
The escalating demand for highly accurate and verifiable outputs from large language models (LLMs) has led to significant innovations in Retrieval-Augmented Generation (RAG) systems. While conventional RAG architectures, primarily leveraging vector databases, have become foundational for handling vast unstructured text, a critical limitation persists: their inherent "lossiness" when dealing with atomic facts, numerical data, and precise entity relationships. This article explores a groundbreaking approach to constructing a deterministic, multi-tier RAG system that integrates knowledge graphs and vector databases, fundamentally reshaping how LLMs access and synthesize information with unparalleled precision.
Addressing the Limitations of Vector-Based RAG
For years, vector databases have served as the bedrock of modern RAG pipelines, excelling at retrieving semantically similar long-form text. By converting text into numerical embeddings, these databases enable efficient similarity searches, allowing LLMs to draw upon external knowledge beyond their training data. However, this strength becomes a weakness when precise factual recall is paramount. Semantic similarity, by its nature, is probabilistic and can easily lead to misinterpretations or "hallucinations" regarding specific facts. For instance, a standard vector RAG system might conflate a basketball player’s current team with past affiliations if multiple team names appear in proximity within the latent space. This ambiguity poses a significant challenge for applications where absolute factual accuracy, such as in legal, medical, or financial domains, is non-negotiable.
The industry’s recognition of this challenge has spurred the development of more robust, federated architectures capable of distinguishing between different types of information and applying context-specific retrieval strategies. The core problem lies in the inability of a single retrieval mechanism to handle both the nuanced, fuzzy context of long-form text and the rigid, undeniable certainty of atomic facts. This dual requirement necessitates a multi-index approach, where different data types are stored and retrieved using methods optimized for their unique characteristics.
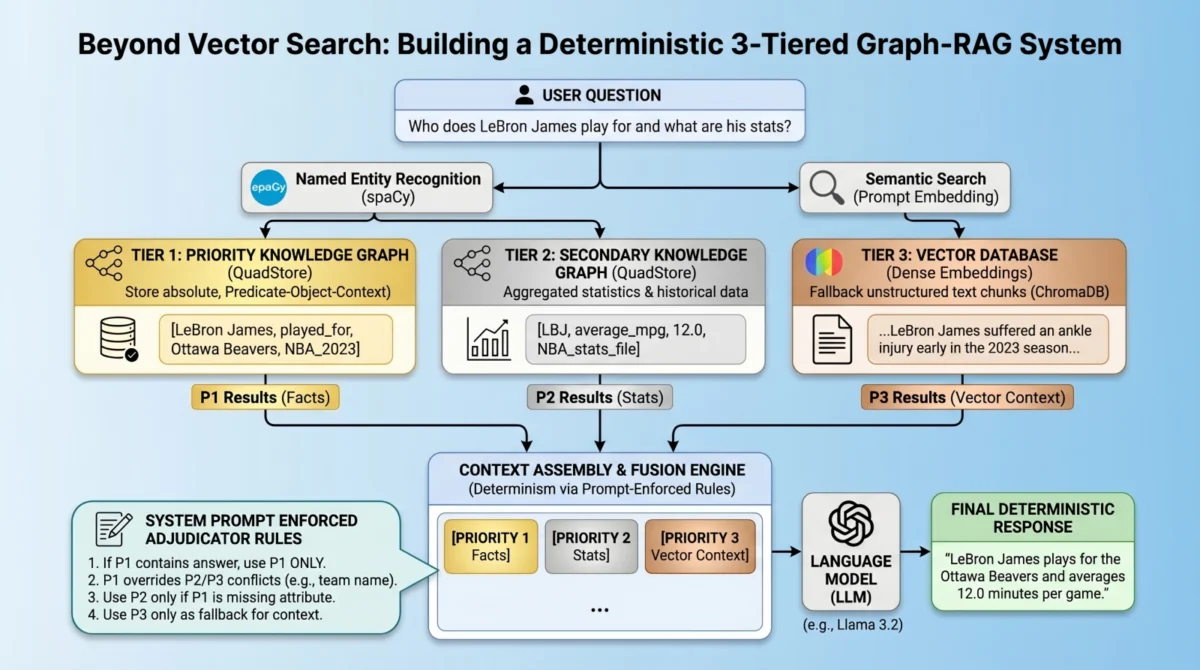
A Multi-Index, Federated Architecture: The 3-Tiered Hierarchy
To overcome the limitations of purely vector-based systems, a novel multi-tiered architecture has emerged, designed to enforce strict data hierarchy and ensure deterministic retrieval. This system prioritizes information based on its inherent factual solidity, channeling queries through distinct layers to resolve conflicts and provide precise answers. The architecture comprises three primary retrieval tiers:
- Priority 1: Absolute Graph Facts (Knowledge Graph for Atomic Truths): This tier serves as the ultimate arbiter of truth, storing atomic facts and immutable relationships within a knowledge graph. It is optimized for precise, constant-time lookups of entities, attributes, and their definitive connections.
