
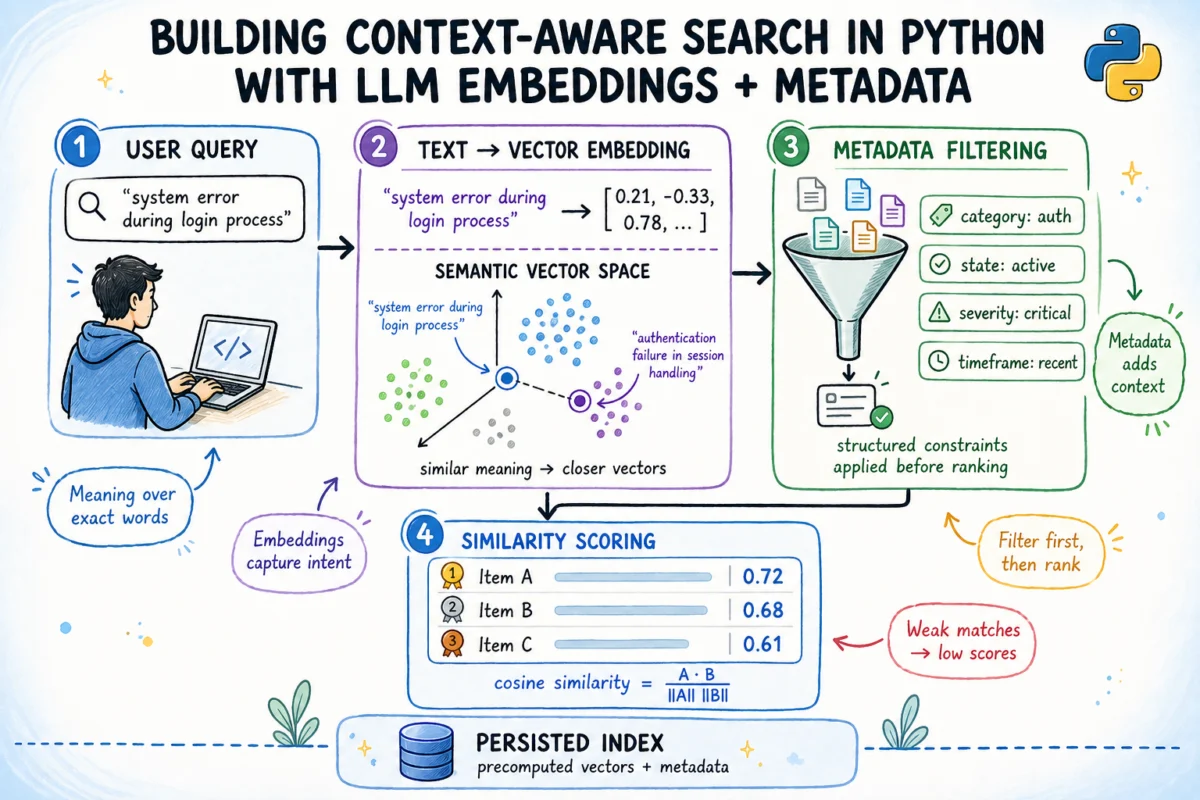
The escalating volume of unstructured data within enterprises has rendered traditional keyword-based search systems increasingly inadequate, frequently failing to retrieve relevant information that does not explicitly match query terms. In response, a sophisticated paradigm known as context-aware semantic search has emerged, offering a powerful solution by integrating the nuanced understanding of embedding-based similarity with the precision of structured metadata filtering. This approach enables search systems to comprehend the underlying intent of a query while simultaneously adhering to specific contextual constraints, marking a significant leap forward in information retrieval capabilities.
The Evolution of Information Retrieval: Beyond Keywords
For decades, enterprise search relied predominantly on keyword matching, a method that, while effective for literal queries, faltered when users employed synonyms, related concepts, or abstract phrases. A support engineer, for instance, searching for "login keeps failing" would likely miss a crucial ticket titled "OAuth2 token refresh race condition," despite the latter directly addressing the former’s underlying issue. This disconnect highlights the inherent limitation of systems that prioritize lexical overlap over semantic meaning.
