
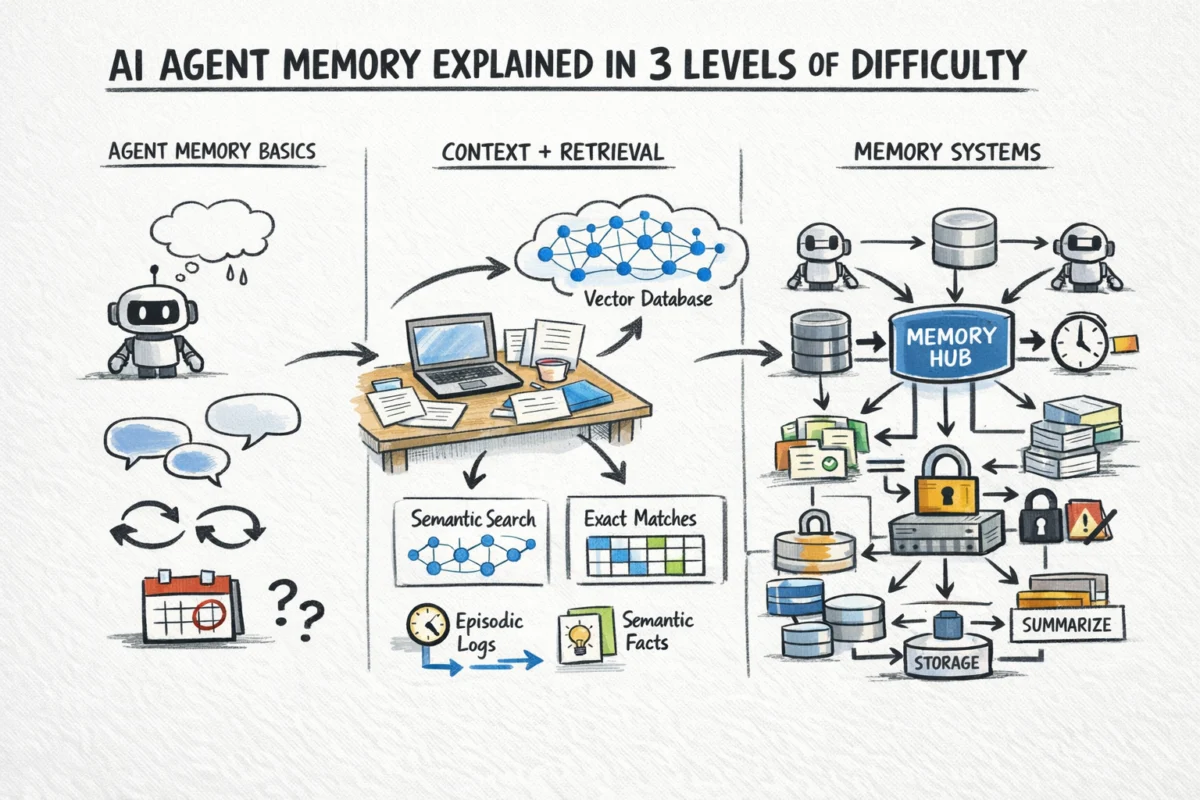
The advent of sophisticated AI agents, capable of navigating multi-step tasks and maintaining persistent interactions, hinges critically on their ability to remember and learn from past experiences. In this article, we delve into the intricate mechanisms governing AI agent memory, exploring how working memory, external memory, and scalable architectural patterns converge to build agents that not only improve over time but also offer unprecedented levels of personalization and consistency across diverse applications.
The Foundational Challenge: Bridging Statelessness with Persistence
At its core, the most significant hurdle in developing truly intelligent AI agents stems from the inherent statelessness of large language models (LLMs). A standard LLM API call operates as a discrete event: it receives a block of text, known as the context window, processes it, generates a response, and then discards all prior knowledge related to that specific interaction. There is no internal, persistent store updated between calls. This design, while efficient for isolated query-response tasks, becomes a fundamental impediment when an AI system is required to track decisions, recall user preferences, or seamlessly resume complex workflows across multiple sessions. The memory problem, therefore, is the engineering challenge of endowing an inherently stateless system with the capacity to behave as if it possesses persistent, queryable knowledge about its past interactions and learned facts.