- Priority 2: Background Statistics and Numerical Data (Knowledge Graph for Contextual Numbers): Complementing Priority 1, this tier also utilizes a knowledge graph but focuses on broader statistics, numerical data, and less rigid relationships. While still structured, it provides supplementary information that can be cross-referenced or used when Priority 1 lacks specific details.
- Priority 3: Vector Documents (Vector Database for Long-Tail, Fuzzy Context): This layer functions as the traditional vector database, storing and retrieving unstructured text chunks based on semantic similarity. It captures the "long-tail" of information, providing comprehensive contextual data that might not fit neatly into a structured knowledge graph.
Crucially, this architecture departs from complex algorithmic routing mechanisms to select the "right" database for a query. Instead, it adopts a more radical, yet practically effective, strategy: query all relevant databases simultaneously, aggregate their results into the LLM’s context window, and then employ prompt-enforced fusion rules to guide the LLM in deterministically resolving conflicts and synthesizing a coherent, accurate response. This approach aims to virtually eliminate relationship hallucinations, establishing absolute deterministic predictability for atomic facts.
Laying the Foundation: Environment and Prerequisites
Implementing such a sophisticated system requires a carefully configured environment. Python serves as the primary development language, leveraging its extensive ecosystem of data science and machine learning libraries. A local LLM infrastructure, such as Ollama running a model like llama3.2, is essential for processing queries and generating responses locally, ensuring privacy and control over the inference process. Key Python libraries include chromadb for vector database operations, spacy for advanced natural language processing tasks like Named Entity Recognition (NER), and requests for API interactions with the local LLM. The quadstore module, a lightweight Python implementation of an in-memory knowledge graph, is also a core component, often integrated by manually downloading it from its repository and placing it in the local file system. This choice prioritizes simplicity and speed over the complexities of full-fledged graph databases like Neo4j or ArangoDB for specific use cases. The complete project code, providing a comprehensive blueprint, is typically made available on platforms like GitHub for community access and replication.
Step 1: Building the Lightweight QuadStore – The Knowledge Graph Backbone
The foundation for Priority 1 and Priority 2 data lies in a custom, lightweight in-memory knowledge graph, specifically a quad store. Unlike semantic embeddings that capture meaning through numerical vectors, this knowledge graph operates on a strict node-edge-node schema, internally referred to as a SPOC (Subject-Predicate-Object plus Context). Each "quad" represents a single, undeniable piece of information: a subject performing a predicate on an object within a given context.
The QuadStore module is designed as a highly-indexed storage engine. Under the hood, it efficiently maps all strings to integer IDs, preventing memory bloat and enabling rapid data retrieval. It maintains a four-way dictionary index (spoc, pocs, ocsp, cspo), guaranteeing constant-time lookups across any dimension—whether querying by subject, predicate, object, or context. This design allows for extremely fast retrieval of specific facts, a critical requirement for deterministic RAG.
The decision to use this simple, custom implementation instead of more robust, enterprise-grade graph databases like Neo4j or ArangoDB is driven by practical considerations: simplicity and speed. For this specific use case, where the focus is on deterministic retrieval of specific facts rather than complex graph analytics or massive-scale storage, a lightweight solution offers significant advantages in terms of ease of understanding, integration, and operational overhead. Developers can interact with the QuadStore through a straightforward API, primarily using methods like add to insert new quads and query to retrieve them based on specified components (subject, predicate, object, context).