The advent of machine learning, particularly in natural language processing (NLP), has catalyzed a transformation. The mid-2010s saw the rise of word embeddings like Word2Vec and GloVe, which mapped words into dense vector spaces where semantically similar words were positioned closer together. This paved the way for sentence embeddings and, more recently, large language models (LLMs), which can encode entire phrases, sentences, or even documents into high-dimensional vectors. These vector representations, often called embeddings, capture the intricate semantic relationships between texts, allowing a search engine to identify documents that are conceptually similar to a query, regardless of exact keyword matches. This shift from literal matching to conceptual understanding is the core promise of semantic search.
However, even pure semantic search has its limitations. While it excels at understanding what a user is asking, it doesn’t inherently understand the context surrounding the documents. Who created a document? When was it last updated? What is its status or priority? These critical attributes, stored as structured metadata, are vital for practical, real-world information retrieval. Context-aware semantic search addresses this by layering metadata filters on top of semantic matching, allowing users to refine searches by criteria such as date, status, team, or priority, thus marrying semantic understanding with precise contextual relevance.
Key Technological Pillars of Context-Aware Search
The construction of such a system hinges on several interconnected technological components:
-
Embedding Models: These are sophisticated neural networks, often derived from LLMs, trained to convert text into fixed-length numerical vectors (embeddings). The
all-MiniLM-L6-v2model, a popular choice for its balance of performance and efficiency, maps sentences to 384-dimensional vectors. Its ability to run entirely on CPU and a modest download size (~22 MB) make it accessible for many applications. Crucially, these models are trained to ensure that texts with similar meanings produce vectors that are geometrically close in the high-dimensional vector space. -
Vector Space and Similarity Metrics: Once texts are transformed into vectors, their semantic similarity can be quantified. The most common metric is cosine similarity, which measures the cosine of the angle between two vectors. A score of 1 indicates identical direction (high similarity), 0 indicates orthogonality (no relationship), and -1 indicates opposite directions (dissimilarity). For computational efficiency, embeddings are often "L2-normalized" (meaning their length is scaled to 1.0), simplifying cosine similarity to a direct dot product operation. This optimization is critical for rapidly scoring large numbers of documents.
-
Metadata Filtering: This component handles the structured attributes associated with each document. Unlike the semantic content, metadata like
team,status,priority, orcreated dateare categorical or temporal values. Integrating these filters allows users to narrow down the search space before semantic scoring. This "filter before score" strategy is a fundamental optimization, preventing the system from expending computational resources on semantically relevant documents that nonetheless fail to meet specific contextual criteria. -
Scalable Indexing: For real-world applications, efficiently storing and querying these embeddings and metadata is paramount. While simple NumPy arrays can suffice for smaller datasets, production systems typically leverage specialized vector databases (e.g., Milvus, Pinecone, Weaviate) or enhanced search engines (e.g., Elasticsearch with vector search capabilities). These systems are designed to manage vast collections of vectors, offering optimized data structures (like Approximate Nearest Neighbor – ANN indexes) and distributed architectures for rapid retrieval. The ability to persist the index to disk, reloading it without re-encoding the entire corpus, is a non-negotiable requirement for operational efficiency.
A Practical Demonstration: The Engineering Support Ticket Corpus
To illustrate these principles, a Python-based context-aware search engine can be constructed over a simulated corpus of engineering support tickets. This dataset comprises 20 tickets, each a dictionary containing both a text field (the raw support ticket description) and several metadata fields: id, team (infrastructure, backend, frontend), status (open, resolved), priority (high, medium, low), and created date. This diversity in metadata allows for comprehensive filtering scenarios.
The initial setup involves preparing this dataset and performing a quick check of its distribution, revealing, for example, 14 open and 6 resolved tickets across the three teams. This preliminary step is crucial in any data-intensive application to understand the corpus’s characteristics.
Generating and Normalizing Embeddings
The first programmatic step involves transforming the text content of each ticket into its corresponding vector embedding. Using SentenceTransformer("all-MiniLM-L6-v2"), each ticket’s text is encoded. A critical detail here is normalize_embeddings=True, which ensures that each resulting vector has an L2 norm of exactly 1.0. This normalization streamlines the similarity calculation, allowing for direct dot products between query and document vectors, significantly speeding up the search process. For a corpus of 20 tickets, this results in a (20, 384) float32 matrix, where each row represents a ticket’s 384-dimensional embedding.