The historical trajectory of AI reveals a progressive evolution in addressing this challenge. Early expert systems attempted to encode knowledge explicitly, a form of hard-coded "memory." The deep learning revolution, particularly with transformer architectures, shifted focus towards pattern recognition from vast datasets, but the stateless nature of inference remained. The recent surge in interest in "agentic AI," roughly beginning in 2022-2023, has intensified the need for robust memory solutions. These agents are designed to perform autonomous actions, plan, self-correct, and interact over extended periods, making memory not just a feature, but a prerequisite for their functionality. Without a robust memory system, an agent cannot learn from feedback, adapt its behavior, or provide a consistent, personalized user experience, relegating it to the status of a glorified chatbot.
The Hierarchical Memory Paradigm: Working, External, and Scalable Architectures
To overcome the stateless limitation, modern AI agents employ a hierarchical memory system that mirrors, in some ways, human cognitive processes. This paradigm is typically segmented into three levels: in-context or working memory, external memory, and scalable architectural patterns that manage the persistence, retrieval, and evolution of this knowledge. This multi-tiered approach allows agents to balance immediate, high-fidelity recall with long-term, scalable knowledge storage.
Working Memory: The Immediate Context
The simplest and most immediate form of memory for an AI agent is its in-context memory, often referred to as working memory. This encompasses everything currently present within the LLM’s context window during a given API call. It includes the ongoing conversation history, the system prompt defining the agent’s persona and rules, the results of any tool calls made during the current turn, and any relevant documents or snippets actively retrieved for the immediate step.
The primary advantage of in-context memory is its exactness and immediacy. The model can reason over any information within its context window with high fidelity, as it is directly available without any retrieval step or approximation. There’s no risk of pulling the wrong record because all relevant data for the current processing cycle is explicitly provided. However, this immediacy comes with