To illustrate, initializing the facts_qs (Priority 1) involves adding quads directly: facts_qs.add("LeBron James", "played_for", "Ottawa Beavers", "NBA_2023_regular_season"). Similarly, Priority 2, which handles broader statistics, can be populated either directly or by importing from structured files, such as JSONLines, derived from datasets like NBA regular season statistics. This dual graph structure ensures that both absolute truths and supporting numerical data are precisely cataloged.
Step 2: Integrating the Vector Database – The Contextual Layer
The third tier of our hierarchy, Priority 3, integrates a standard dense vector database, typically ChromaDB, to capture the extensive, unstructured text that rigid knowledge graphs might omit. This layer is crucial for providing the broader context and narrative elements that enrich the LLM’s understanding beyond mere facts.
Initializing a persistent collection in ChromaDB involves specifying a storage path and then either retrieving an existing collection or creating a new one. Once established, raw text chunks are ingested into the database. For example, documents detailing player injuries or team performance narratives are embedded and stored. These text chunks serve as the fallback mechanism, capturing nuanced information that doesn’t fit the SPOC structure of the knowledge graphs but is vital for comprehensive query responses. This hybrid approach ensures that the system can answer both direct factual questions and broader contextual inquiries, bridging the gap between precise data points and rich narratives.
Step 3: Entity Extraction and Global Retrieval – Bridging the Gap
The ability to query deterministic graphs and semantic vectors simultaneously is a cornerstone of this architecture. This is achieved by bridging the gap between unstructured natural language queries and structured data stores through Named Entity Recognition (NER) powered by spaCy.
When a user submits a prompt, the spaCy NLP model first extracts key entities (e.g., "LeBron James," "Ottawa Beavers") in near constant time. These extracted entities then serve as strict lookup keys for parallel queries fired off to both QuadStores (Priority 1 and Priority 2). Concurrently, the original prompt content is used for a string similarity search within ChromaDB (Priority 3).
The extract_entities function leverages spaCy to identify and deduplicate named entities from the input text, providing a clean list of subjects and objects to query. The get_facts function then uses these entities to perform precise lookups across the QuadStores, retrieving all relevant quads where an entity appears as either a subject or an object. This parallel retrieval strategy ensures that all potential sources of information—absolute facts, background statistics, and unstructured context—are consulted for every query. The output of this stage consists of three distinct streams: facts_p1, facts_p2, and vec_info, representing the retrieved context from each priority tier.
Step 4: Prompt-Enforced Conflict Resolution – The Adjudication Layer
Perhaps the most innovative aspect of this system is its approach to conflict resolution. Traditional methods often rely on complex algorithmic techniques like Reciprocal Rank Fusion, which can struggle to adjudicate between granular facts and broad textual context. This architecture adopts a radically simpler yet highly effective strategy: embedding a comprehensive ruleset directly into the system prompt.
By assembling the retrieved knowledge into explicitly labeled blocks—[PRIORITY 1 - ABSOLUTE GRAPH FACTS], [PRIORITY 2: Background Statistics], and [PRIORITY 3 - VECTOR DOCUMENTS]—the language model is given explicit instructions on how to prioritize information and resolve conflicts. The system prompt serves as an "adjudicator," providing a clear hierarchy for decision-making:
- Priority 1 (Facts) takes absolute precedence. If it provides a direct answer, no other information from lower tiers should be used for that specific attribute.
- Priority 2 (Statistics) is supplementary. It can be used only if Priority 1 has no relevant answer. Crucially, any potential contradictions with Priority 1 (e.g., team abbreviations) must be ignored in favor of Priority 1’s definitive statements.
- Priority 3 (Vector Chunks) offers additional relevant information, and the LLM is instructed to use its judgment on whether to include it, but always subservient to Priority 1 and 2 for factual claims.
- If no section contains the answer, the LLM must explicitly state its lack of information, preventing hallucination.
This prompt engineering approach is far more robust than generic instructions to "avoid mistakes." It provides the LLM with ground truth atomic facts, potentially conflicting "less fresh" facts, and semantically similar vector search results, along with an explicit, deterministic hierarchy for adjudicating between them. While no system is entirely foolproof, this method significantly enhances the predictability and accuracy of responses, particularly for factual queries.