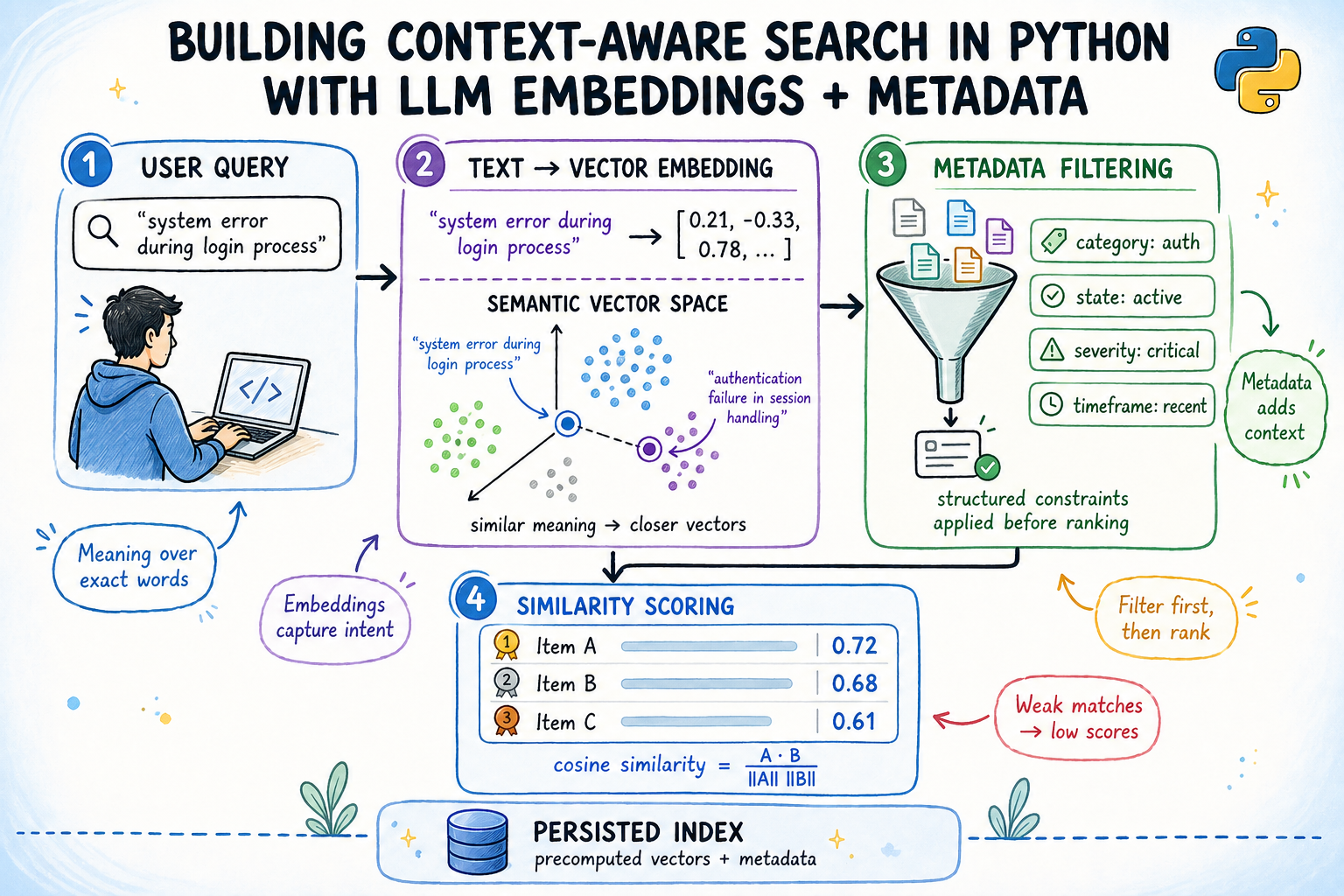
The Context-Aware Index: Bridging Semantics and Metadata
The core of the system is the ContextAwareIndex class. This class is initialized with the pre-computed embeddings and the original list of documents (containing both text and metadata). Its search method accepts a natural language query and an array of optional metadata filters (e.g., team, status, priority, after, before, min_score).
Upon receiving a query, the system first encodes the query text into an embedding vector, using the same all-MiniLM-L6-v2 model. Subsequently, it constructs a boolean mask. This mask, initially set to True for all documents, is iteratively updated to False for any document that fails to meet any of the specified metadata filter conditions. For instance, if status="open" is passed, all resolved tickets will have their corresponding mask entry set to False.