significant constraints, primarily the context window size, which dictates the maximum amount of text an LLM can process in a single inference call. While cutting-edge models like OpenAI’s GPT-4 Turbo (128K tokens), Anthropic’s Claude 2.1 (200K tokens), and Google’s Gemini 1.5 Pro (up to 1 million tokens) offer increasingly expansive windows, costs and latency scale proportionally with the length of the input. Dumping everything into the context window is neither economically viable nor computationally efficient for sustained, complex interactions. Practically, in-context memory is best suited for maintaining the active state of a task: the current turn of a conversation, recently generated tool outputs, and documents directly pertinent to the immediate action or decision. It represents the agent’s fleeting "consciousness" for the present moment.
External Memory: Extending Reach and Recall
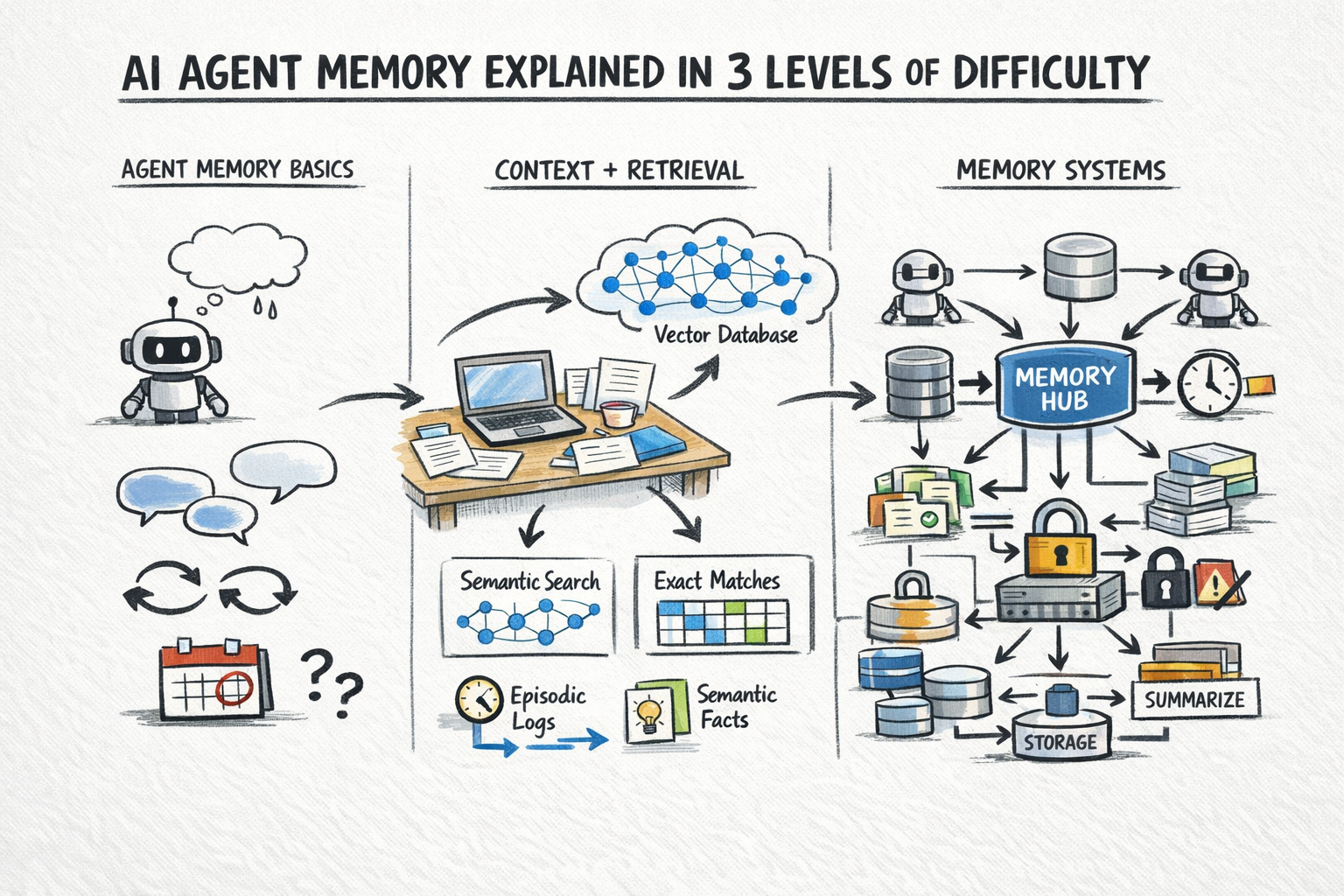
For information that is too voluminous, too old, or too dynamic to be continuously maintained within the limited context window, AI agents rely on external memory. This mechanism involves querying an external data store and retrieving only the information relevant to the current query or task, a process widely known as Retrieval-Augmented Generation (RAG). RAG effectively extends the agent’s "working memory" by injecting contextually relevant data into the LLM’s prompt.
External memory typically employs two distinct retrieval patterns to serve different needs:
-
Semantic Search: This pattern leverages vector databases (e.g., Pinecone, Weaviate, Milvus, ChromaDB) to find records that are semantically similar in meaning to the current query, rather than relying on exact keyword matches. Textual data (conversations, documents, observations) is converted into high-dimensional numerical vectors (embeddings), and similarity searches identify the most relevant pieces of information. This is invaluable for recalling past conversations, vague preferences, or general knowledge pertinent to the ongoing dialogue. Researchers at leading AI labs, including Google DeepMind and OpenAI, consistently emphasize that effective semantic search is the cornerstone for agents moving beyond mere conversational chatbots to truly autonomous systems capable of understanding nuanced human intent and recalling context from vast archives.
