
In this comprehensive analysis, we delve into the critical role of inference caching in large language models (LLMs) and explore its multifaceted application in mitigating the substantial costs and latencies associated with production-grade AI systems. As LLMs become increasingly integrated into enterprise solutions and consumer applications, the efficiency of their deployment has emerged as a paramount concern for developers and businesses alike. Inference caching stands as a pivotal optimization strategy, addressing the inherent computational demands of these sophisticated models by intelligently storing and reusing previously computed results.
The exponential growth in the adoption of large language models over recent years has been accompanied by a parallel increase in operational challenges, particularly concerning computational resources. Processing natural language at scale with models comprising billions of parameters demands immense processing power, leading to high infrastructure costs and noticeable delays in response times. A significant portion of this expenditure stems from redundant computation: the repeated processing of identical system prompts, standard instructions, or frequently asked queries that, without optimization, are treated as novel inputs with every request. Inference caching directly confronts this inefficiency, offering a layered approach to store the outputs of expensive LLM computations and subsequently retrieve them when an equivalent request is encountered.
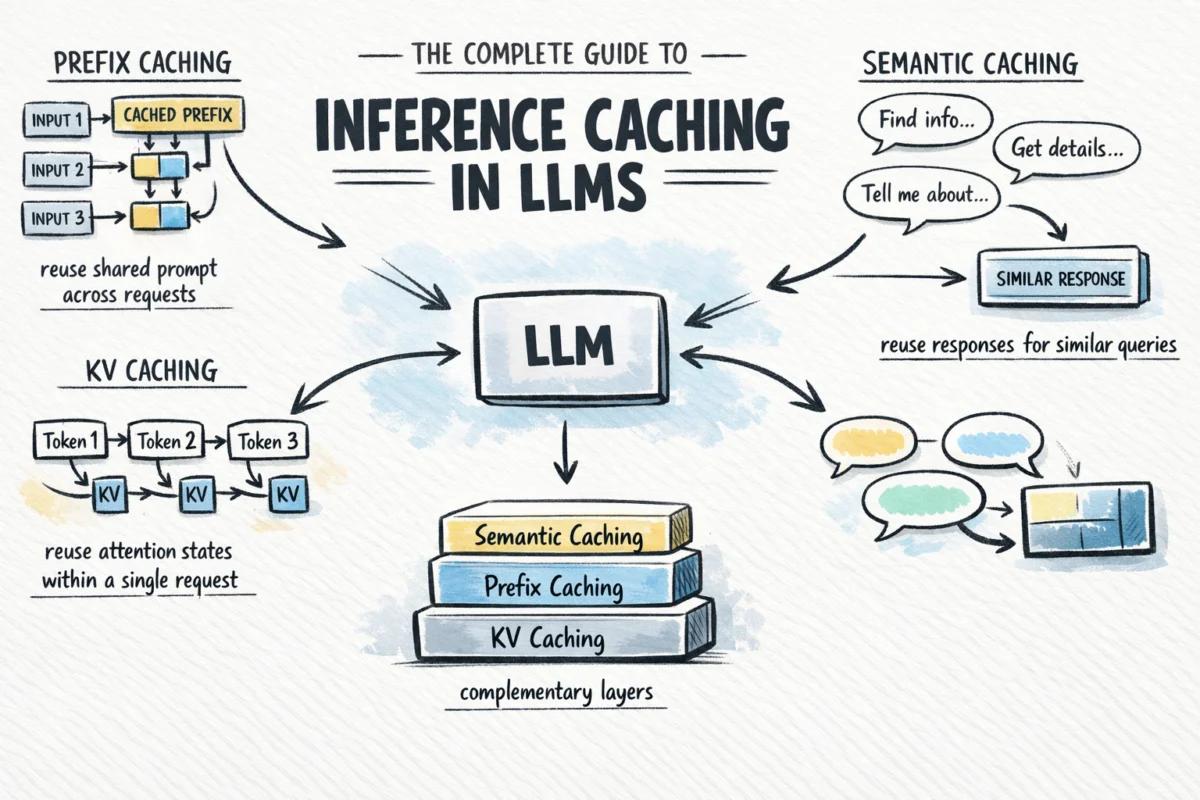
This technological advancement allows for significant reductions in token spend and latency, often with minimal modifications to existing application logic. Depending on the specific caching layer implemented, systems can bypass redundant attention computations mid-request, avoid reprocessing common prompt prefixes across numerous user interactions, or even serve complete, pre-generated responses for frequently asked questions without invoking the underlying language model at all. This article will systematically explore the mechanisms, applications, and strategic implications of the three primary types of inference caching: KV caching, prefix caching, and semantic caching, culminating in a practical framework for their effective integration into LLM-powered systems.
