
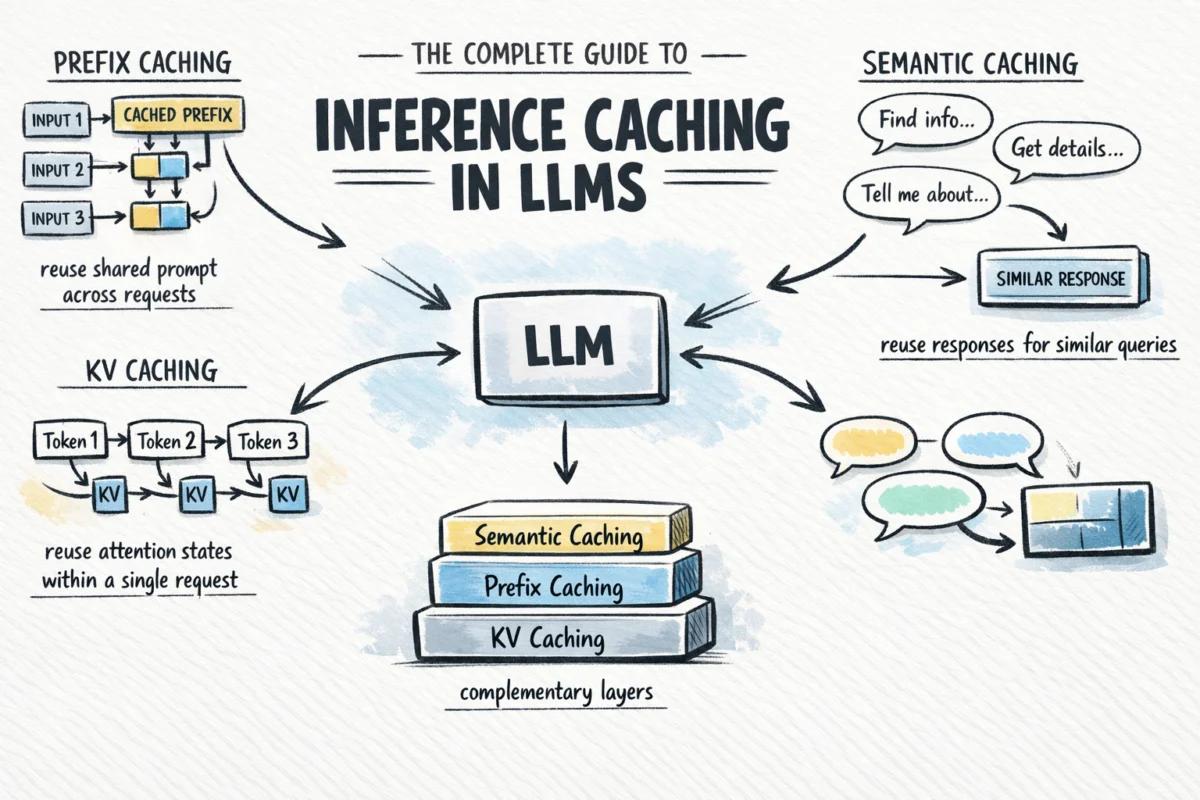
In this comprehensive analysis, we delve into the critical role of inference caching in large…
Tag: caching
AI & Machine Learning


Continue Reading
Deconstructing Large Language Model Inference: The Essential Roles of Prefill, Decode, and KV Caching for Scalable Text Generation
The intricate process by which large language models (LLMs) generate coherent and contextually relevant text,…
