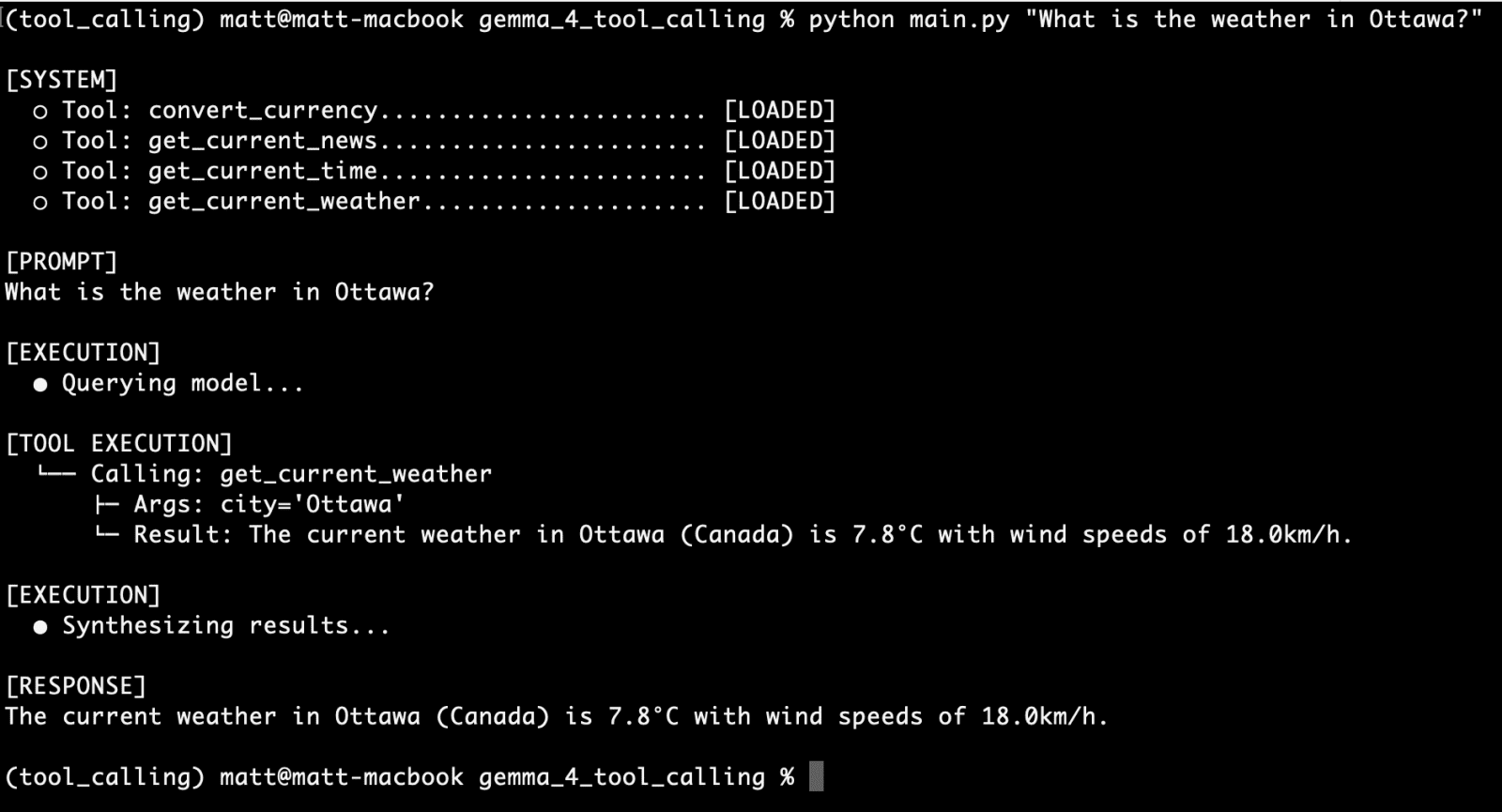
The initial test focused on the get_current_weather function with the query:
"What is the weather in Ottawa?"
