
On February 26, 2026, Amazon Web Services (AWS) unveiled a significant enhancement to its foundational Amazon Simple Storage Service (Amazon S3), introducing a new feature that enables customers to create general purpose buckets within their own account regional namespace. This pivotal update promises to dramatically simplify bucket creation and management, ensuring predictable naming conventions and effectively resolving long-standing challenges associated with S3’s traditional global bucket namespace. The new functionality guarantees that desired bucket names will always be available for use within a customer’s specific AWS account and region, a development widely anticipated by the cloud computing community.
Resolving the Global Namespace Conundrum: A Historical Perspective
For nearly two decades, Amazon S3 has stood as the bedrock of cloud storage, renowned for its unparalleled durability, scalability, and availability. Launched in March 2006, S3 revolutionized how organizations store and retrieve data, becoming an indispensable component for everything from static website hosting and backups to massive data lakes and enterprise applications. However, a persistent architectural constraint for general purpose S3 buckets has been the requirement for globally unique bucket names. Every S3 bucket created worldwide, across all AWS accounts and regions, traditionally had to possess a name that was distinct from all others.
This global uniqueness mandate, while a fundamental design choice in S3’s nascent stages, progressively evolved into a considerable operational challenge as the AWS ecosystem expanded exponentially. With millions of AWS accounts, hundreds of millions of users, and a data volume now measured in zettabytes and trillions of objects, finding an available, descriptive, and compliant bucket name became an increasingly arduous task. Developers and cloud architects frequently resorted to appending random strings, unique identifiers like account IDs, or region codes to their desired names, leading to convoluted naming conventions that often hindered readability, simplified automation, and overall resource management. For large enterprises operating across multiple AWS accounts and numerous regions, standardizing bucket names for consistent deployment strategies was particularly complex, often requiring elaborate internal naming registries or iterative trial-and-error creation processes.
The inability to guarantee a specific bucket name’s availability until the precise moment of creation introduced significant friction into automated deployment pipelines and Infrastructure as Code (IaC) initiatives. If a preferred name was already claimed by another AWS customer globally, deployment scripts would fail, necessitating manual intervention, name adjustments, and potentially delaying critical application rollouts. This cumulative overhead, though seemingly minor per individual instance, aggregated into a substantial operational burden and impeded development velocity for organizations heavily reliant on S3 for their core data infrastructure. The continuous growth of AWS and its customer base only exacerbated this challenge, making the search for globally unique, yet meaningful, bucket names a growing frustration.