Tying It All Together: Practical Demonstrations and Performance Insights
The main execution thread of the RAG system orchestrates the entire process: extracting entities, querying all three data sources in parallel, constructing the meticulously structured system prompt, and finally, submitting it to the local LLM instance via its REST API. The system’s effectiveness is best illustrated through practical queries:
-
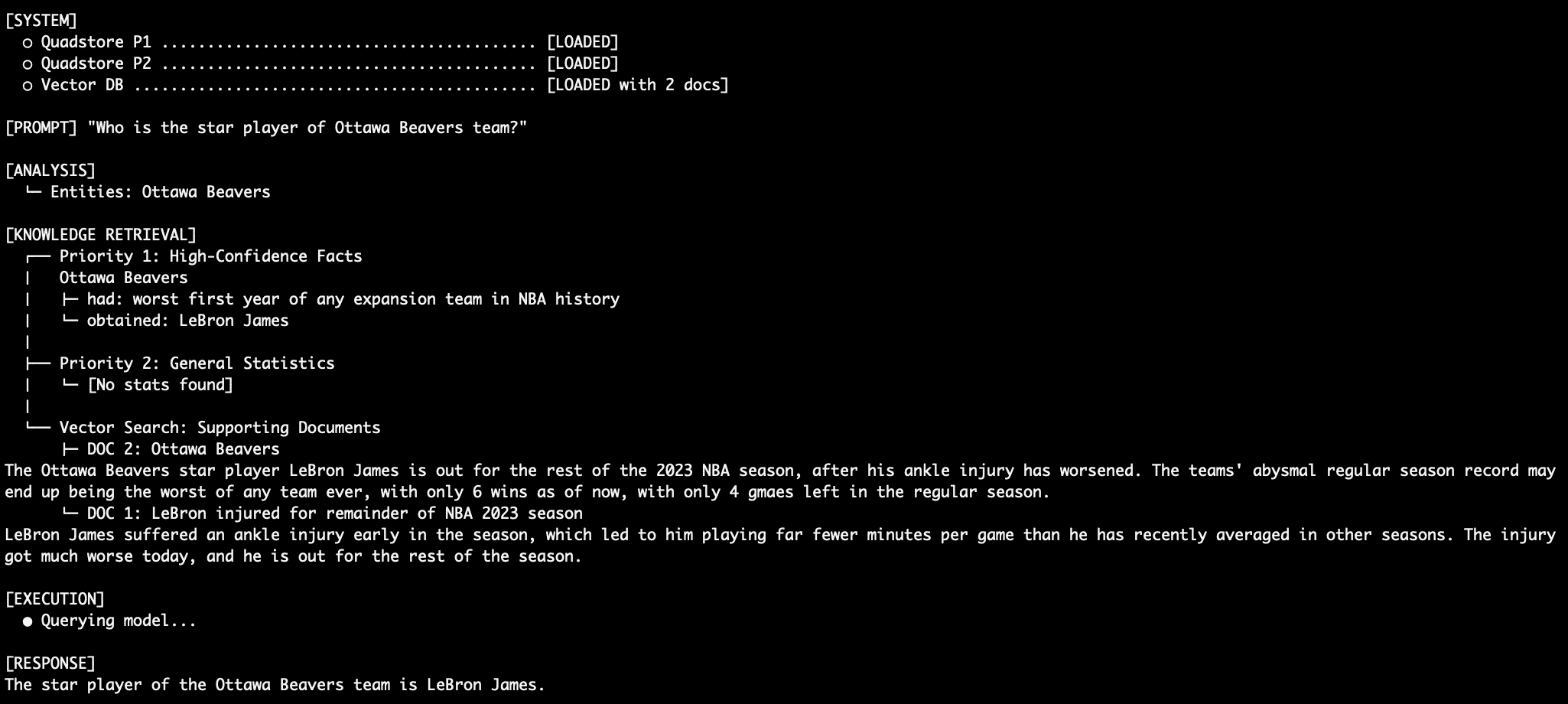
Query 1: Factual Retrieval with the QuadStore ("Who is the star player of Ottawa Beavers team?")