The agent’s CLI UI successfully processed this, initiating the geocoding and weather API calls, and returning an accurate, current weather report for Ottawa. This successful first run confirmed the fundamental mechanism of tool identification, parameter extraction, external API interaction, and response synthesis.
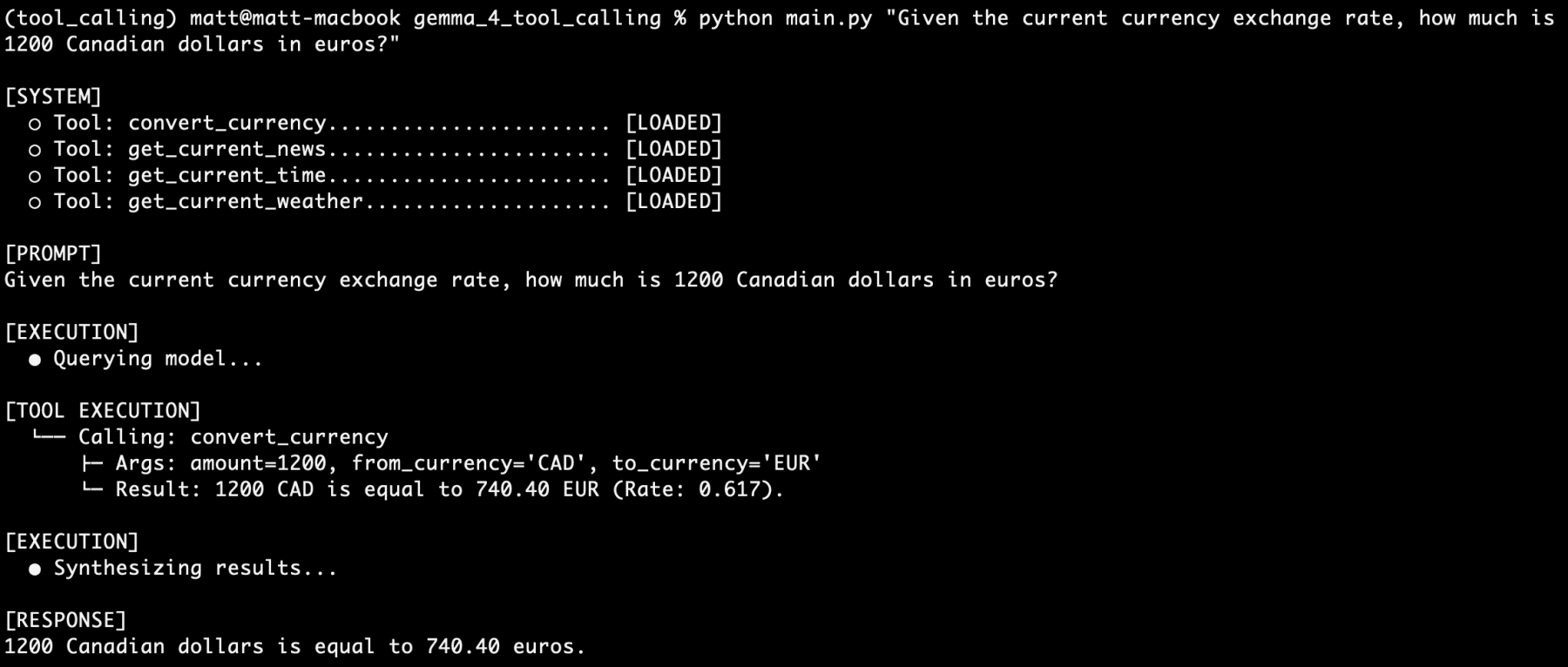
Next, the convert_currency tool was tested independently:
"Given the current currency exchange rate, how much is 1200 Canadian dollars in euros?"
Again, the agent flawlessly executed the convert_currency function, connecting to the real-time exchange rate API, performing the calculation, and presenting the converted amount in euros. This demonstrated the agent’s ability to handle numerical operations and integrate dynamic financial data.