Understanding the Computational Burden of LLMs
To appreciate the value of inference caching, it is crucial to first understand the computational mechanics that make LLMs so resource-intensive. Modern LLMs are predominantly built upon the transformer architecture, first introduced in 2017, which revolutionized sequence processing through its self-attention mechanism. This mechanism allows the model to weigh the importance of different words in an input sequence when processing each word, thereby grasping context across potentially very long texts.
For every token – the fundamental unit of text processing – in an input sequence, the model computes three distinct vectors: a Query (Q), a Key (K), and a Value (V). These vectors are instrumental in the attention calculation: attention scores are derived by comparing each token’s query against the keys of all preceding tokens in the sequence. These scores then weight the values, allowing the model to aggregate contextual information. The computational complexity of this attention mechanism scales quadratically with the sequence length, meaning that even moderately long prompts can lead to a significant increase in processing time and cost.
LLMs generate output tokens autoregressively, one token at a time. In a naive implementation without caching, generating the Nth token would necessitate recalculating the K and V vectors for all N-1 preceding tokens from scratch. This re-computation for every decode step becomes prohibitively expensive for longer sequences, as the cost compounds with each successive token generation. For instance, generating a 100-token response could involve 100 separate passes, each reprocessing a progressively longer sequence of previously generated tokens. This inherent inefficiency is the primary target for inference caching techniques.
The Foundation: KV Caching Explained
KV caching is the foundational layer of inference optimization, intrinsically linked to the transformer architecture itself. It addresses the autoregressive nature of LLM generation by storing the Key (K) and Value (V) vectors computed during the forward pass for each token.
During the initial processing of an input prompt, as each token passes through the model, its corresponding K and V vectors are computed. Instead of discarding these, KV caching stores them in the GPU memory. For subsequent decode steps, when the model generates the next token, it simply retrieves the stored K and V pairs for all existing tokens from memory. Only the newly generated token requires fresh computation of its Q, K, and V vectors. This dramatically reduces redundant calculations.
Consider an example:
- Without KV caching (generating token 100): The model would recompute K and V for tokens 1 through 99, then compute token 100. This is 99 redundant computations.
- With KV caching (generating token 100): The model loads the stored K and V for tokens 1 through 99 from memory, then computes only token 100. The previous 99 computations are avoided.
This mechanism is fundamental and universal; virtually every LLM inference framework, from PyTorch to specialized serving engines like vLLM, implements KV caching by default. It is an optimization that operates within a single request, improving the efficiency of the token generation process. Developers typically do not need to configure KV caching explicitly, but understanding its operation is crucial for comprehending more advanced caching strategies, particularly prefix caching, which extends this concept across multiple requests. Industry reports suggest that KV caching can lead to a 2x-5x improvement in generation speed for long sequences compared to uncached autoregressive decoding, significantly impacting user experience for interactive applications.
Extending Efficiency: Prefix Caching Across Requests
Building upon the principles of KV caching, prefix caching (also known as prompt caching or context caching) takes the optimization a significant step further by extending the storage of attention states across multiple requests. This technique specifically targets shared prompt prefixes, which are ubiquitous in real-world LLM applications.
