
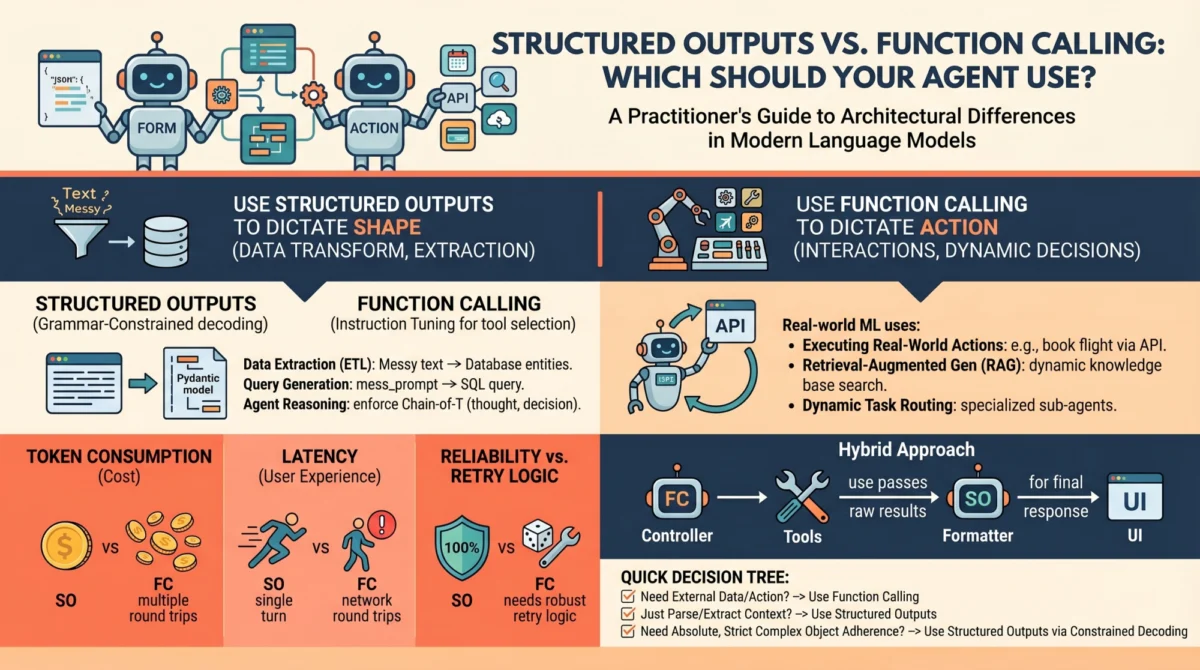
The landscape of artificial intelligence is undergoing a profound transformation, moving rapidly beyond rudimentary conversational agents to sophisticated, autonomous systems capable of complex decision-making and interaction with the external world. At the core of this evolution lies a critical architectural challenge: how to reliably bridge the gap between the inherently unstructured nature of large language models (LLMs) and the deterministic requirements of modern software applications. For machine learning practitioners building robust AI agents and scalable software pipelines, raw, free-form text outputs from LLMs are often insufficient, posing significant hurdles for parsing, routing, and integration.
To address this fundamental dilemma, leading LLM API providers, including OpenAI, Anthropic, and Google Gemini, have introduced two primary mechanisms designed to elicit predictable, machine-readable outputs: structured outputs and function calling. While superficially similar—both frequently leveraging JSON schemas under the hood and resulting in structured key-value pairs rather than conversational prose—they serve fundamentally distinct architectural purposes within agent design. Conflating these two capabilities is a common pitfall that can lead to brittle architectures, excessive latency, and unnecessarily inflated API costs. A nuanced understanding of their underlying mechanics and appropriate use cases is therefore paramount for any engineer navigating the complexities of advanced LLM integration.
