
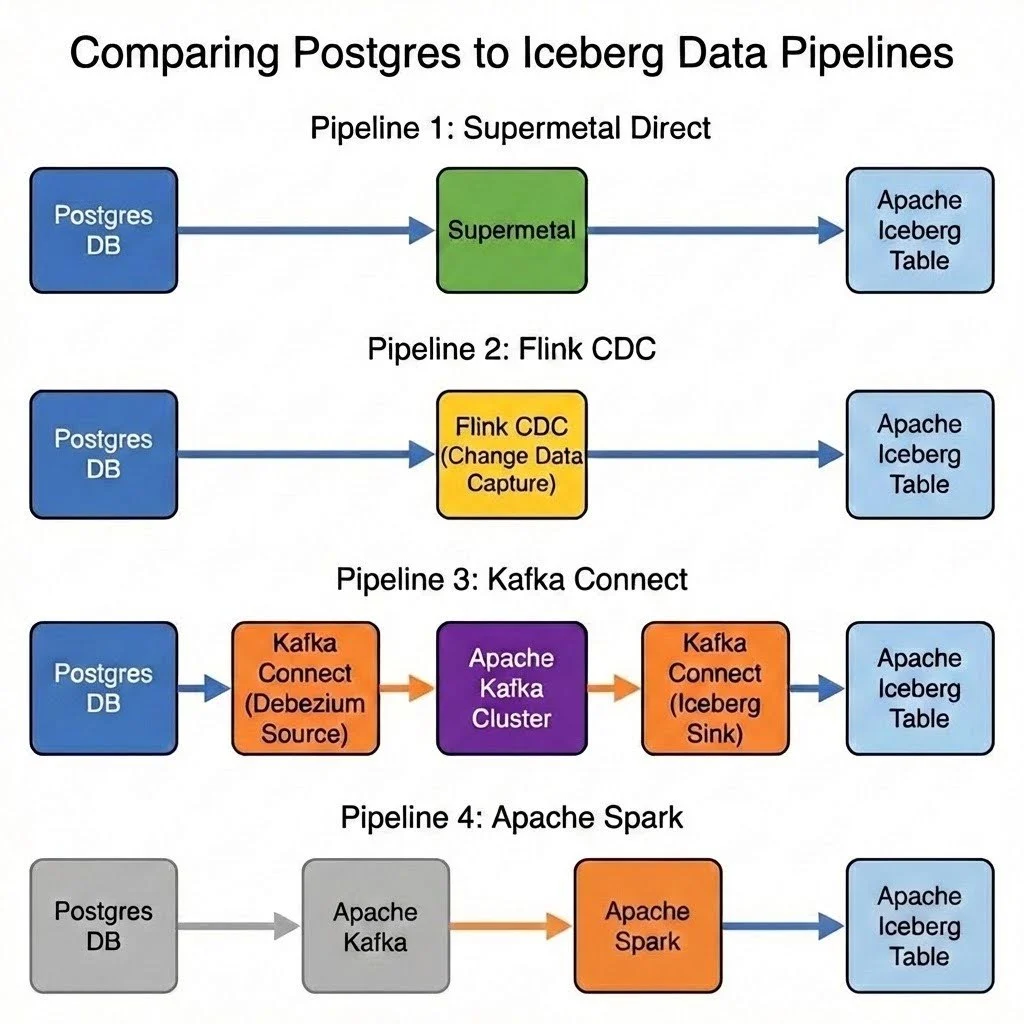
A recent benchmark comparing Supermetal’s new Iceberg sink capabilities against established open-source tools like Apache Flink, Kafka Connect, and Apache Spark has revealed significant performance advantages for Supermetal, particularly in the critical snapshotting phase of data pipelines. The tests, which focused on ingesting data from PostgreSQL to Iceberg, demonstrated that Supermetal could complete the initial data snapshotting process in just 13 minutes, a stark contrast to the 90-116 minutes required by Flink, 120 minutes by Kafka Connect, and over 3 hours by Spark. This substantial difference highlights Supermetal’s potential to streamline data lake modernization efforts.