The Core Idea and its Impact
Many LLM deployments involve a consistent "system prompt" or a lengthy "context window" that precedes user-specific input. This might include detailed instructions for the AI’s persona, extensive reference documents, few-shot examples to guide its behavior, or specific formatting requirements. In a conventional setup, this entire static prefix would be re-processed from scratch for every single user request, incurring substantial and repetitive computational cost.
Prefix caching addresses this by computing the KV states for the shared prefix once, storing them, and then reusing them for all subsequent requests that share that identical prefix. When a new request arrives, the model loads the pre-computed KV states for the system prompt, effectively "skipping" the initial processing phase and jumping directly to the user’s dynamic input. This can lead to dramatic cost savings and latency reductions, especially in high-volume scenarios where the shared prefix is substantial. Developers using prefix caching have reported up to an 80% reduction in API costs for applications with long, stable system prompts, alongside a 20-50% improvement in time-to-first-token latency.
The Hard Requirement: Exact Prefix Match
A critical aspect of prefix caching is its strict requirement for an exact byte-for-byte match of the cached portion of the prompt. Any deviation, no matter how minor – a trailing space, a subtle punctuation difference, or even a reordered JSON key – will invalidate the cache and force a full recomputation. This imposes specific structural requirements on prompt design:
- Static Content First: System instructions, reference documents, few-shot examples, and any other unchanging information should consistently appear at the beginning of the prompt.
- Dynamic Content Last: User-specific messages, session IDs, current dates, or other variable inputs must be appended after the static prefix.
- Deterministic Serialization: When embedding structured data like JSON into prompts, ensure that the serialization process is deterministic. Non-deterministic key ordering, for instance, will prevent cache hits even if the underlying data is semantically identical.
Provider Implementations and Industry Adoption
Major LLM API providers have recognized the profound impact of prefix caching and have begun integrating it as a first-class feature:
- Anthropic: Offers "prompt caching" where users explicitly opt-in by adding a
cache_controlparameter to the content blocks intended for caching. This granular control allows developers to precisely define which parts of their prompts are stable and eligible for caching. - OpenAI: Implements prefix caching automatically for prompts exceeding a certain token threshold (e.g., 1024 tokens), abstracting much of the complexity from the developer. However, the underlying principle of a stable leading prefix remains paramount for effective caching.
- Google Gemini: Refers to this as "context caching" and, in some configurations, charges for the storage of cached contexts separately from inference. This model encourages its use for very large, highly stable contexts that are reused extensively, optimizing for long-term cost efficiency.
Beyond API providers, open-source inference frameworks like vLLM and SGLang have integrated automatic prefix caching capabilities for self-hosted models. These engines transparently manage the caching process, often without requiring any modifications to the application code, making it easier for organizations to deploy optimized LLM solutions on their own infrastructure. Industry experts widely regard prefix caching as the highest-leverage optimization for most production LLM applications today, given the prevalence of shared prompt structures.
Intelligent Optimization: Semantic Caching for Meaning-Based Retrieval
While KV caching and prefix caching operate at the token and sequence prefix level, semantic caching introduces a fundamentally different approach, operating at the application layer by storing complete LLM input/output pairs and retrieving them based on meaning rather than exact token matches. This enables an entirely new dimension of efficiency, bypassing the LLM call entirely for semantically similar queries.
How Semantic Caching Works
The practical distinction is significant: prefix caching makes processing a long, shared system prompt more efficient, whereas semantic caching aims to skip the model inference altogether when a query that has already been answered (or one very similar to it) arrives. Here’s a breakdown of its operational flow:
- Query Embedding: When a new user query arrives, it is first converted into a numerical vector representation, known as an embedding, using a specialized embedding model. This embedding captures the semantic meaning of the query.
- Vector Database Search: This query embedding is then used to perform a similarity search against a vector database. This database contains embeddings of previous user queries, along with their corresponding LLM responses.
- Cache Hit/Miss:
- Cache Hit: If a sufficiently similar query embedding (above a predefined similarity threshold) is found in the database, the associated cached LLM response is retrieved and returned directly to the user. The LLM is never invoked.