The Evolution from Text-In, Text-Out to Programmatic Interaction
Historically, language models operated as simple text-in, text-out systems. A user would input a query, and the model would generate a textual response. While perfectly adequate for human-to-human-like conversation via a chat interface, this paradigm presented significant limitations for developers aiming to build applications that required programmatic control, data extraction, or interaction with external tools. Early attempts to force LLMs into generating structured data relied heavily on elaborate prompt engineering—techniques like "You are a helpful assistant that only speaks in JSON" were common. This approach, however, was notoriously error-prone, often requiring extensive retry logic, post-processing validation, and defensive programming to handle malformed outputs, leading to inconsistent performance and increased computational overhead.
The shift towards more reliable and deterministic LLM interactions began gaining significant momentum in late 2023 and early 2024, as major LLM providers recognized the growing demand for agents that could not only understand but also act upon information. This period marked a crucial turning point, as the industry moved from merely generating human-readable text to enabling machine-executable directives. This evolution was driven by the increasing sophistication of LLM architectures and training methodologies, particularly in areas like instruction tuning and grammar-constrained decoding, which paved the way for the robust features we see today. Industry reports suggest that the market for AI agents and intelligent automation is projected to grow significantly, with a CAGR exceeding 30% in the coming years, underscoring the critical need for reliable interaction mechanisms.
Unpacking the Mechanics: How They Work Under the Hood
To make informed architectural decisions, a deep understanding of the mechanical and API-level differences between structured outputs and function calling is essential. These distinctions are not merely semantic; they represent fundamentally different approaches to controlling LLM behavior and integrating them into software systems.
Structured Outputs Mechanics: Precision through Constraint
The modern implementation of "structured outputs" represents a significant departure from the unreliable prompt engineering of the past. Its core innovation lies in grammar-constrained decoding. This technique, implemented through libraries like Outlines, jsonformer, or native API features such as OpenAI’s Structured Outputs, mathematically restricts the token probabilities during the generation process.
When a developer defines a schema—typically a JSON schema—for the desired output, the LLM’s generation process is no longer purely free-form. Instead, at each step of token generation, the model’s vocabulary is dynamically pruned. If the specified schema dictates that the next token must be a quotation mark, a specific boolean value, or a numerical digit within a defined range, the probabilities of all non-compliant tokens are effectively masked out (set to zero). This forces the model to adhere strictly to the defined structure. For instance, if a schema expects a boolean value, the model will only consider generating tokens corresponding to "true" or "false" (or their respective sub-token components) at that specific point.
This mechanism ensures near 100% schema compliance, dramatically reducing parsing errors and the need for extensive retry logic. It operates as a single-turn generation process, strictly focused on the form of the output. The model directly answers the prompt, but its "vocabulary" is confined to the exact structural blueprint provided. This deterministic nature makes structured outputs ideal for scenarios where the primary goal is data transformation, extraction, or standardization, without requiring the model to initiate external actions or retrieve additional information. Research into grammar-constrained decoding has shown that it can improve output reliability by orders of magnitude compared to traditional prompting, reducing parsing errors from potentially over 10% to virtually zero in well-defined scenarios.
Function Calling Mechanics: Autonomy through Instruction Tuning
Function calling, in contrast, leverages a different paradigm, heavily relying on instruction tuning. During its training phase, the language model is specifically fine-tuned on datasets that teach it to recognize situations where it lacks the necessary information to complete a request or when the user’s prompt explicitly indicates an action needs to be taken. This training imbues the model with an understanding of when to pause its text generation and how to invoke an external tool.
When a developer provides a model with a list of available tools (functions), along with their descriptions and input schemas, they are essentially equipping the model with an extended capability set. The underlying instruction tuning allows the model to interpret this list as: "If you encounter a situation where you need to perform an action or retrieve information beyond your current knowledge, you can pause your current thought process, select a suitable tool from this list, and generate the necessary arguments to execute it."
This makes function calling an inherently multi-turn, interactive flow:
- User Query: The user or system sends a prompt to the LLM (e.g., "What’s the weather like in London?").