-
Exact Lookup: This pattern is used to retrieve structured facts by specific attributes from relational databases (e.g., PostgreSQL, MySQL) or key-value stores (e.g., Redis, DynamoDB). Examples include retrieving a user’s explicit preferences (e.g., "preferred language: English," "shipping address: 123 Main St"), the current state of a multi-step task (e.g., "order status: processing," "appointment scheduled: true"), prior decisions made by the agent, or specific entity records (e.g., product IDs, customer profiles). This provides precise, factual recall, essential for maintaining consistency and executing logic-driven tasks.
In practice, the most robust agent memory systems often combine both semantic search and exact lookup. An agent might first perform a semantic search to recall relevant past interactions or general user interests, then follow up with an exact lookup to retrieve specific user data or task states. The results from both queries are then merged and injected into the LLM’s context window, providing a rich, relevant, and comprehensive basis for the agent’s next action or response. This hybrid approach optimizes for both flexibility and precision, mitigating the "hallucination" risk often associated with LLMs by grounding their responses in factual, retrieved data.
The Architecture of Persistent Knowledge: Crafting Scalable Memory Systems
Beyond the immediate and retrievable, building truly intelligent and persistent AI agents requires a sophisticated architectural framework for memory management. This level addresses what types of information need to be stored, when and how to write to memory, efficient retrieval strategies, and mechanisms for memory decay, versioning, and multi-agent consistency.
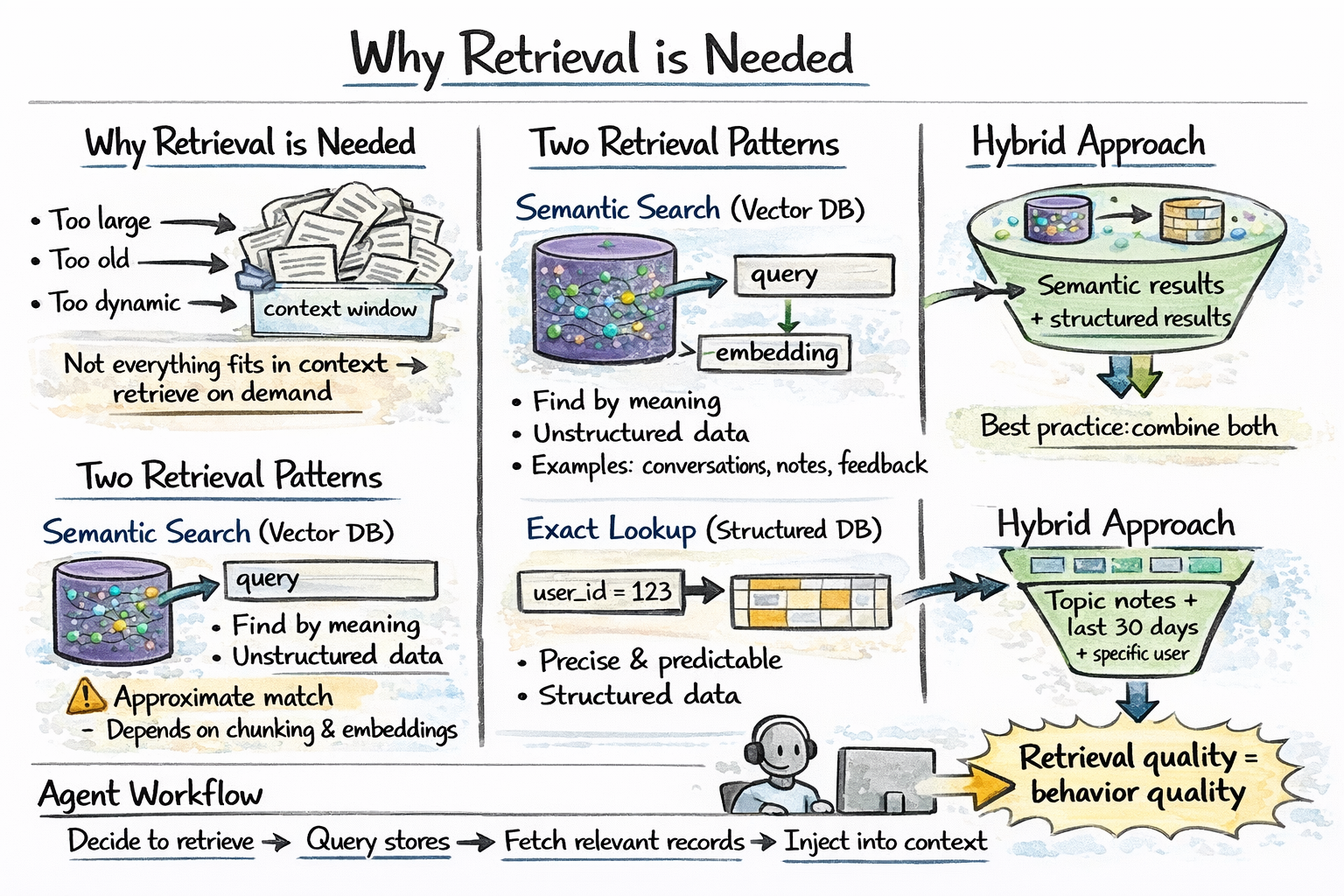
What Needs to Be Stored: The Tripartite Model
Inspired by human cognitive psychology, AI agent memory can be categorized into distinct types:
-
Episodic Memory: This captures specific events, experiences, tool calls, and their outcomes. It’s the "what happened" memory, recording instances like "User asked about product X on date Y, agent suggested Z," or "Agent called API A with parameters B and received response C." Episodic memory provides a detailed log of interactions, crucial for debugging, auditing, and learning from specific successes or failures.
-
Semantic Memory: This stores generalized facts, concepts, and preferences extracted from experience. It’s the "what is true" memory, encompassing knowledge like "User prefers dark mode," "The product X has feature A," or "Error code 404 means page not found." Semantic memory represents the agent’s accumulated knowledge base, enabling it to generalize from past interactions and apply learned facts to new situations.