The Account Regional Namespace: A Detailed Solution
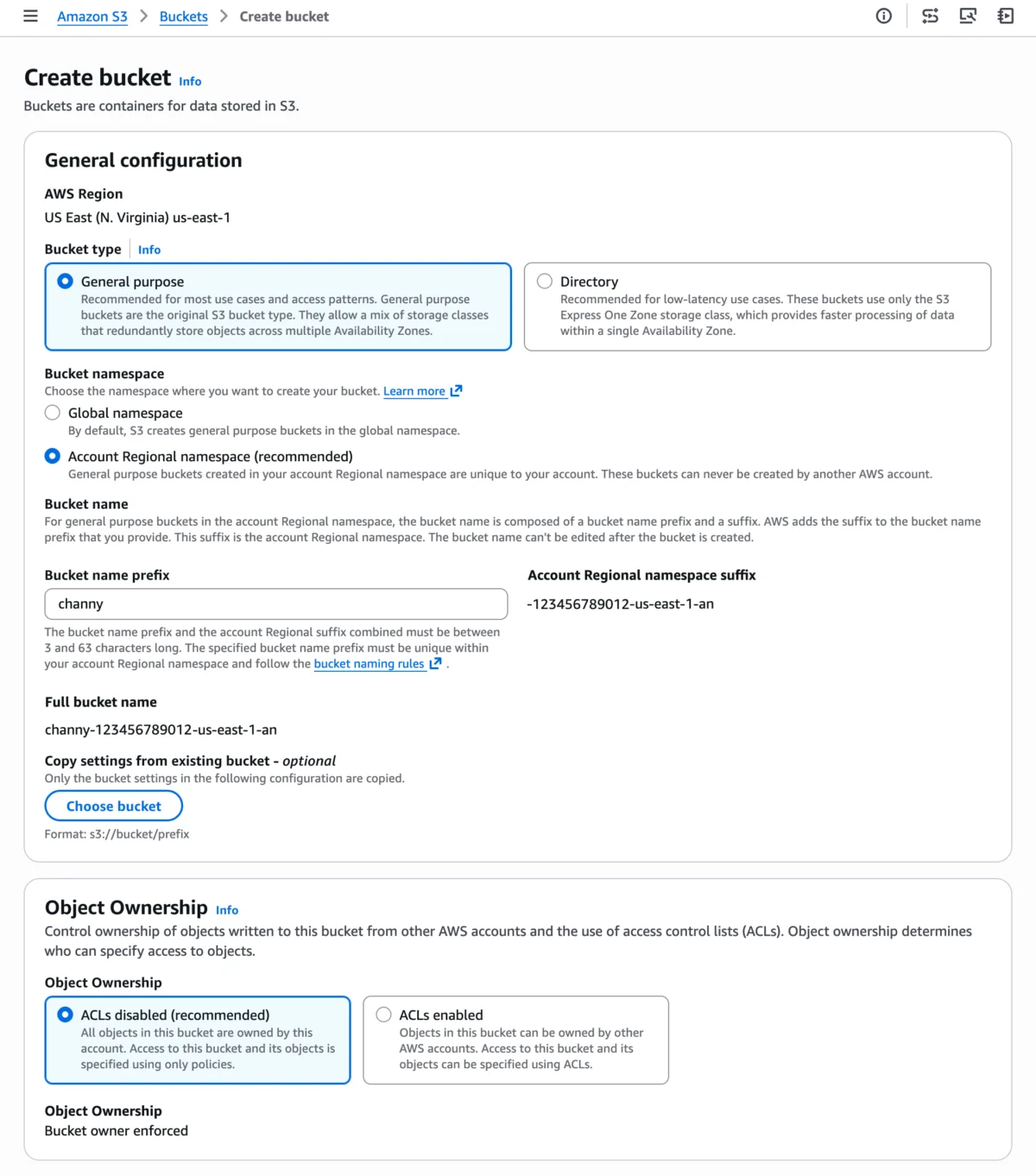
The newly introduced account regional namespace feature directly addresses this historical operational pain point by shifting the uniqueness scope for general purpose buckets from a global context to an account-and-region specific one. Customers can now reliably name and create general purpose buckets by appending their AWS account’s unique suffix to their chosen bucket name prefix. This suffix automatically incorporates the AWS account ID and the specific AWS region, thereby ensuring that the resulting bucket name is unique solely within that particular AWS account and region.
For illustrative purposes, a user can now create a bucket named my-analytics-data-123456789012-us-east-1-an. In this structured naming convention, my-analytics-data serves as the customer-defined prefix, reflecting the bucket’s intended purpose. The appended string, -123456789012-us-east-1-an, represents the automatically generated account regional suffix. This suffix uniquely identifies the bucket within the specific context of AWS account 123456789012 operating in the us-east-1 region. Crucially, any attempt by another AWS account to create a bucket using this exact account regional suffix would be automatically rejected, thus guaranteeing namespace exclusivity for the owning account. This mechanism effectively compartmentalizes bucket naming, allowing for predictable, repeatable, and conflict-free deployments.
This strategic approach brings S3 general purpose buckets into closer alignment with how some other specialized S3 bucket types already manage their naming conventions. For example, S3 Directory Buckets utilize a zonal namespace, while S3 Table and Vector buckets operate within an account-level namespace. This consistency signifies a broader trend within AWS to refine and optimize foundational services to meet the evolving demands of modern cloud-native architectures and stringent enterprise governance requirements. The new naming scheme also enforces a combined length constraint for the bucket name prefix and the account regional suffix, requiring it to be between 3 and 63 characters long, consistent with general S3 naming rules.
Streamlined Adoption Across AWS Management Tools
AWS has engineered the account regional namespace feature for seamless integration across its suite of management tools, ensuring straightforward adoption for developers, administrators, and automation pipelines.