- Model’s Decision: The LLM, based on its instruction tuning and the provided tool definitions, recognizes that it needs external information (weather data) and identifies a suitable tool (e.g.,
get_current_weather(location: str)). - Tool Call Generation: The LLM generates a structured call to this tool, including the necessary arguments (e.g.,
"tool_name": "get_current_weather", "arguments": "location": "London"). This output itself often uses a form of structured generation, ensuring the arguments match the function’s schema. - Tool Execution: The application’s orchestration layer intercepts this tool call, executes the
get_current_weatherfunction (e.g., by making an API call to a weather service), and retrieves the result. - Response Integration: The result from the tool (e.g.,
"temperature": "15C", "conditions": "cloudy") is then fed back to the LLM, often as part of the ongoing conversation context. - Final Generation: The LLM, now possessing the required information, generates a natural language response to the original user query (e.g., "The weather in London is currently 15 degrees Celsius and cloudy.").
This iterative process enables the model to dynamically interact with its environment, making decisions and fetching data in real-time, which is crucial for building truly autonomous agents. A study by Google on their Gemini models highlighted the efficacy of instruction tuning in improving tool-use capabilities, noting significant improvements in task completion rates when models were explicitly trained to recognize and utilize external functions.
When to Choose Structured Outputs
Structured outputs should be the default choice whenever the primary objective is pure data transformation, extraction, or standardization, and all necessary information is contained within the prompt or context window.
Primary Use Case: The model has all the necessary information within the prompt and context window; it just needs to reshape, categorize, or extract specific data points from it.
Examples for Practitioners:
- Data Extraction: Extracting entities (names, dates, organizations) from unstructured text like legal documents, news articles, or customer reviews into a standardized JSON format for database ingestion. For example, processing a batch of customer feedback to identify sentiment, product features mentioned, and actionable insights.
- Content Summarization with Structure: Summarizing a long article into a structured format that includes a title, key takeaways, and a list of bullet points, ensuring consistency across multiple summaries.
- Configuration Generation: Generating configuration files (e.g., for software deployments or network settings) from natural language descriptions, ensuring the output adheres to a strict YAML or JSON schema.
- Semantic Parsing: Transforming natural language queries into structured query language (e.g., SQL, GraphQL) or API requests for internal systems, provided the necessary schema is defined.
- Data Validation and Cleaning: Taking semi-structured or messy input data and returning a cleaned, validated version adhering to a predefined schema, flagging any inconsistencies.
The Verdict: Use structured outputs when the "action" is purely about formatting, transformation, or extraction of existing data. Because there is no mid-generation interaction with external systems, this approach ensures high reliability, lower latency, and zero schema-parsing errors, making it ideal for high-throughput data processing pipelines. A financial institution, for example, might use structured outputs to parse thousands of earnings reports nightly, extracting key financial metrics into a consistent database schema with high confidence.
When to Choose Function Calling
Function calling is the true engine of agentic autonomy. If structured outputs dictate the shape of the data, function calling dictates the control flow of the application, enabling dynamic decision-making and external interaction.
Primary Use Case: External interactions, dynamic decision-making, and cases where the model needs to fetch information it doesn’t currently possess or execute an action in the real world.
Examples for Practitioners:
- Dynamic Information Retrieval: A chatbot answering questions about current stock prices, booking flights, or providing real-time weather updates, requiring calls to external APIs.
- Complex Agentic Workflows: An AI assistant that can manage a user’s calendar, send emails, search the web, or order groceries, involving multiple steps and interactions with various external services. OpenAI’s Assistants API, for instance, heavily leverages function calling to enable such complex, multi-turn interactions.
- Automated Customer Service: A support agent that can look up customer order details, check product availability in inventory systems, or initiate a refund process based on user requests.
- Interactive Data Analysis: An agent that can query a database, perform calculations using a Python interpreter, or generate visualizations based on user prompts, where each step requires invoking specific tools.
- Smart Home Control: An agent that can turn lights on/off, adjust thermostats, or lock doors by calling APIs connected to smart home devices.