-
Procedural Memory: This encodes learned action patterns, successful strategies, and known failure modes. It’s the "how to do things" memory. For instance, "When a user asks about product X, first check inventory, then suggest accessories." While often implicitly learned through reinforcement or fine-tuning, explicit representations of procedural memory can guide complex task execution and significantly improve an agent’s efficiency and reliability over time.
Memory Ingestion: When and What to Record
The efficiency and utility of an agent’s memory depend heavily on what information is recorded and when. Over-storing can lead to noise and increased costs, while under-storing can cripple the agent’s ability to learn and adapt.
-
End-of-Session Summarization: A common practice involves summarizing salient facts, decisions, and outcomes at the conclusion of each interaction session. An LLM, or a dedicated summarization module, can distill raw transcripts into compact, meaningful memory records, extracting entities, intentions, and key decisions. For example, a 20-minute customer service chat might be summarized into "User contacted about refund for order #12345, issue resolved by agent, refund processed."
-
Event-Triggered Writes: Certain critical events explicitly trigger memory writes. These include user corrections (e.g., "No, I meant X, not Y"), explicit preference statements (e.g., "I always prefer email updates"), task completions (marking a sub-task as done), and error conditions (recording a specific failure for future analysis). This ensures that vital, high-signal information is captured immediately.
-
What Not to Store: Crucially, it’s vital to avoid storing raw, verbose transcripts at scale, intermediate reasoning traces that do not impact future behavior, or redundant duplicates of existing records. This "data hygiene" is essential for managing storage costs, reducing retrieval latency, and maintaining the signal-to-noise ratio within the memory store.
Retrieval Strategies: Optimizing Recall
Effective memory is not just about storage but about intelligent retrieval. Getting the right context at the right time is paramount. Beyond basic semantic and exact lookups, advanced retrieval strategies include:
- Hybrid Retrieval: Combining keyword search (for precise entity matching) with semantic search (for conceptual relevance) often yields superior results.