The ultimate test involved stacking multiple tool-calling requests within a single, complex query, pushing the boundaries of the model’s agentic reasoning. It is crucial to remember that this entire operation was performed using a 4 billion parameter model with only half of its parameters actively engaged during inference, highlighting its exceptional efficiency. The query posed was:
"I am going to France next week. What is the current time in Paris? How many euros would 1500 Canadian dollars be? what is the current weather there? what is the latest news about Paris?"
The agent’s response was nothing short of impressive. It intelligently identified and executed four distinct functions—get_current_time, convert_currency, get_current_weather, and get_latest_news—all triggered by a single user prompt. Each function call was accurately parsed, executed, and its results were synthesized into a comprehensive and coherent response, providing:
The current time in Paris.
The converted value of 1500 Canadian dollars in euros.
The current weather conditions in Paris.
Recent news headlines related to Paris.
This multi-tool query served as a compelling demonstration of the gemma4:e2b model’s robust agentic capabilities. Over the course of a weekend, the system was subjected to hundreds of prompts, including various vague or slightly ambiguous wordings, yet the model’s reasoning consistently held strong, never failing to correctly identify and utilize the appropriate tools. This unwavering reliability, even with a relatively small model running locally, underscores the significant advancements in open-weight language model design and the effectiveness of the tool-calling architecture. The consistent performance observed paves the way for the development of even more complex and fully agentic systems in the near future.
Broader Implications and the Future of Local AI
The advent of native tool-calling behavior within open-weight models like Gemma 4, especially when paired with local inference solutions such as Ollama, marks one of the most practical and transformative developments in the realm of local AI to date. This convergence fundamentally alters the landscape for developers, businesses, and end-users, ushering in an era of unprecedented control and capability.
One of the most profound implications is the democratization of advanced AI. Previously, sophisticated AI agents capable of real-world interaction were largely confined to proprietary cloud services, incurring significant API costs and raising concerns about data ownership and privacy. With Gemma 4 and Ollama, developers can now operate securely offline, building complex systems unfettered by these cloud and API restrictions. This significantly lowers the barrier to entry, allowing smaller teams, individual developers, and academic researchers to experiment with and deploy cutting-edge AI without prohibitive expenses.
Enhanced data privacy and security are paramount benefits. By executing AI workloads entirely on local hardware, sensitive user data never leaves the device. This eliminates the risks associated with transmitting data to external servers and reduces the attack surface for potential breaches. For industries with stringent regulatory requirements, such as healthcare and finance, local AI agents offer a compliant and secure alternative to cloud-based solutions.
The development also heralds a new era for edge computing. Architecturally integrating direct access to the web, local file systems, raw data processing logic, and localized APIs means that even low-powered consumer devices can operate autonomously in ways previously restricted exclusively to cloud-tier hardware. Imagine smart home devices that can intelligently interact with their environment, personal assistants that can access and process personal data without sending it to the cloud, or industrial IoT sensors that can perform complex analyses at the source of data generation.
Furthermore, this capability fosters greater innovation and customization. With complete control over the model and its tools, developers can tailor AI agents precisely to their specific needs, integrating custom APIs and proprietary data sources without external limitations. This flexibility promotes the creation of highly specialized and efficient AI solutions for niche applications.
The observed reliability of Gemma 4 in consistently executing tool calls, even with vague prompts, suggests a future where AI agents are not just smart but also robust and dependable. This paves the way for the development of truly autonomous systems that can perform multi-step reasoning, self-correct, and proactively interact with their environment, moving beyond simple question-answering into complex problem-solving.
Conclusion
The successful implementation of a local, privacy-first tool-calling agent using Google’s Gemma 4 family and Ollama represents a monumental leap forward for accessible and ethical artificial intelligence. By seamlessly integrating the advanced reasoning capabilities of Gemma 4 with the flexibility of a local inference runner and a robust tool-calling architecture, developers can now construct sophisticated AI systems that are not only powerful but also private, cost-effective, and highly adaptable. This development signifies a tangible shift towards an AI ecosystem where innovation is driven by open-source collaboration and where the benefits of advanced AI are accessible to a broader audience, fostering a future of intelligent, secure, and user-centric applications across countless domains. The era of truly autonomous and localized AI agents is demonstrably here, promising a profound impact on how we interact with technology and the world around us.