
In an era defined by an exponential surge in unstructured text data, from customer feedback and social media posts to scientific literature and legal documents, the ability to efficiently categorize and understand this deluge of information has become paramount for businesses and researchers alike. Traditional text classification methods often demand extensive, meticulously labeled datasets for each specific task, a process that is both time-consuming and resource-intensive. However, a groundbreaking paradigm shift is underway with the advent of zero-shot text classification, a technique that allows for accurate text labeling without the need for task-specific training data. This article will explore the mechanics, applications, and profound implications of zero-shot classification, demonstrating how pretrained transformer models are revolutionizing the landscape of natural language processing (NLP) and offering unprecedented agility in text analysis workflows.
The Foundational Challenge of Text Classification
For decades, the standard approach to text classification involved supervised machine learning. This method required human annotators to label thousands, or even millions, of text examples with predefined categories. For instance, to classify customer support tickets, a company would need to manually tag countless tickets as "billing issue," "technical support," "account query," and so forth. This labeled data would then be fed into a machine learning algorithm, which would learn the intricate patterns and relationships between the text content and its corresponding labels. While effective, this process is a significant bottleneck. The cost of data annotation can be prohibitive, ranging from hundreds to thousands of dollars per dataset, and the time required often delays project deployment. Furthermore, as business needs evolve and new categories emerge, the entire training process must be repeated, rendering the system inflexible and slow to adapt. The sheer volume of text generated daily, estimated to be exabytes, underscores the urgency for more agile and scalable solutions.
Introducing Zero-Shot Text Classification: A New Paradigm
Zero-shot text classification emerges as a powerful antidote to these challenges. At its core, this innovative technique allows a model to classify text into categories it has never explicitly been trained on. Instead of learning a fixed mapping from text features to predefined label IDs, the model leverages its vast general understanding of language, acquired during pre-training on massive text corpora, to reason about the semantic relationship between an input text and a set of candidate labels. This fundamentally transforms the classification problem from a direct prediction task into a sophisticated reasoning exercise.
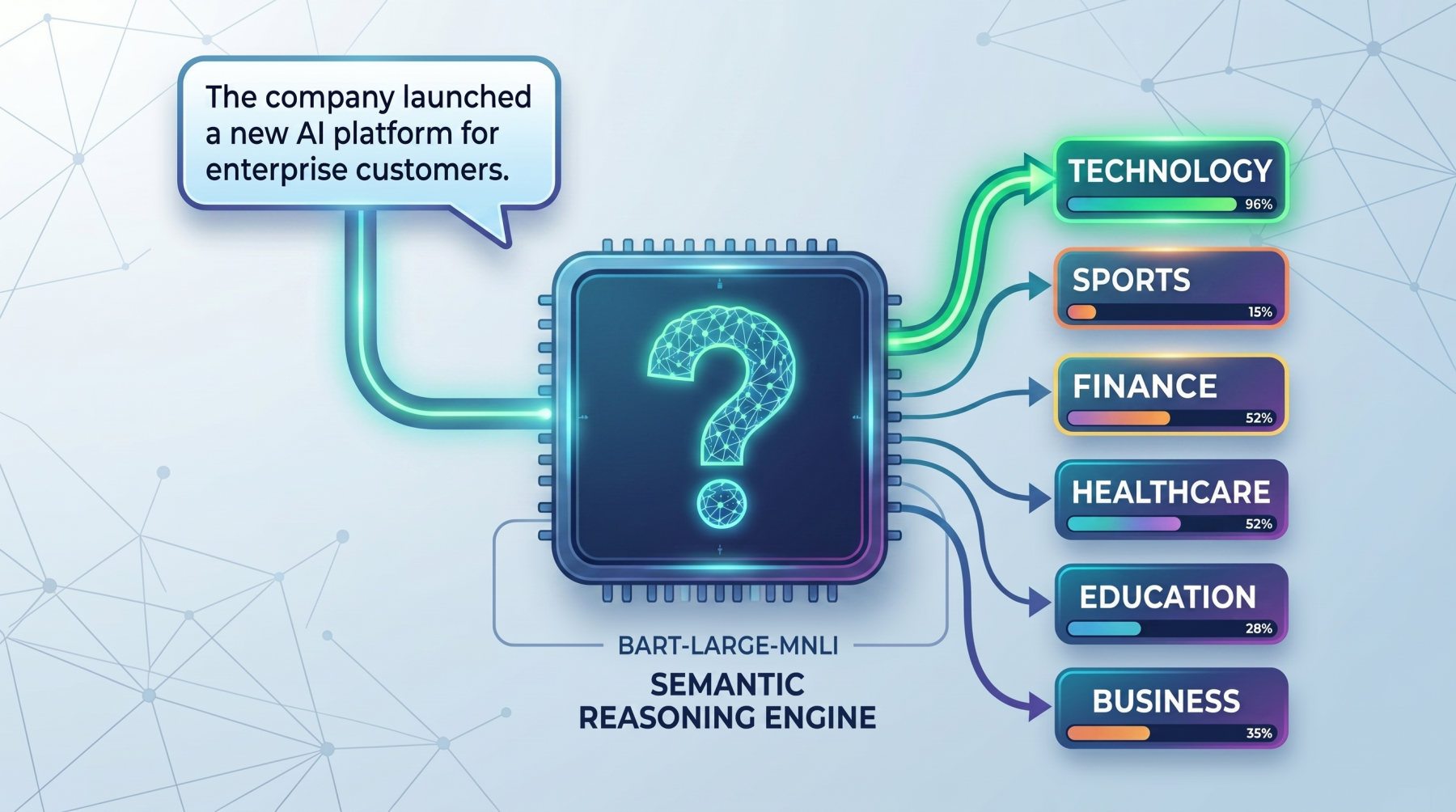
The mechanism behind zero-shot classification is elegantly simple yet profoundly effective. When presented with an input text and a list of potential labels, the model doesn’t treat the labels as arbitrary tags. Instead, it converts each candidate label into a natural language hypothesis or statement. For example, if the input text is "The company launched a new AI platform for enterprise customers" and the candidate labels are "technology," "sports," and "finance," the model conceptually rephrases these into statements such as:
- "This text is about technology."
- "This text is about sports."
- "This text is about finance."
The model then assesses how strongly the original input text supports or contradicts each of these hypothetical statements. This evaluation is typically performed using a Natural Language Inference (NLI) framework, where the model determines the entailment (support), contradiction (opposition), or neutrality between the input text (premise) and each hypothesis (label statement). The label whose corresponding hypothesis is most strongly entailed by the input text is selected as the best fit. This ability to generalize from prior linguistic knowledge makes zero-shot models incredibly versatile and adaptable.
The Evolution of Enabling Technologies: From Statistical NLP to Transformers
The journey to zero-shot capabilities is deeply intertwined with the advancements in natural language processing. Early NLP systems relied heavily on rule-based methods and statistical models, which struggled with the nuances and complexities of human language. The breakthrough came with the advent of neural networks, particularly recurrent neural networks (RNNs) and convolutional neural networks (CNNs), which could learn more sophisticated representations of text. However, these models often faced limitations in processing long-range dependencies in text and required significant computational resources.
The true inflection point arrived with the introduction of the transformer architecture in 2017 by Google Brain researchers in their seminal paper "Attention Is All You Need." Transformers, characterized by their self-attention mechanisms, revolutionized sequence modeling by allowing parallel processing of input sequences and capturing long-distance dependencies more effectively than previous architectures. This innovation paved the way for the development of large-scale pretrained language models like BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and subsequently, BART (Bidirectional and Auto-Regressive Transformers).
Models like facebook/bart-large-mnli are particularly well-suited for zero-shot classification because they have been pre-trained on vast datasets for tasks like Masked Language Modeling and Text Infilling, developing a robust understanding of grammar, syntax, and semantics. Crucially, many of these models, including BART-large-MNLI, are further fine-tuned on NLI datasets like Multi-Genre Natural Language Inference (MNLI). The MNLI dataset consists of pairs of sentences labeled with relationships of entailment, contradiction, or neutrality. By training on such datasets, these models learn to discern logical relationships between statements, a skill directly transferable to evaluating how well a text supports a given label hypothesis. This deep understanding of textual relationships is what empowers them to perform classification without explicit prior training on the target labels.