The benchmark was commissioned by Supermetal and conducted by an independent researcher, with all testing performed on the researcher’s AWS account. The findings, shared "as is," provide a valuable comparison for organizations looking to build robust and efficient data pipelines to the Apache Iceberg table format.
The Challenge: From Relational Databases to Data Lakes

The process of migrating data from traditional relational databases, such as PostgreSQL, into modern data lake formats like Iceberg is a common requirement for organizations seeking to leverage big data analytics, machine learning, and advanced data warehousing capabilities. This often involves Change Data Capture (CDC) mechanisms to track and ingest incremental data changes alongside an initial bulk data load, known as snapshotting. The efficiency and speed of both these phases are crucial for maintaining up-to-date data stores and enabling timely data-driven insights.
The benchmark aimed to evaluate the end-to-end pipeline performance, focusing on the snapshotting phase where bulk data transfer is paramount. Latency was not the primary concern, as data archival workloads typically have more flexible requirements in this regard. Instead, the focus was on maximizing throughput. To ensure a fair comparison, the tests were conducted on a single node with identical resource allocations across all tested tools, avoiding scale-out scenarios to understand single-node capabilities.

Test Setup: A Realistic Data Pipeline Scenario
The benchmark utilized the TPC-H dataset, a standard benchmark for decision support systems, with a scale factor (SF) of 50. This scale factor resulted in a substantial dataset, with the largest table, "lineitem," containing approximately 300 million rows, and the "orders" table containing around 75 million rows.

The infrastructure for the tests included:
- AWS EC2 Instance:
m5.4xlarge(16 vCPU, 64 GiB RAM) - Storage: AWS S3 for Iceberg data and staging
- Database: PostgreSQL (version 15.3)
- Object Storage: AWS S3
- Iceberg Catalog: AWS Glue
The software versions used were:

- Supermetal:
0.22.1 - Apache Flink:
1.18.1 - Kafka Connect:
3.6.1 - Debezium:
2.5.0 - Apache Spark:
3.4.1
Supermetal, a platform designed for data pipelines, offers direct support for PostgreSQL CDC sources and Iceberg sinks. A key differentiator highlighted in the benchmark is Supermetal’s ability to bypass external orchestrators like Kafka, enabling direct data transfer from source to sink, with optional object storage buffering.
The configuration for a complete PostgreSQL to Iceberg pipeline within Supermetal was notably concise, using a JSON file to define sources and sinks. This configuration specified the PostgreSQL connection details, logical replication for CDC, and the target Iceberg catalog (AWS Glue in this case), including the warehouse location and target namespace. The configuration allowed for dynamic discovery of tables, simplifying the setup process. Supermetal’s Iceberg sink supports various catalog types, Iceberg versions (V1, V2, V3), and offers flexibility in write modes (Append vs. Merge on Read), Parquet target file size, and compression.

A unique aspect of Supermetal’s approach, as pointed out in the analysis, is its ability to automatically adjust file flushing configurations based on the data ingestion phase. During snapshotting, it can optimize for bulk appends, while during live CDC, it can switch to strategies more suitable for incremental updates, a capability not typically found in tools that decouple sources and sinks entirely.
Benchmark Results: Supermetal Dominates Snapshotting

The benchmark’s primary finding was Supermetal’s exceptional snapshotting performance. The platform completed the entire snapshotting process in a remarkable 13 minutes. This performance was accompanied by low CPU and memory utilization, with Supermetal consuming no more than 5% of the allocated memory. The inter- and intra-table parallelization capabilities during the snapshot phase were cited as key contributors to this speed. It was also noted that Supermetal utilizes an append-only mode during snapshotting, eschewing table-level key tracking or deduplication for maximum speed. The resulting Parquet file sizes for the largest table were consistently ideal, aligning with the specified target size.
Comparison with Open-Source Tools