- Query Expansion and Re-ranking: The initial user query can be expanded by the LLM into multiple related queries to cast a wider net. Retrieved results can then be re-ranked by another LLM based on their relevance to the expanded context.
- Contextual Filtering: Retrieved memories can be filtered based on additional metadata, such as recency, user ID, or task type, ensuring only the most pertinent information is presented.
Memory Decay and Versioning
To maintain relevance and prevent information overload, sophisticated memory systems incorporate mechanisms for decay and versioning:
-
Temporal Decay: Not all memories are equally important forever. Temporal decay assigns higher weight to recent memories, allowing older, less relevant information to naturally fade in importance. This can be implemented through weighting functions (e.g., exponentially decaying weights) or by periodically archiving/summarizing older memory segments. This mimics human forgetting, which is crucial for cognitive efficiency.
-
Versioned Entity Records: For structured facts like user preferences or task states, maintaining a versioned entity store is critical. When a user’s address changes, the new address overwrites the old one, but the system retains a timestamped history of changes. This ensures consistency, provides an audit trail, and allows agents to reason about the evolution of facts over time. For example, a customer support agent might need to know a user’s current email but also be able to access a previous one for historical context.
Multi-Agent Memory: The Challenge of Collaboration
As AI systems evolve towards multi-agent architectures, where multiple specialized agents collaborate on a single task, consistency in shared memory becomes a significant engineering challenge. If a coordinator agent and several sub-agents are working in parallel, ensuring they operate on the most up-to-date and consistent view of shared knowledge is paramount. Issues like race conditions, stale data, and conflicting information can arise. Solutions often involve centralized shared memory stores with robust concurrency control, or distributed ledger-like systems where memory updates are carefully synchronized. As highlighted by MongoDB’s technical blog, "Why Multi-Agent Systems Need Memory Engineering," the complexity scales rapidly, demanding dedicated architectural planning for shared knowledge bases and communication protocols.
Evaluation of Memory Systems
Measuring the effectiveness of an AI agent’s memory is complex but crucial. Key evaluation metrics include:
- Recall Accuracy: How often does the agent retrieve the correct and relevant information when needed?
- Relevance: Of the retrieved information, how much is actually useful and contributes to the task?
- Latency: How quickly can the agent access and integrate memory into its decision-making process?
- Cost Efficiency: The computational and storage costs associated with maintaining and querying memory.
- Consistency: For multi-agent systems, how well is shared knowledge synchronized across agents?
- User Satisfaction: Ultimately, does the memory system contribute to a more coherent, personalized, and effective user experience?
These metrics require careful definition and often involve a combination of automated testing, human evaluation, and A/B testing in live environments.
Implications and Future Outlook
The development of sophisticated memory systems for AI agents holds profound implications across various industries. In customer service, agents can provide hyper-personalized support, remembering past issues and preferences across interactions. In education, AI tutors can adapt learning paths based on a student’s long-term progress and areas of difficulty. In healthcare, diagnostic agents could recall patient histories and prior treatment outcomes. For software development, AI assistants could remember project specifications, code preferences, and debugging patterns over months.
However, the advancement of AI memory also introduces critical ethical considerations. Data privacy becomes paramount, as vast amounts of user interaction data are stored. Bias in the data used to train memory systems or in the summarization/retrieval algorithms could perpetuate and amplify harmful stereotypes. Robust security measures and transparent data governance policies are essential to prevent misuse and protect sensitive information.
Looking ahead, research will likely focus on more biologically inspired memory models, incorporating aspects like consolidation, episodic buffering, and associative recall with greater sophistication. The integration of neuro-symbolic AI approaches, which combine the pattern recognition power of neural networks with the structured reasoning of symbolic systems, could lead to agents with even more robust and interpretable memory capabilities. The "holy grail" remains the development of truly adaptive, self-improving agents that can autonomously manage their own knowledge, learn continuously from every interaction, and evolve their understanding of the world, moving closer to the vision of general artificial intelligence. The journey of building intelligent machines is, in essence, a journey of mastering memory.