Practical Implementation: Engaging with a Zero-Shot Classifier
Leveraging zero-shot classification in practice has been significantly streamlined by open-source libraries like Hugging Face’s Transformers. These libraries provide high-level APIs, such as the pipeline function, that abstract away the complexities of model loading, tokenization, and inference, making it accessible even for those without deep machine learning expertise.
To begin, one typically installs the necessary Python libraries:
pip install torch transformersOnce installed, loading a pretrained zero-shot classification model is straightforward:
from transformers import pipeline
classifier = pipeline(
"zero-shot-classification",
model="facebook/bart-large-mnli"
)This initializes a classifier object ready to process text. The facebook/bart-large-mnli model, due to its NLI training, is a popular and effective choice for this task.
A Simple Classification Example:
Consider a scenario where a user wants to categorize a news headline:
text = "This tutorial explains how transformer models are used in NLP."
candidate_labels = ["technology", "health", "sports", "finance"]
result = classifier(text, candidate_labels)
print(f"Top prediction: result['labels'][0] (result['scores'][0]:.2%)")The output, typically "Top prediction: technology (96.52%)", demonstrates the model’s ability to accurately identify the most relevant category based on the semantic content of the sentence, without ever being explicitly trained on "technology" as a label for this specific type of text.
Handling Multi-Label Scenarios:
Many real-world texts belong to multiple categories simultaneously. Zero-shot classification pipelines can accommodate this through the multi_label=True parameter. This instructs the model to evaluate each label independently, rather than forcing a single best choice.
text = "The company launched a health app and announced strong business growth."
candidate_labels = ["technology", "healthcare", "business", "travel"]
result = classifier(
text,
candidate_labels,
multi_label=True
)
threshold = 0.50 # Define a confidence threshold for inclusion
top_labels = [
(label, score)
for label, score in zip(result["labels"], result["scores"])
if score >= threshold
]
print("Top labels:", ", ".join(f"label (score:.2%)" for label, score in top_labels))The output, such as "Top labels: healthcare (99.41%), technology (99.06%), business (98.15%)", illustrates how the model can assign high confidence scores to multiple relevant categories, accurately reflecting the multifaceted nature of the input text. This functionality is invaluable for tasks like tagging articles, content recommendation, or comprehensive document analysis where a single label might not suffice.
Optimizing with Custom Hypothesis Templates:
The performance of zero-shot classification can often be fine-tuned by customizing the "hypothesis template." This template dictates how candidate labels are transformed into natural language statements for the model to evaluate. While a default template like "This text is about ." is often used, a more specific or contextually relevant template can significantly improve accuracy, especially for niche domains or highly specific labels.
text = "The user cannot access their account and keeps seeing a login error."
candidate_labels = ["technical support", "billing issue", "feature request"]
result = classifier(
text,
candidate_labels,
hypothesis_template="This customer message indicates a ."
)
for label, score in zip(result["labels"], result["scores"]):
print(f"label: score:.4f")By using a template like "This customer message indicates a .", the model is given a clearer context for evaluation, leading to more precise semantic matching. In this example, "technical support" would likely receive the highest score (e.g., 0.7349), demonstrating the power of tailored phrasing. This emphasizes that the "wording matters" not just for labels, but for the very structure of the query presented to the model.
Real-World Applications and Industry Impact
The agility and effectiveness of zero-shot text classification translate into tangible benefits across numerous industries:
- Customer Service and Support: Companies can rapidly classify incoming customer emails, chat messages, or support tickets into categories like "refund request," "product inquiry," "technical issue," or "account update." This enables efficient routing to the appropriate department, significantly reducing response times and improving customer satisfaction. A major e-commerce platform, for instance, could deploy a zero-shot classifier within hours to categorize new types of product complaints as they emerge, without waiting for weeks of manual labeling and model retraining.
- Content Moderation: In the fight against misinformation, hate speech, and inappropriate content, social media platforms and online communities can use zero-shot models to identify emerging harmful categories. As new forms of abusive language or trending topics arise, moderators can quickly define new labels like "misinformation about X" or "hate speech targeting Y" and apply the classifier, dramatically accelerating detection and removal efforts.