When asked about an absolute fact, the system relies entirely on Priority 1. Because Priority 1 explicitly states, "In NBA_2023_regular_season, Ottawa Beavers obtained LeBron James," the prompt instructs the LLM to use only this information, overriding any potentially conflicting information from vector documents or statistical abbreviations. This directly combats the traditional RAG relationship hallucination, where an LLM might incorrectly associate LeBron James with a real-world team like the LA Lakers, despite the factual graph stating otherwise. The vector database documents may also support this claim with articles about LeBron’s tenure with the fictional Ottawa team, reinforcing the correct information. -
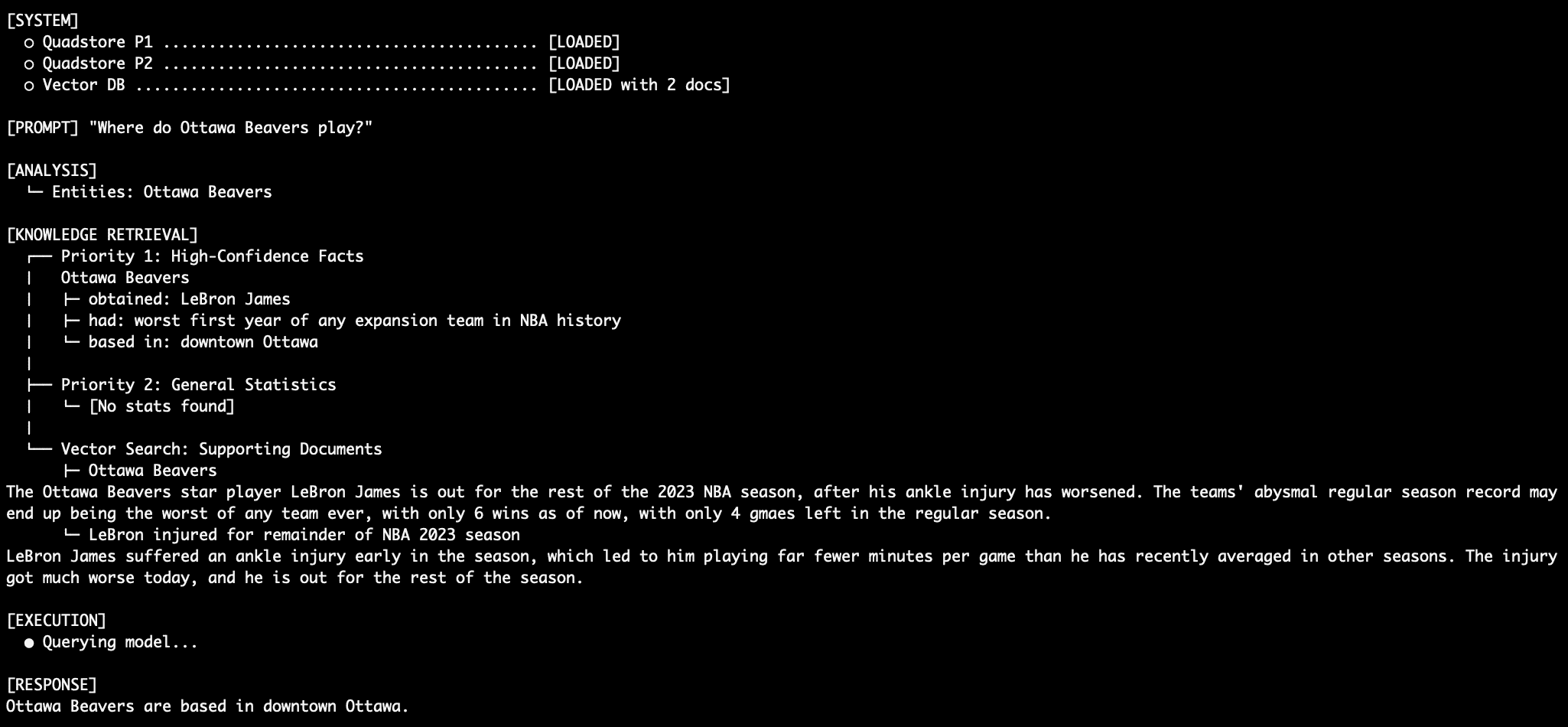
Query 2: More Factual Retrieval ("Where, exactly, in the city are they based?")