The Verdict: Choose function calling when the model must interact with the outside world, fetch hidden data, or conditionally execute software logic mid-thought. It empowers the LLM to transcend its static knowledge base and become a dynamic orchestrator of actions, though this comes with increased complexity and potential latency. For developers, this means embracing an asynchronous, event-driven architecture to handle tool execution and response integration effectively.
Performance, Latency, and Cost Implications
When deploying AI agents to production, the architectural choice between structured outputs and function calling directly impacts unit economics and user experience. These factors are often overlooked in initial development but become critical at scale.
- Latency:
- Structured Outputs: Generally boast significantly lower latency. Since it’s a single-turn generation constrained by grammar, the process is streamlined. The model generates tokens until the schema is complete, without interruption for external calls. This often translates to completion times in the range of tens to hundreds of milliseconds, depending on the model size and output length.
- Function Calling: Inherently introduces higher latency. Each tool call involves a multi-step process: the LLM generating the tool call, the application executing the tool (which itself might involve network requests to external APIs), and then the LLM processing the tool’s result to generate a final response. This can add hundreds of milliseconds to several seconds per turn, especially if external APIs are slow or multiple tools are called sequentially. A 20% increase in latency can significantly degrade user experience for interactive applications, leading to higher abandonment rates.
- Reliability:
- Structured Outputs: Offers near-perfect reliability in terms of schema adherence. The grammar-constrained decoding mechanism ensures that the output will always conform to the specified structure, virtually eliminating parsing errors.
- Function Calling: While the generation of the function call arguments is highly reliable due to underlying structured output mechanisms, the overall reliability of the process depends on the external tools. If an external API is down, returns an error, or provides unexpected data, the entire function calling flow can break down or produce incorrect results. Robust error handling and retry mechanisms are crucial.
- Cost:
- Structured Outputs: Typically more cost-effective. It’s a single API call, and the token usage is generally confined to the input prompt and the structured output itself.
- Function Calling: Can be significantly more expensive. Each function call involves multiple API turns: the initial prompt, the model generating the tool call, the tool’s output being fed back to the model (often consuming tokens for both the tool name/arguments and the tool’s result), and finally the model generating the ultimate response. This multi-turn interaction directly translates to higher token usage and, consequently, higher API costs per interaction. Some providers may also have specific pricing tiers for function calling. A poorly designed agent that makes unnecessary tool calls can quickly inflate operational costs by 2x or 3x.
Hybrid Approaches and Best Practices
In advanced agent architectures, the distinction between structured outputs and function calling often blurs, leading to powerful hybrid approaches. Understanding this synergy is key to building truly sophisticated systems.
The Overlap:
It is crucial to recognize that modern function calling itself relies on structured outputs under the hood to ensure the generated arguments match your function signatures. When the LLM decides to call a tool, the output it generates (e.g., "tool_name": "...", "arguments": ...) is a structured JSON object, precisely what structured output mechanisms are designed for. Conversely, a developer can design an agent that exclusively uses structured outputs to return a JSON object describing an action that a deterministic system should execute after the generation is complete. This "faking tool use" effectively mimics tool execution without the multi-turn latency of native function calling, though it sacrifices the model’s dynamic decision-making mid-thought. For example, an agent might return "action": "search_web", "query": "latest AI news" and then a separate application layer would interpret this and perform the web search.
Architectural Advice:
- Prioritize Simplicity: Always default to structured outputs when the task can be accomplished within a single turn of generation. This maximizes reliability, minimizes latency, and reduces costs.
- Encapsulate Complexity: When function calling is necessary, encapsulate the external interactions within well-defined, robust tools. Ensure these tools have clear input/output schemas, comprehensive error handling, and appropriate logging.
- Layered Design: Implement a layered architecture where a core LLM-powered agent might use function calling for high-level decision-making, but then delegate specific data transformation or extraction tasks to sub-components that leverage structured outputs for efficiency. For example, an agent might decide to "summarize a document" (function call to a summarization tool) and that tool internally uses structured outputs to extract key entities before summarizing.