- Market Research and Feedback Analysis: Analyzing vast amounts of customer reviews, survey responses, and social media sentiment becomes more dynamic. Marketers can quickly gauge reactions to new product features or campaigns by classifying free-text feedback into "positive feature X," "negative performance Y," or "suggestion Z," without pre-training for every potential new product or issue.
- Legal and Compliance: In legal tech, zero-shot classification can assist in categorizing legal documents, identifying relevant clauses, or flagging documents related to specific legal precedents or regulations. This accelerates document review processes, saving countless hours for legal professionals.
- Healthcare and Life Sciences: Researchers can classify medical literature, patient notes, or clinical trial data into specific disease categories, treatment types, or adverse event reports, facilitating faster knowledge discovery and data organization.
- News and Media: News organizations can automatically categorize articles into hyper-specific topics, enriching their recommendation engines or internal content management systems, without the need for extensive manual tagging or retraining for every new current event.
The ability to deploy classification models rapidly, adapt to evolving label sets, and operate without the overhead of massive labeled datasets marks a significant operational advantage, fostering innovation and responsiveness in data-driven decision-making.
Challenges and Considerations
While zero-shot classification offers immense advantages, it is not without its limitations and considerations:
- Reliance on Pretrained Knowledge: The performance of a zero-shot model is inherently tied to the quality and breadth of its pre-training data. If a specific domain or concept was underrepresented in the original training corpus, the model might struggle with labels related to that domain.
- Ambiguity and Nuance: Highly ambiguous texts or labels that require very specific, domain-expert knowledge can still pose challenges. For instance, distinguishing between highly nuanced legal arguments might still require human intervention or fine-tuning with a small, specialized dataset (few-shot learning).
- Bias in Pretrained Models: Large language models inherit biases present in their training data. This means zero-shot classifiers can exhibit biases in their classifications, potentially leading to unfair or inaccurate outcomes. Careful evaluation and mitigation strategies are crucial, especially in sensitive applications.
- Label Wording is Critical: As demonstrated, the clarity and specificity of candidate labels and hypothesis templates directly impact performance. Vague or poorly defined labels will yield suboptimal results. This necessitates careful "prompt engineering" for labels.
- Computational Resources: While it avoids task-specific training, running large transformer models for inference can still be computationally intensive, especially for high-throughput applications.
For critical, high-stakes applications where maximum accuracy is non-negotiable, zero-shot classification might serve as an excellent first pass or a rapid prototyping tool, potentially followed by targeted fine-tuning (few-shot or supervised learning) with a smaller, domain-specific dataset. This hybrid approach leverages the best of both worlds: rapid deployment and high accuracy.
The Future Landscape of Zero-Shot NLP
The trajectory of zero-shot classification is firmly upward. Ongoing research is focused on improving the robustness of these models, enhancing their ability to handle even more abstract or specialized labels, and developing techniques to mitigate inherent biases. The synergy between zero-shot learning and other advanced NLP techniques, such as active learning (where the model intelligently queries humans for labels on ambiguous cases) or reinforcement learning, promises even more sophisticated and adaptive systems.
As large language models continue to grow in size and sophistication, their general understanding of the world and language will only deepen, making zero-shot capabilities more powerful and pervasive. We can anticipate more specialized zero-shot models trained on domain-specific corpora, offering even higher precision for fields like medicine or engineering. Furthermore, the integration of zero-shot classification into broader AI platforms and low-code/no-code solutions will democratize access to this technology, enabling a wider range of users to apply advanced text analysis without extensive programming or machine learning expertise.
Conclusion
Zero-shot text classification represents a significant leap forward in our ability to derive insights from the vast ocean of unstructured text. By removing the stringent requirement for task-specific labeled data, it empowers rapid prototyping, flexible adaptation to changing requirements, and efficient deployment across an unprecedented array of applications. The core innovation lies in treating classification as a reasoning problem, leveraging the profound linguistic understanding embedded within pretrained transformer models like facebook/bart-large-mnli. While careful consideration of label design, hypothesis templates, and potential biases remains crucial, the paradigm of zero-shot learning is undoubtedly reshaping the landscape of natural language processing, offering a powerful, agile, and scalable solution for the challenges of text analysis in the modern data-driven world. Its continued evolution promises to unlock even greater efficiencies and deeper understanding from the language that defines our digital age.