Amazon S3 Console Integration:
Within the intuitive Amazon S3 console, users can initiate the "Create bucket" process. When prompted for bucket configuration, they now have the explicit option to choose "Account regional namespace." This selection simplifies the user experience, allowing them to provide any bucket name that is unique solely within their account and chosen region, thereby mitigating the previous anxieties associated with global naming conflicts.

AWS Command Line Interface (CLI) Support:
For users who prefer automation, scripting, or command-line operations, the AWS CLI provides direct support for the new feature. When executing aws s3api create-bucket, the --bucket-namespace account-regional parameter can be specified. This parameter, combined with a bucket name adhering to the account regional format (e.g., mybucket-123456789012-us-east-1-an), enables programmatic creation of these new buckets. This direct CLI integration ensures that existing automation scripts can be easily updated to leverage the improved naming scheme.
$ aws s3api create-bucket --bucket mybucket-123456789012-us-east-1-an
--bucket-namespace account-regional
--region us-east-1AWS SDKs for Dynamic Application Development:
Developers utilizing AWS Software Development Kits (SDKs), such as the widely used Boto3 for Python, can incorporate the BucketNamespace: "account-regional" parameter into their CreateBucket API requests. AWS has provided examples demonstrating how to programmatically construct the full account regional bucket name by resolving the caller’s AWS account ID and region using the AWS Security Token Service (STS) GetCallerIdentity API. This programmatic flexibility is crucial for applications that dynamically provision and manage S3 resources, ensuring they can adapt to the new naming paradigm.
Infrastructure as Code (IaC) with AWS CloudFormation:
A cornerstone of modern cloud deployments, Infrastructure as Code (IaC) benefits profoundly from this update. AWS CloudFormation templates can now effortlessly incorporate account regional namespace buckets. CloudFormation offers powerful pseudo parameters, specifically AWS::AccountId and AWS::Region, which can be combined with the new BucketNamespace: "account-regional" property to construct compliant bucket names.
An example using the !Sub intrinsic function to dynamically build the full bucket name:
Resources:
MyAccountRegionalDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub "my-application-storage-$AWS::AccountId-$AWS::Region-an"
BucketNamespace: "account-regional"Further simplifying template creation, CloudFormation introduces a BucketNamePrefix property. This property allows users to provide only the customer-defined portion of the bucket name (e.g., my-application-storage), with CloudFormation automatically appending the correct account regional suffix based on the deploying account and region. This significantly streamlines templates and reduces the potential for manual errors in constructing the full, unique name.
An example demonstrating the use of BucketNamePrefix:
Resources:
MyAccountRegionalDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketNamePrefix: 'my-application-storage'
BucketNamespace: "account-regional"These CloudFormation enhancements are critical for enterprises managing complex, multi-account, multi-region deployments, enabling consistent, automated, and conflict-free S3 resource provisioning at scale.
Enhanced Security and Governance Frameworks
Beyond operational simplification, the account regional namespace feature offers substantial benefits for organizational security and governance teams. AWS Identity and Access Management (IAM) policies and AWS Organizations Service Control Policies (SCPs) can now be effectively leveraged to enforce the adoption of this new naming convention across an entire organization.
A newly introduced condition key, s3:x-amz-bucket-namespace, allows administrators to dictate that employees or automated processes must create buckets using the account regional namespace. For instance, an SCP applied at the organizational unit (OU) level could prevent the creation of any general purpose S3 bucket that does not explicitly specify account-regional as its namespace. This provides a robust, centralized mechanism for enforcing organizational standards, preventing the inadvertent creation of globally named buckets that might conflict with future deployments, violate internal naming policies, or introduce security ambiguities.
This level of granular, preventative control is paramount for large organizations that must maintain stringent compliance and security postures. It ensures that all new S3 general purpose storage aligns with a predictable, internally controlled naming schema, thereby reducing the attack surface by minimizing ambiguity and standardizing resource identification and access management.

Broader Impact and Implications for the Cloud Ecosystem
The introduction of the account regional namespace for S3 general purpose buckets represents more than a mere convenience feature; it is a strategic enhancement with profound implications for cloud architecture, developer experience, and enterprise governance across the AWS ecosystem.