- Monitor and Optimize: Continuously monitor the performance, latency, and cost of your LLM interactions. Analyze logs to identify unnecessary function calls or opportunities to replace multi-turn interactions with single-turn structured outputs. Tools like LangChain or LlamaIndex often provide logging and tracing capabilities that are invaluable here.
- Security Considerations: When using function calling, be acutely aware of the security implications. Tools can interact with sensitive systems or external services. Implement strict access controls, input validation, and sanitization to prevent prompt injection attacks or malicious tool invocations.
The Broader Impact: Reshaping AI Development
The introduction and refinement of structured outputs and function calling mark a pivotal moment in LLM engineering. They are rapidly transitioning the field from crafting simplistic conversational chatbots to building reliable, programmatic, and genuinely autonomous agents that can seamlessly integrate into complex software ecosystems. This transition has several profound implications:
- Democratization of Agent Building: These mechanisms lower the barrier to entry for developing sophisticated AI agents. Developers can focus more on defining the agent’s capabilities and less on the intricacies of prompt engineering or parsing unreliable text outputs.
- Enhanced Reliability and Scalability: By providing deterministic outputs and controlled external interactions, these features enable the creation of more reliable and scalable AI applications. Enterprises can confidently deploy LLMs in mission-critical workflows, knowing the outputs will be consistent and actionable.
- New Skill Sets for Engineers: AI engineers must now possess a hybrid skill set, combining traditional software engineering principles (API design, error handling, system architecture) with LLM-specific knowledge (prompt engineering, schema definition, instruction tuning nuances). The role is evolving towards "prompt engineer" and "tool orchestrator."
- Accelerated Innovation: With robust tools for interaction, researchers and developers can rapidly prototype and deploy more ambitious AI applications, from hyper-personalized assistants to fully autonomous research agents.
- Ethical Considerations: As agents become more autonomous through function calling, the ethical implications become more pronounced. Issues of control, transparency, accountability, and potential misuse of powerful tools require careful consideration and robust safeguards.
Wrapping Up
The journey of LLM engineering is rapidly transitioning from crafting conversational chatbots to building reliable, programmatic, autonomous agents. Understanding how to constrain and direct your models is the key to successfully navigating this transition and unlocking the full potential of artificial intelligence.
TL;DR
- Structured Outputs: Best for transforming or extracting data already in the prompt. It’s single-turn, low-latency, low-cost, and highly reliable due to grammar-constrained decoding.
- Function Calling: Best for dynamic interactions, fetching external data, or executing actions. It’s multi-turn, higher-latency, potentially higher-cost, and relies on instruction tuning for decision-making.
The Practitioner’s Decision Tree
When building a new feature or agent component, run through this quick 3-step checklist to guide your architectural choice:
- Does the model need to interact with the outside world (e.g., fetch real-time data, send an email, control a device) OR make dynamic decisions about which external action to take?
- Yes: Use Function Calling. Design robust tools, anticipate multi-turn interactions, and prepare for higher latency/cost.
- No: Proceed to step 2.
- Does the model have all the necessary information within its current context/prompt, and the goal is simply to reformat, extract, or validate that information into a specific structure?
- Yes: Use Structured Outputs. Define a clear schema, expect high reliability and low latency/cost.
- No: Re-evaluate your prompt or the problem statement; perhaps the model needs more context or a different approach entirely.
- Can a multi-turn "action" be simulated by having the model generate a structured object describing the action, which a deterministic system then executes after the model’s generation is complete?
- Yes (and you prioritize low latency/cost over real-time model decision-making): Consider a hybrid approach with Structured Outputs acting as a pseudo-tool caller, followed by deterministic execution.
- No: Stick with the initial determination from steps 1 or 2.
Final Thought
The most effective AI engineers treat function calling as a powerful but unpredictable capability, one that should be used judiciously, sparingly, and always surrounded by robust error handling, monitoring, and security protocols. Conversely, structured outputs should be treated as the reliable, foundational glue that holds modern AI data pipelines together—the workhorse for deterministic data processing and integration. Mastering both is key to building the next generation of intelligent, reliable, and scalable AI applications.