- Cache Miss: If no sufficiently similar query is found, the original query is sent to the LLM for inference.
- Cache Population: The LLM’s generated response, along with the original query’s embedding, is then stored in the vector database for future retrieval.
In production environments, robust vector databases such as Pinecone, Weaviate, Milvus, or pgvector are commonly employed. It is also crucial to implement appropriate Time-To-Live (TTL) policies to prevent stale or outdated cached responses from persisting indefinitely, ensuring the freshness and relevance of retrieved information.
When Semantic Caching is Worth the Overhead
Semantic caching introduces an additional computational step – generating an embedding and performing a vector search – for every incoming request. This overhead only yields a net benefit when the application experiences a sufficient volume of repetitive or semantically similar queries, leading to a high cache hit rate that justifies the added latency of the embedding and search operations, and the infrastructure cost of the vector database.
Semantic caching is most effective for applications characterized by:
- FAQ-style interactions: Where users frequently ask the same questions using slightly different phrasing.
- Customer support bots: Handling common inquiries where standardized answers are acceptable.
- Knowledge base retrieval systems: When users are seeking information that has been previously queried and summarized.
- High query volume with predictable patterns: Systems where user input often converges on a limited set of core topics or questions.
For applications with highly dynamic, unique, or rapidly evolving queries, the overhead of semantic caching might outweigh its benefits, leading to minimal cache hits and increased overall latency. Therefore, a careful analysis of query patterns and expected hit rates is essential before implementing this strategy.
Strategic Implementation: Choosing the Right Caching Strategy
The three distinct types of inference caching – KV caching, prefix caching, and semantic caching – operate at different layers of the LLM stack and address unique computational challenges. They are not mutually exclusive alternatives but rather complementary layers that can be combined for maximum efficiency.
| USE CASE | CACHING STRATEGY | RATIONALE |
|---|---|---|
| All LLM applications, always | KV caching (automatic, no configuration needed) | Fundamental architectural optimization within a single request; significantly speeds up autoregressive token generation by reusing K/V states. It’s universally enabled and provides the baseline efficiency. |
| Long system prompt shared across many users | Prefix caching | Eliminates redundant processing of the static system prompt for every request. Essential for applications with detailed instructions, persona definitions, or extensive common context, yielding substantial cost and latency reductions. |
| RAG pipeline with large shared reference documents | Prefix caching for the document block | When a Retrieval-Augmented Generation (RAG) system consistently uses the same large reference documents for a set of queries, caching the document’s embedding and context allows the model to bypass reprocessing this information, focusing solely on the user’s specific query and its interaction with the context. |
| Agent workflows with large, stable context | Prefix caching | In multi-turn conversations or agentic loops where a significant portion of the context (e.g., agent’s persona, tool definitions, ongoing task state) remains constant across turns, prefix caching ensures this stable context is processed only once, accelerating subsequent interactions. |
| High-volume application where users paraphrase the same questions | Semantic caching | Best for FAQ-style or support applications where users frequently ask semantically similar questions using varied phrasing. Bypasses LLM inference entirely for cache hits, offering the greatest cost and latency savings when applicable. Requires analysis of query patterns to justify overhead. |
The most effective production systems adopt a layered approach:
- KV caching is always active, providing the fundamental speed-up for token generation.
- The next, and often highest-leverage, step is to implement prefix caching for any stable system prompts, instructions, or shared context documents. This immediately tackles a major source of redundant computation and cost.
- Finally, semantic caching can be layered on top if the application’s query patterns and volume justify the additional infrastructure and potential overhead. This is a strategic choice for specific use cases where bypassing the LLM entirely for frequently asked questions provides a significant advantage.
This tiered strategy ensures that optimization efforts are applied where they yield the greatest return, progressively reducing computational load from the lowest-level architectural operations to high-level application interactions.