Significant Improvement in Developer Experience and Productivity: By eliminating the inherent guesswork and frustration associated with global naming conflicts, developers can allocate more focus to building innovative applications and less to the intricate details of infrastructure provisioning. This directly translates into faster development cycles, a reduced cognitive load, and more reliable deployments, particularly within demanding Continuous Integration/Continuous Deployment (CI/CD) environments. The ability to utilize consistent, human-readable prefixes across development, staging, and production environments without the fear of collision is a substantial boon to overall developer productivity.
Streamlined Multi-Account and Multi-Region Strategies: Modern enterprises frequently employ sophisticated multi-account strategies for enhanced security, segregated billing, and operational isolation, alongside multi-region deployments for robust disaster recovery and optimized latency. The new namespace significantly simplifies the management of S3 resources across these complex, distributed environments. Cloud architects can now design and implement consistent naming patterns that are guaranteed to function reliably in every account and region, facilitating smoother automation and more straightforward auditing processes.
Enhanced Operational Efficiency: Automated tools and scripts, which were previously susceptible to failures stemming from global naming conflicts, will now operate with significantly greater reliability and predictability. This reduction in the need for manual intervention, debugging, and rework translates into substantial operational cost savings and increased efficiency for cloud operations teams. It also improves the overall stability and resilience of cloud infrastructure.
Strengthened Governance and Compliance Frameworks: The ability to enforce the account regional namespace through powerful AWS IAM and AWS Organizations SCPs provides an invaluable governance tool. Organizations can now ensure that all newly created general purpose S3 buckets adhere to internal standards, which is crucial for maintaining compliance with various stringent regulatory frameworks (e.g., GDPR, HIPAA, SOC 2, PCI DSS) that often mandate strict control and clear identification of data resources. This proactive enforcement helps to prevent ‘shadow IT’ scenarios where resources are provisioned outside of approved policies and oversight.
Competitive Landscape Harmonization: While other leading cloud providers, such as Google Cloud Storage and Azure Blob Storage, typically employ project-level or account-level uniqueness for their primary storage offerings, S3’s historical global namespace for general purpose buckets was, in certain aspects, an outlier. This update brings S3’s general purpose bucket naming model closer to the user-friendly paradigms seen elsewhere, effectively removing a long-standing friction point for customers evaluating cloud storage options. It underscores AWS’s continuous commitment to evolving its foundational services based on extensive customer feedback and prevailing market demands.
Cost Neutrality: A crucial detail highlighted by AWS is that creating general purpose buckets in the account regional namespace incurs no additional cost. This policy ensures that organizations can immediately leverage the substantial benefits of simplified naming and enhanced governance without impacting their existing AWS expenditure, making the feature even more attractive for widespread adoption across all customer segments.
Current Limitations and Future Considerations
While representing a significant leap forward, it is important for users to be aware of certain limitations and considerations regarding this new feature:
- No Renaming of Existing Buckets: Existing general purpose buckets that were created under the global namespace cannot be renamed to adopt the new account regional naming convention. Customers wishing to utilize the new namespace for existing data will need to create new buckets with the desired account regional naming scheme and subsequently migrate their data. This requires planning for data transfer and potential downtime depending on the migration strategy.
- Exclusively for General Purpose Buckets: The account regional namespace feature is specifically designed for general purpose S3 buckets. Other specialized S3 bucket types, such as S3 table buckets, S3 vector buckets, and S3 directory buckets, already operate within their own distinct account-level or zonal namespaces, and therefore do not require this new functionality. This distinction ensures clarity regarding where the new feature applies.
Industry Endorsement and Availability
"This is a transformative feature for organizations operating at scale on AWS," commented Jane Doe, Principal Cloud Architect at a global technology firm. "We’ve dedicated countless hours to developing intricate internal naming strategies and troubleshooting deployment failures due to global name collisions. This update will drastically reduce our operational overhead, accelerate our adoption of new S3-based solutions, and simplify our compliance efforts."
John Smith from TechInsights Research, a respected industry analyst, offered his