Even for questions about fictional entities like the "Ottawa Beavers," Priority 1 facts provide the definitive answer: "In NBA_trivia, Ottawa Beavers based in downtown Ottawa." This demonstrates the system’s ability to maintain a consistent internal reality, even when conflicting with the LLM’s general knowledge or other data sources. The robustness here is evident as the model is forced to ignore its training data and the absence of the Beavers in the general NBA stats. -
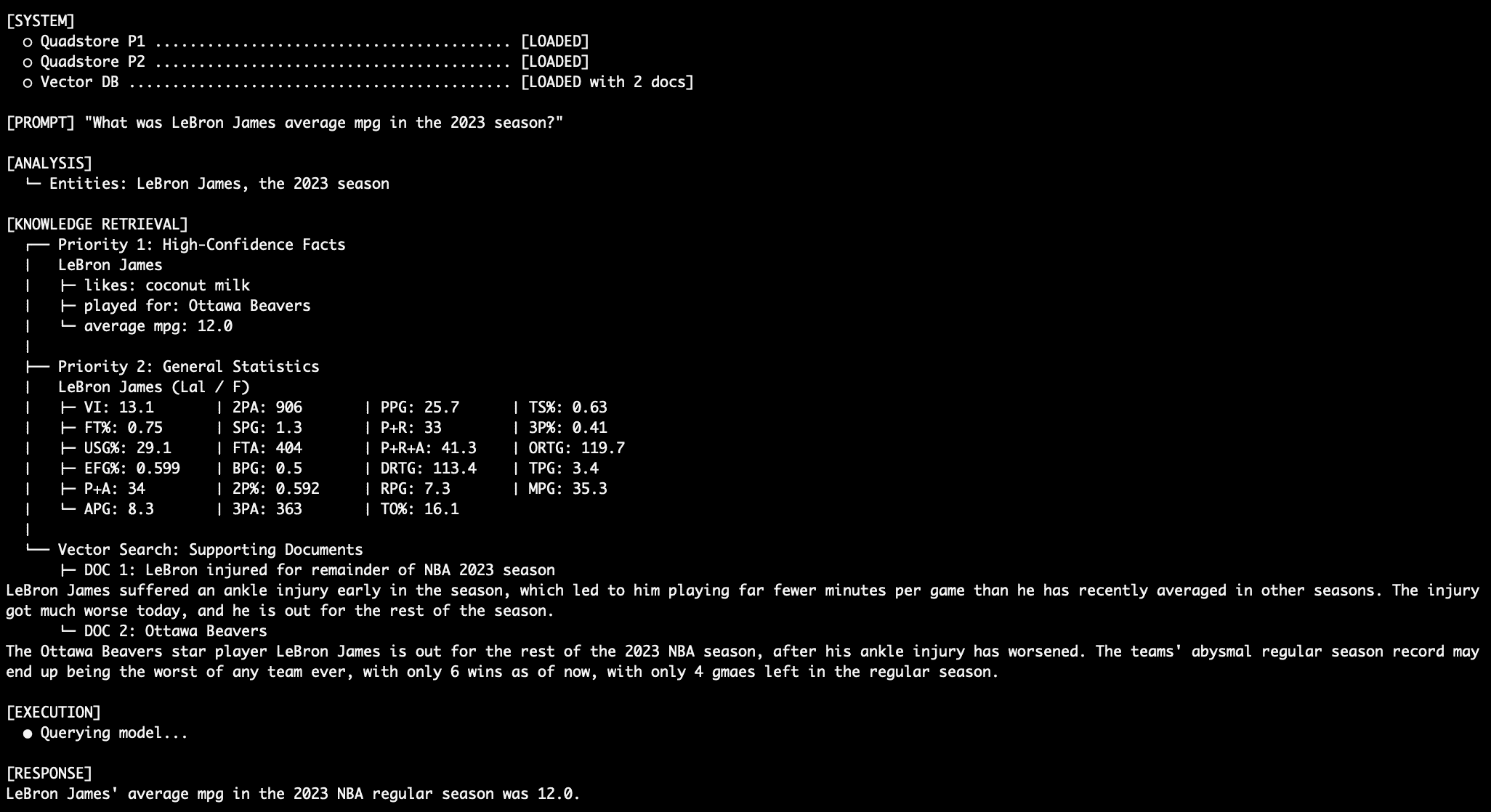
Query 3: Dealing with Conflict ("What was LeBron James’ average MPG in the 2023 NBA season?")