Industry Adoption and Expert Perspectives
The rapid evolution and adoption of inference caching strategies underscore a growing maturity in the LLM ecosystem. Major cloud providers and AI companies are actively integrating these features, signaling their importance in making LLMs more economically viable and performant for a broader range of applications.
"Inference caching is no longer a niche optimization; it’s a fundamental requirement for anyone deploying LLMs in production at scale," states Dr. Anya Sharma, a lead AI architect at a prominent tech firm. "The cost efficiencies and latency improvements are simply too significant to ignore. We’ve seen projects become economically feasible only after implementing robust caching strategies."
The move by providers like OpenAI, Anthropic, and Google to offer these capabilities as managed features also democratizes access to these optimizations. Smaller businesses and developers, who might lack the deep engineering resources to implement complex caching systems from scratch, can now leverage these performance gains through API configurations. This trend is expected to accelerate the development and deployment of LLM-powered applications across various industries, from healthcare to finance.
Furthermore, the open-source community, through projects like vLLM and SGLang, continues to push the boundaries of automatic and transparent caching, allowing developers to benefit from these optimizations even when self-hosting models. This collaborative effort ensures that both proprietary and open-source LLM deployments can achieve high levels of efficiency.
Broader Economic and Technical Implications
The widespread adoption of inference caching carries significant economic and technical implications for the future of AI.
Economic Viability: By substantially reducing the operational costs of LLM inference, caching makes sophisticated AI applications more accessible and affordable. This enables businesses to deploy more feature-rich LLM experiences without incurring prohibitive expenses, potentially unlocking new use cases and markets. For instance, a customer service chatbot that previously cost cents per interaction might now cost fractions of a cent, making high-volume deployments more attractive.
Enhanced User Experience: Reduced latency directly translates to a better user experience. Faster response times in conversational AI, code generation, or content creation tools make interactions feel more natural and responsive, driving higher user engagement and satisfaction.
Resource Optimization: Caching optimizes the utilization of scarce and expensive GPU resources. By avoiding redundant computations, fewer GPUs are needed to handle a given workload, or existing infrastructure can support a significantly higher volume of requests. This has environmental benefits as well, reducing the energy footprint associated with large-scale AI operations.
Innovation and Scalability: With cost and latency barriers lowered, developers are empowered to experiment with more complex LLM-based architectures, such as multi-agent systems or elaborate RAG pipelines, knowing that the underlying inference will be more efficient. This fosters innovation and allows applications to scale more effectively to meet growing demand.
Shift in Development Paradigms: The need for effective caching also influences prompt engineering. Developers are increasingly designing prompts with caching in mind, structuring them to maximize cache hits. This includes a greater emphasis on stable system prompts and deterministic input formatting.
Conclusion
Inference caching represents a suite of indispensable techniques for optimizing the performance and cost-efficiency of large language models in production environments. It is not a singular solution but a layered approach comprising:
- KV caching: An intrinsic, low-level optimization within the transformer architecture that significantly accelerates autoregressive token generation.
- Prefix caching: A high-leverage strategy that reuses attention states for common prompt prefixes across multiple requests, dramatically reducing cost and latency for applications with stable contexts.
- Semantic caching: An application-layer optimization that stores and retrieves full LLM responses based on semantic similarity, bypassing the model entirely for frequently asked or semantically equivalent queries.
For the majority of production LLM applications, the most impactful initial step is to ensure that prefix caching is effectively enabled and utilized for system prompts and shared context. From this foundation, semantic caching can be strategically integrated if the application’s specific query patterns and volume demonstrate a clear benefit, justifying the additional architectural complexity.
Ultimately, inference caching stands as a testament to the ongoing engineering efforts to bridge the gap between the immense capabilities of LLMs and the practical demands of real-world deployment. By thoughtfully applying these techniques, developers and organizations can unlock the full potential of large language models, delivering more responsive, cost-effective, and scalable AI solutions without compromising on the quality or intelligence of their outputs. As LLMs continue to evolve, the art and science of inference caching will remain a critical discipline, driving the next wave of AI innovation and adoption across industries.