-
Apache Flink: Flink, when configured with its PostgreSQL CDC connector and Iceberg connector, managed to complete the snapshotting in approximately 90-116 minutes. Initially, with default settings and upserting enabled, the job took around 3.5 hours. Significant tuning of the CDC source’s fetch and split sizes, along with increasing the checkpoint interval, was required to bring the completion time down to under two hours. Disabling upserting and switching to append-only mode further reduced this to 1.5 hours. Despite optimizations, Flink’s CPU and memory usage were higher than Supermetal’s, and Parquet file sizes were less uniform. The benchmark noted that Flink’s checkpoint interval heavily influences data flushing, making precise control over file sizes challenging.
-
Kafka Connect: Utilizing Debezium for PostgreSQL CDC and the Iceberg connector, Kafka Connect relies on Kafka as an intermediary. The benchmark reported a completion time of approximately 120 minutes for Kafka Connect. The configuration leveraged Debezium’s transformation capabilities to route data to dynamic Iceberg tables, similar to Flink’s Dynamic Sink. Tuning of Debezium’s
linger.msandbatch.sizewas necessary to mitigate the CDC bottleneck. Notably, Kafka Connect exhibited particularly high CPU utilization throughout the run, though profiling did not reveal specific bottlenecks, suggesting a balanced distribution of effort between CDC processing and Iceberg writing. Parquet file sizes were well-distributed.
-
Apache Spark: Spark, lacking a first-class CDC connector, required a multi-stage approach: Kafka Connect with Debezium to ingest data into Kafka topics, followed by a Spark job consuming from Kafka and writing to Iceberg. This setup resulted in the longest completion time, exceeding 3 hours. The benchmark indicated that Spark struggled on a single executor with limited cores, with eight independent queries (one per topic) competing for resources and incurring individual checkpoint and commit overhead. Despite tuning efforts, the best run achieved was 3 hours and 20 minutes. The executor CPU remained low, attributed to Spark’s design for large-scale, distributed environments rather than single-node performance. Parquet file sizes were uniform, largely controlled by
maxOffsetsPerTrigger.
Data Correctness and Unique Architectural Approaches

A critical aspect of any data pipeline benchmark is data correctness. The researcher confirmed that all tools successfully synchronized data without loss or duplication, with table counts matching between PostgreSQL and Iceberg. Minor differences were observed in column order and the presence of additional metadata columns.
The analysis highlighted a key difference in Supermetal’s architecture. While most tools maintain a strict decoupling between sources and sinks, Supermetal’s Iceberg writer can dynamically adjust its configuration based on the CDC source phase—snapshotting versus live updates. This "sideways information-passing" approach allows for sink-level optimizations, such as leveraging append-only mode and specific file sizing during snapshotting, and switching to merge-on-read and time-based intervals during live CDC. This contrasts with the more uniform approach of other tools, where sink behavior is generally consistent across different data ingestion phases.

Implications for Data Modernization
The benchmark results suggest that Supermetal offers a compelling solution for organizations looking to accelerate their migration to data lakes built on Iceberg. The dramatic reduction in snapshotting time translates directly to faster data availability and reduced downtime during migration projects. For organizations facing challenges with the performance of existing CDC mechanisms, Supermetal’s ability to optimize the entire pipeline, including the sink-side adjustments, presents a significant advantage.

While Flink and Kafka Connect offer mechanisms for dynamic routing of data to multiple Iceberg tables, Spark requires a more manual approach with separate queries per table. Supermetal’s integrated and streamlined configuration for complex pipelines further simplifies adoption.
It’s important to note that the benchmark focused on single-node performance. While other tools can be scaled horizontally, this often incurs significant costs. Supermetal also supports horizontal scaling, with a single table often serving as the unit of scaling, offering a potentially more cost-effective approach for certain workloads.

The findings underscore the evolving landscape of data integration and the increasing demand for efficient, high-performance solutions that can bridge the gap between traditional databases and modern data lake architectures. Supermetal’s recent Iceberg sink support appears to be a significant step forward in this domain, offering a potentially faster and more streamlined path for data ingestion and modernization.