Only the documents that pass all metadata filters (i.e., where the mask remains True) are considered "candidates." The system then calculates the dot product between the query embedding and the embeddings of these candidate documents. These dot products represent the semantic similarity scores. Finally, any candidates falling below a specified min_score threshold are discarded, and the remaining top k results, sorted by their similarity scores, are returned, enriched with their original metadata and computed score. This "filter before score" mechanism is a testament to efficient design, ensuring computational resources are only spent on genuinely relevant and contextually appropriate documents.
Illustrative Query Scenarios and Their Implications
The power of context-aware search is best understood through practical examples:
-
Semantic Search Without Filters: A query like "authentication token expiry and session management" without any metadata constraints will rank documents purely on semantic similarity. In the engineering ticket corpus, this might yield high-scoring backend tickets related to "Session cookie persists after logout" or "OAuth2 token refresh fails intermittently." This baseline demonstrates the embedding model’s ability to grasp the conceptual meaning of the query, even if specific keywords are absent.
-
Filtering by Status and Date: Applying the same query text but adding filters such as
status="open"andbefore=date(2025, 11, 10)dramatically alters the candidate pool. This simulates a scenario where a support team is only interested in active, unresolved issues within a specific timeframe. The results will be semantically relevant tickets that also satisfy these temporal and status constraints. The absence of a ticket that might have been semantically relevant but was created after the specified date or was alreadyresolvedhighlights the precision gained by metadata filtering. -
Cross-Team Search with Priority Filter: A query like "resource exhaustion and memory pressure under load" combined with
status="open"andpriority="high"demonstrates the system’s ability to traverse organizational boundaries while maintaining focus on critical issues. Resource exhaustion problems can manifest in both infrastructure (e.g., "Kubernetes pod keeps crashing with OOMKilled") and backend (e.g., "Database connection pool exhausted") teams. The context-aware engine correctly identifies high-priority, open tickets from both domains that semantically align with the query, proving its utility in complex, cross-functional problem-solving. This scenario underscores the system’s capacity to group conceptually similar issues irrespective of their assigned team, a common pain point in large organizations.
Persisting the Index for Operational Efficiency
For any production-ready system, the costly process of generating embeddings must be performed once and then persisted. Re-encoding the entire corpus on every startup is computationally expensive and time-consuming. The solution involves saving the embedding matrix (typically as a binary .npy file) and the associated metadata (as a JSON file, with Python date objects converted to ISO format) to disk.
When a new session begins, the SentenceTransformer model is loaded from its local cache (if available, otherwise downloaded once), and then the embeddings and metadata are rapidly reloaded from their respective files. This two-stage process—model loading from cache and index reloading from saved data—ensures that the ContextAwareIndex can be rebuilt almost instantly, saving significant time and compute resources. This pattern is crucial for deploying such systems in dynamic environments where rapid restarts or scaling might be necessary.
Broader Impact and Future Outlook
The implications of context-aware semantic search extend far beyond IT support tickets. Industries across the spectrum are poised to benefit:
- Customer Support: Faster, more accurate resolution of customer queries by linking natural language questions to relevant documentation, FAQs, or past support tickets.
- E-commerce: Highly personalized product recommendations and search results that understand intent beyond exact product names, considering user preferences, purchase history, and product attributes.
- Legal and Compliance: Efficient discovery of relevant legal precedents, contractual clauses, or regulatory documents based on nuanced legal concepts and specific case parameters.
- Healthcare: Improved access to medical research, patient records, and diagnostic information, enabling clinicians to find relevant data based on symptoms, conditions, and treatment protocols.
- Research and Development: Accelerating scientific discovery by helping researchers navigate vast academic literature, patent databases, and internal reports, finding connections and insights that keyword search would miss.
Market data underscores this trend, with the global semantic search market projected to grow significantly in the coming years, driven by the increasing demand for intelligent information retrieval systems and the maturation of AI/ML technologies. Leading AI researchers and industry analysts consistently emphasize the strategic importance of effective knowledge management and the role of context-aware search in transforming how organizations interact with their data.
Looking ahead, the integration of context-aware search with generative AI capabilities promises even more revolutionary advancements. Imagine not just retrieving relevant documents but also generating synthesized answers, summaries, or even new content based on the semantically retrieved information, further enhancing human-computer interaction and decision-making. The combination of semantic understanding and metadata precision forms a robust foundation for the next generation of intelligent search platforms, enabling users to find not just information, but true knowledge.