This query highlights the hierarchy’s strength. If both Priority 1 and Priority 2 contain information about LeBron James’ average minutes per game (MPG), the model must defer to Priority 1. For instance, if Priority 1 states "In NBA_2023_regular_season, LeBron James average_mpg 12.0," this will override any different value found in the Priority 2 general statistics graph. This ensures that the most authoritative data source prevails for critical numerical facts. -
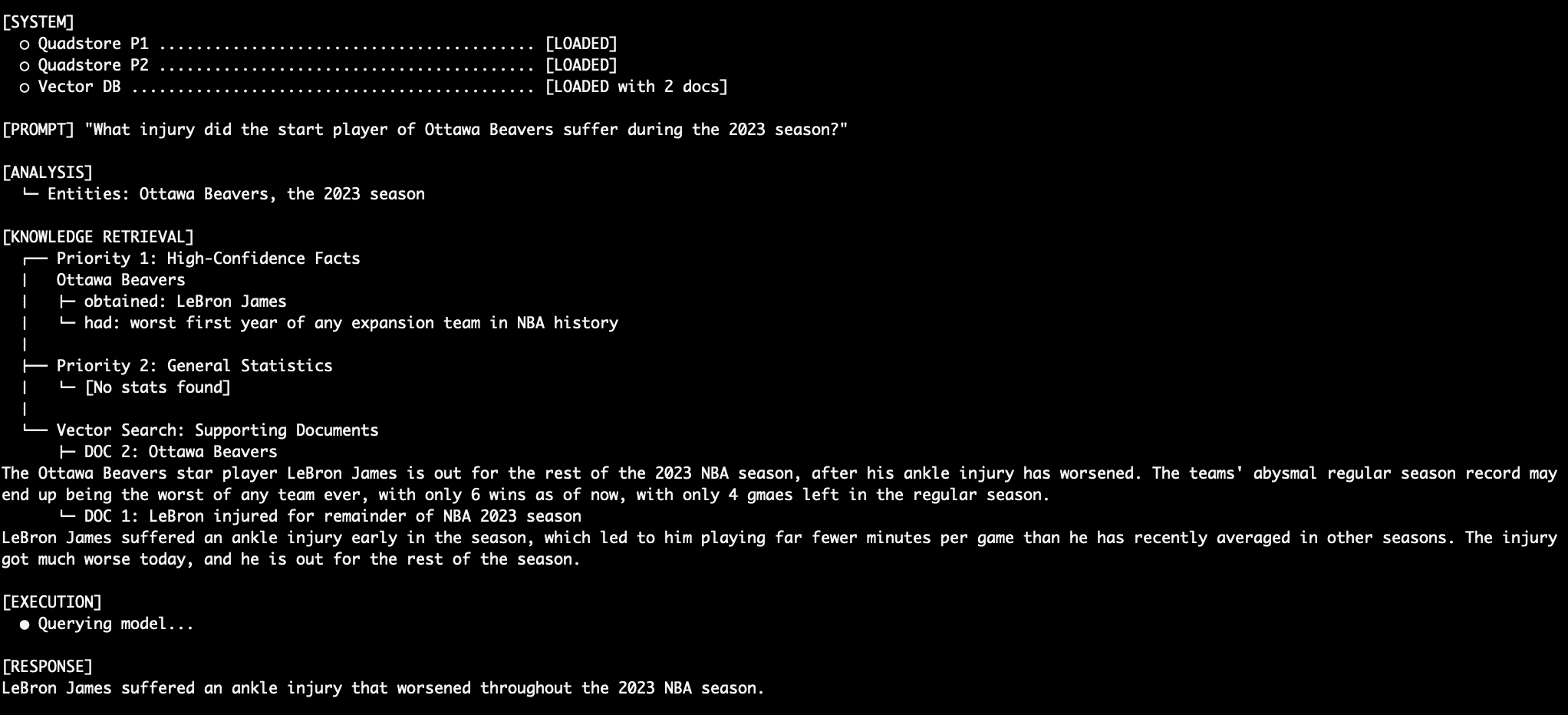
Query 4: Stitching Together a Robust Response ("What injury did the Ottawa Beavers star suffer during the 2023 season?")
For unstructured questions requiring synthesized information, the system seamlessly integrates data from multiple tiers. First, Priority 1 identifies "LeBron James" as the "Ottawa Beavers star player." Then, Priority 3 (vector documents) provides details about "LeBron James suffered an ankle injury early in the season." The LLM, guided by the prompt rules, merges these pieces of information into a coherent and accurate final response, demonstrating its ability to combine precise facts with contextual narratives. -
Query 5: Another Robust Response ("How many wins did the team that LeBron James play for have when he left the season?")
This complex query again showcases the multi-level data integration. Priority 1 confirms LeBron’s team. Priority 3 documents reveal the team’s abysmal record, stating "The teams’ abysmal regular season record may end up being the worst of any team ever, with only 6 wins as of now, with only 4 gmaes left in the regular season." The LLM skillfully extracts and combines these details, delivering a comprehensive answer that would be prone to hallucination in a less structured RAG system. It is particularly noteworthy that this deterministic behavior is achieved even with a relatively simple language model likellama3.2:3b, which has only 3 billion parameters, demonstrating the power of external knowledge management over raw model size for factual accuracy.
Conclusion and Strategic Implications
The deployment of a multi-tiered factual hierarchy alongside a vector database, coupled with precise prompt engineering for conflict resolution, marks a significant advancement in the quest for highly reliable RAG systems. This architectural paradigm drastically reduces factual hallucinations and minimizes competition between otherwise equally true, but contextually conflicting, pieces of data.
Advantages of this approach include:
- Enhanced Factual Accuracy: By prioritizing absolute facts stored in knowledge graphs, the system delivers responses with a significantly higher degree of factual precision.
- Reduced Hallucination: The explicit prompt-enforced rules for conflict resolution dramatically curb the LLM’s tendency to generate incorrect or misleading information, especially for atomic facts and relationships.
- Deterministic Predictability: For critical data points, the system offers predictable and consistent answers, which is vital for applications in highly regulated or sensitive domains.
- Improved Trustworthiness: By providing verifiable and accurate information, the system builds greater trust in LLM-generated outputs, encouraging broader adoption in enterprise settings.
- Efficient Information Retrieval: Combining precise graph lookups with flexible vector searches ensures comprehensive coverage for both structured and unstructured queries.
- Scalability for Diverse Data: The modular design allows for independent scaling and management of different data types, optimizing storage and retrieval for each.
Trade-offs of this approach include:
- Increased System Complexity: Managing multiple databases (knowledge graphs and vector databases) introduces additional architectural and operational overhead compared to a single vector store.
- Data Management and Ingestion Effort: Populating and maintaining accurate knowledge graphs requires meticulous data curation, schema design, and potentially more complex ingestion pipelines.
- Higher Initial Setup Cost: The development and integration of distinct data layers, along with sophisticated prompt engineering, demand greater upfront investment in time and expertise.
- Potential for Prompt Length Constraints: Including all retrieved context and detailed rules within the system prompt can lead to longer prompts, potentially hitting context window limits for very large retrievals or smaller LLMs.
- Dependence on NER Quality: The effectiveness of entity extraction directly impacts the ability to query the knowledge graphs accurately. Errors in NER can lead to missed facts.
- Performance Overhead: Querying multiple databases in parallel and processing potentially larger context windows can introduce latency, although optimized implementations strive to minimize this.
For environments where high precision, low tolerance for errors, and verifiable outputs are paramount—such as in legal research, clinical decision support, financial analysis, or advanced technical documentation—deploying a multi-tiered factual hierarchy alongside a vector database may indeed be the critical differentiator between a promising prototype and a production-ready, trustworthy AI solution. This approach represents a strategic pivot towards building more reliable and accountable AI systems, pushing the boundaries of what RAG can achieve in an increasingly data-driven world.
